【知识储备】
1.shell脚本文件的后缀业内都默认为sh,所以以后看到以sh结尾的文件名称基本上就是shell脚本。
2.在写shell脚本的时候,标准开头就是
#!/bin/bash
3.shell脚本写完以后要加执行权限
chmod +x shell脚本名称
4.执行shell脚本有很多种方式
(1)./shell脚本名称
(2)sh shell脚本名称 ##注意这种执行方式,即使不加执行权限也可以执行
(3)shell脚本的全路径 直接回车,也可以执行
5.shell脚本也可以debug
(1)在 sh执行命令后加 -x 即 是 sh -x shell脚本名称
(2)在shell脚本里边的#!/bin/bash的后边 加上 -x 也可以
【案例一】
echo的作用:打印输出
1@编辑内容
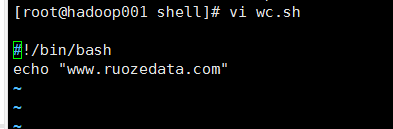
2@输出结果

【案例二】
变量定义和引用
1@编辑内容

2@输出结果
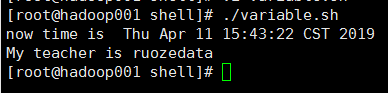
3@总结
(1)反引号的里边引用的内容一定要是一个命令,用反引号定义的变量是动态变量
(2)引用变量用$,变量要放在{}里边(其实不放也可以,为了规范,为了不跳坑要加大括号)
(3)K=V 'V' "V" 这种加单引号,双引号或者啥也不加的变量叫静态变量
(4)变量定义的=号前后不能有空格(大坑)
【案例三】
传递参数
1@编辑内容
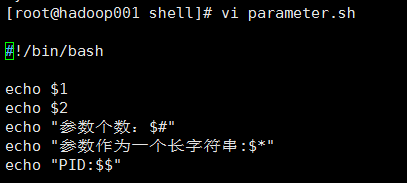
2@输出结果
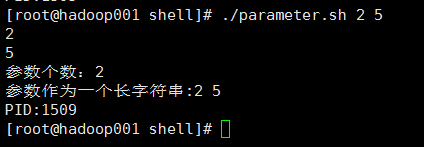
3@总结
(1)$# 这个程式的参数个数
(2)$* 这个程式的所有参数,此选项参数可超过9个。
(3)$$ 这个程式的PID(脚本运行的当前进程ID号)
(4)$1 和 $2 是需要输入的参数,$1代表第一个参数,$2代表第二个参数,参数之间的间隔用空格键
4@拓展
$0 这个程式的执行名字
$n 这个程式的第n个参数值,n=1..9
$! 执行上一个背景指令的PID(后台运行的最后一个进程的进程ID号)
$? 执行上一个指令的返回值 (显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误)
$- 显示shell使用的当前选项,与set命令功能相同
$@ 跟$*类似,但是可以当作数组用
【案例4】
数组
1@编辑内容
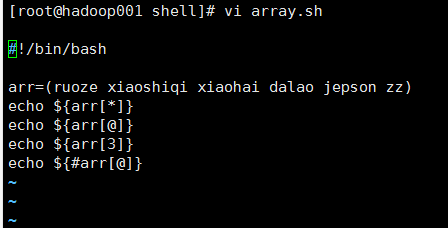
2@输出结果
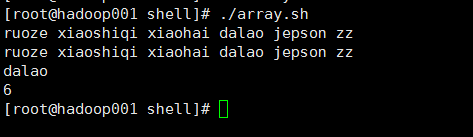
3@总结
(1)shell中的数组只支持一维的
(2) arr[@]和arr[*]都代表数组的全部内容
(3)arr[数字] 打印输出的是对应数组里的内容,注意,数组里的下标是从零开始的
(4) #arr[@] 打印输出的是数组内元素的个数
(5)数组内元素之间的间隔是用空格分开的,这个在shell中式默认的
【案例5】
if判断
1@编辑内容
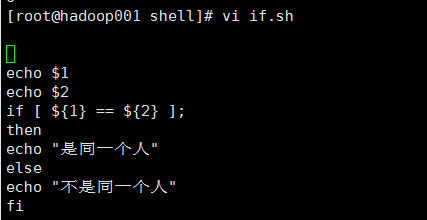
2@输出结果

3@总结
基本的if条件命令选项有:
- eq —比较两个参数是否相等(例如,if [ 2 –eq 5 ])
-ne —比较两个参数是否不相等
-lt —参数1是否小于参数2
-le —参数1是否小于等于参数2
-gt —参数1是否大于参数2
-ge —参数1是否大于等于参数2
-f — 检查某文件是否存在(例如,if [ -f "filename" ])
-d — 检查目录是否存在
几乎所有的判断都可以用这些比较运算符实现。
脚本中常用-f命令选项在执行某一文件之前检查它是否存在。
str1 = str2 当两个字符串有相同内容、长度时为真
str1 != str2 当字符串str1和str2不等时为真
-n str1 当字符串的长度大于0时为真(串非空)
-z str1 当字符串的长度为0时为真(空串)
【案例6】
循环
1@编辑内容 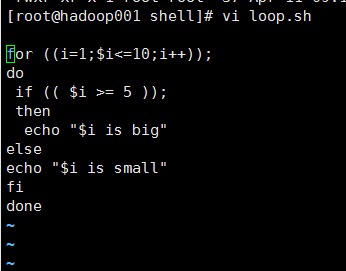
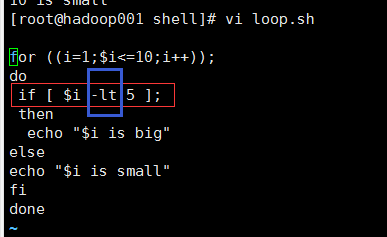
2@输出结果
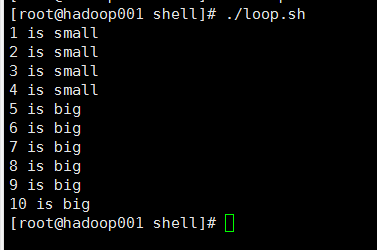
3@总结
(1)在比较大小的时候if (( $i >= 5 )); 这里如果用数学符号,<,=,或者>等等要用双括号把条件扩起来
(2)如果用- eq、-ne等这种,要用中括号扩起来[]
(3)循环的种类比较多,后期会有补充
【案例7】
分割
1@编辑内容
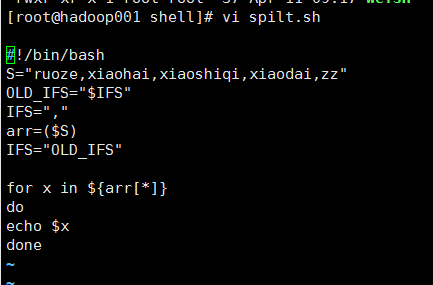
2@输出结果
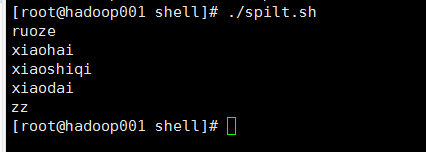
3@总结
(1)OLD_IFS="$IFS"
IFS="," --分割符号是逗号
arr=($S) --把S这个字符串变量转换成数组
IFS="OLD_IFS"
这里代码OLD_IFS="$IFS", IFS="OLD_IFS" 这里是固定的,不需问为什么
(2)注意这里的循环就是用了for X in (一组数字),这里是用的数组的形式
【案例8】
取数
1@编辑测试log
2@awk命令输出结果

【案例9】
替换
1@编辑测试log
2@sed命令输出结果
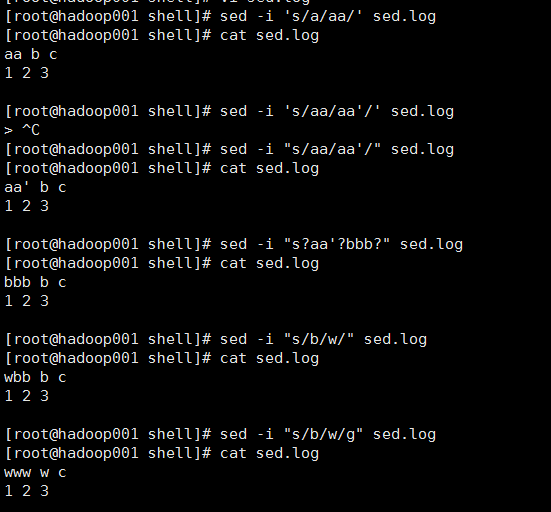
3@总结
[root@hadoop001 shell]# sed -i 's/a/aa/' sed.log
[root@hadoop001 shell]# cat sed.log
aa b c
1 2 3
[root@hadoop001 shell]# sed -i 's/aa/aa'/' sed.log
> ^C
[root@hadoop001 shell]# sed -i "s/aa/aa'/" sed.log
[root@hadoop001 shell]#
[root@hadoop001 shell]#
[root@hadoop001 shell]# cat sed.log
aa' b c
1 2 3
[root@hadoop001 shell]# sed -i "s?aa'?bbb?" sed.log
[root@hadoop001 shell]# cat sed.log
bbb b c
1 2 3
[root@hadoop001 shell]# sed -i "s/b/w/" sed.log
[root@hadoop001 shell]# cat sed.log
wbb b c
1 2 3
[root@hadoop001 shell]# vi sed.log
bbb b c
1 2 3
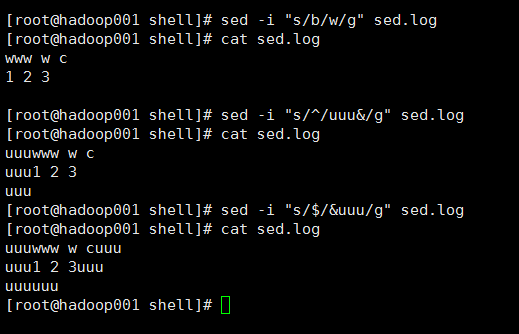
全局替换
[root@hadoop001 shell]# sed -i "s/b/w/g" sed.log
[root@hadoop001 shell]# cat sed.log
www w c
1 2 3
前面加
[root@hadoop001 shell]# sed -i "s/^/uuu&/g" sed.log
[root@hadoop001 shell]# cat sed.log
uuuwww w c
uuu1 2 3
后面加
[root@hadoop001 shell]# sed -i "s/$/&uuu/g" sed.log
[root@hadoop001 shell]#
[root@hadoop001 shell]# cat sed.log
uuuwww w cuuu
uuu1 2 3uuu
大数据压缩格式详解
https://www.cnblogs.com/yurunmiao/p/4528499.html