Java 使用 Kafka 发布信息与消费消息
在Java中操作kafka相对于mysql数据库来说更加的简单。一篇文章看懂Java操作kafka
第一步 引入依赖
由于我们一般使用kafka都是在spring中使用,所以我就直接引入spring的kafka作为演示
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.4.RELEASE</version>
</dependency>
第二步 生产者
代码简单易懂就不啰嗦了。
package kafkaTest;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.Random;
public class Kafka生产者 {
public static String TOPIC = "topic_opt_conf";//定义主题
public static void main(String[] args) throws InterruptedException {
//简单的配置信息
Properties p = new Properties();
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.214:9092");//kafka地址,多个地址用逗号分割
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p);
try {
//开始愉快的发消息
for (int i = 0; i < 100; i++) {
String msg = "test," + new Random().nextInt(100);
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC, msg);
kafkaProducer.send(record);
System.out.println("消息发送成功:" + msg);
Thread.sleep(500);
}
} finally {
kafkaProducer.close();
}
}
}
执行结果如下:
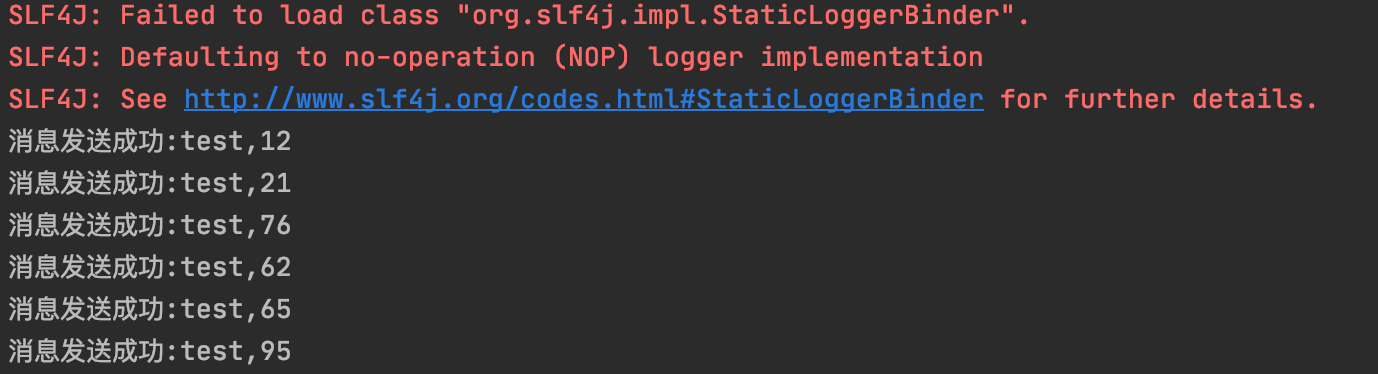
报错信息不用管,那个是没有配置日志的错误,不影响我们发消息。
第三步 消费者
package kafkaTest;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.Properties;
public class Kafka消费者 {
public static String topic = "topic_opt_conf";
public static void main(String[] args) {
//简单的配置信息
Properties p = new Properties();
p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.214:9092");
p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
p.put(ConsumerConfig.GROUP_ID_CONFIG, "xxw_tbs_group"); //注意消费者这里是GROUP_ID 不是TOPIC不要写错了
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(p);
kafkaConsumer.subscribe(Collections.singletonList(topic));// 订阅消息
while (true) {
//当有新消息时,就会收到消息并输出
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("topic:%s,offset:%d,消息:%s", //
record.topic(), record.offset(), record.value()));
}
}
}
}
日志报错信息不用管,但是迟迟没有收到消息?那就吧发送消息的那个程序运行起来,你就能看见这里开始消费消息了。
执行结果如下:
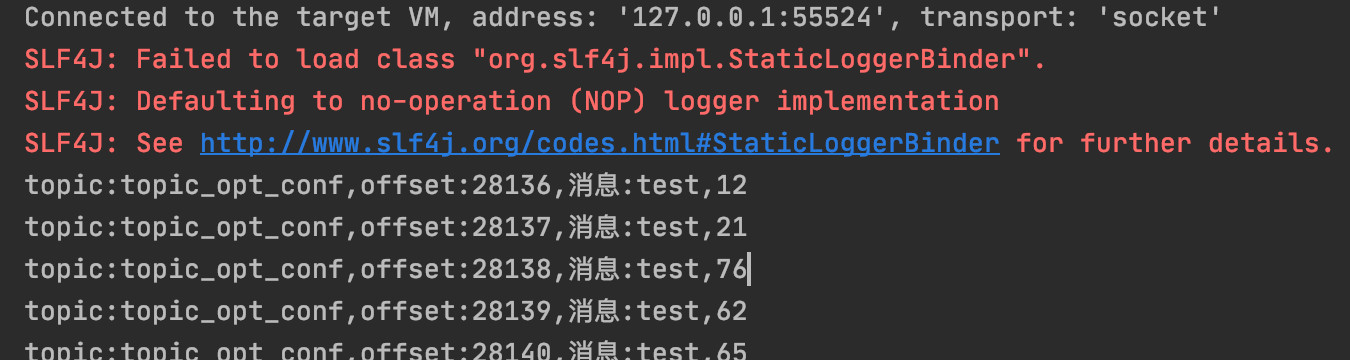
注意:
1.kafka如果是集群,多个地址用逗号分割(,)
2.Properties的put方法,第一个参数可以是字符串,如:p.put("bootstrap.servers","192.168.23.76:9092")
3.kafkaProducer.send(record)可以通过返回的Future来判断是否已经发送到kafka,增强消息的可靠性。同时也可以使用send的第二个参数来回调,通过回调判断是否发送成功。
4.p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);设置序列化类,可以写类的全路径
5.订阅消息可以订阅多个主题
6.ConsumerConfig.GROUP_ID_CONFIG表示消费者的分组,kafka根据分组名称判断是不是同一组消费者,同一组消费者去消费一个主题的数据的时候,数据将在这一组消费者上面轮询。
7.主题涉及到分区的概念,同一组消费者的个数不能大于分区数。因为:一个分区只能被同一群组的一个消费者消费。出现分区小于消费者个数的时候,可以动态增加分区。
8.注意和生产者的对比,Properties中的key和value是反序列化,而生产者是序列化。