spark中的shuffle
shuffle简介
shuffle是将数据重新分配 的过程,它是跨分区的,涉及网络IO传输的,成本很高。他是整个大数据的性能杀手,瓶颈所在,故生产中尽量较少有shuffle动作的产生。
spark shuffle 演进的历史
spark0.8及以前Hash Based Shuffle
Spark0.8.1为Hash Based Shuffle引入File Consolidation机制
Spark0.9引入ExternalAppendOnlyMap
Spark0.9引入ExternalAppendOnlyMap
Spark1.1引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
Spark1.2默认的shuffle方式Sort Based Shuffle
Spark1.4引入Tungsten-sort Based Shuffle
Spark1.6 Tungsten-sort并入Sort Based Shuffle
Spark2.0 Hash Based Shuffle 退出历史舞台
总结:
就是最开始的时候使用的是Hash Based Shuffle,这时候每个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数据量是MR,其中M是map的个数,R是Reduce的个数。这样会产生大量的小文件,对文件系统压力很大,而且也也不利于IO吞吐量。后面就做了优化,把在同一个core上运行的多个Mapper输出的合并到同一个文件,这样文件数目就变成了core R个了
废话不多说上图
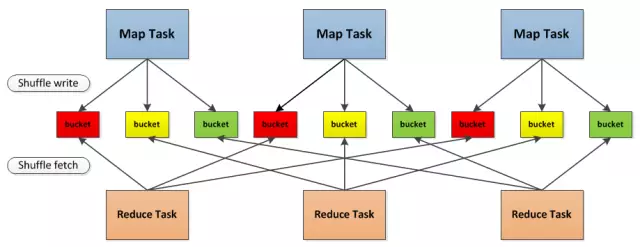
最开始使用的Hash Based Shuffle会根据reduce的数量,每个map产生和reduce个数一样多的bucket,从上图可以看出,有3个map有3个reduce,这样就会产生9个小文件,那如果更多地Map和更多地Reduce,在这种情况下,机器很难抗住
在引入File Consolidation机制之前,如果有4个task和4个map,那就会产生16个小文件
但是现在这4个map task分2批运行在2个core上,这样只会产生8个小文件
但是但是现在这 4个 map task 分两批运行在 2个core上, 这样只会产生 8个小文件
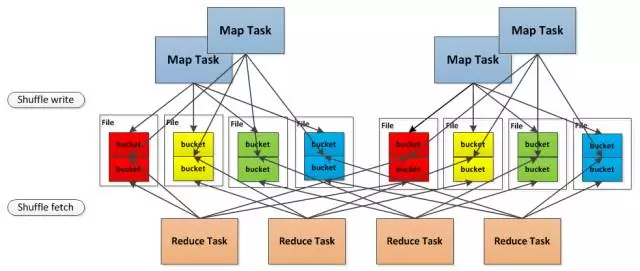
在同一个core上线后运行的2个map task的输出,对应同一个文件的不同的segment上,称为一个FileSegment,形成一个ShuffleBlockFile,后面就引入了Sort Based Shuffle ,map 端的任务会按照Partition id 以及key对记录进行排序。同时将全部结果写到一个数据文件中,同时生成一个索引文件,在后面就引入了Tungsten-Sort Based Shuffle,这个是直接使用堆外内存和新的内存管理模型,节省了内存空间和大量的gc,是为了提升性能。
在同一个 core 上先后运行的两个 map task的输出, 对应同一个文件的不同的 segment上, 称为一个 FileSegment, 形成一个 ShuffleBlockFile,
后面就引入了 Sort Based Shuffle, map端的任务会按照Partition id以及key对记录进行排序。同时将全部结果写到一个数据文件中,同时生成一个索引文件, 再后面就就引入了 Tungsten-Sort Based Shuffle, 这个是直接使用堆外内存和新的内存管理模型,节省了内存空间和大量的gc, 是为了提升性能。
spark的监控程序(spark monitor)
Web UI给我们提供了非常方便的监控界面,但是不同的监控方式会有不同的效果
spark UI
参考博客:https://www.cnblogs.com/itboys/p/9201750.html