第九章:查找
静态查找表:
1.顺序表的查找:顺序查找
从后往前找,0单元设置哨兵
存储形式是顺序表或者是线性链表
查找算法的平均查找长度= 查找成功时的平均查找长度+查找不成功时的平均查找长度
则顺序查找的不成功长度:每个元素不成功的长度都是(n+1),即每次不成功实际上都是跟关键字比较了(n+1)次
顺序查找的平均查找长度是:3*(n+1)/4
有序表的查找:折半查找
限于顺序存储结构,且是有序表
low的初始值为1,零单元设哨兵,high为序列的长度
查找成功的平均查找长度是:

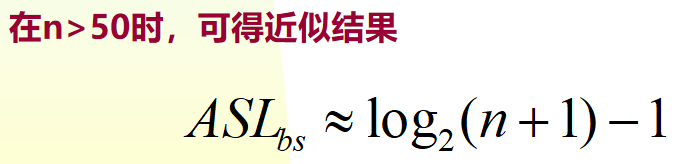
3.索引顺序表查找:分块查找
索引顺序查找又称分块查找(是顺序查找的一种改进方法),除表本身外需建立一个索引表,内容包括关键字项和指针项。
鼓
动态查找表:
表结构本身是在查找过程中动态生成的。对于给定值key,若表中存在其关键字等于key的记录,则查找成功返回,否则插入关键字等于key的记录。
1.二叉排序树:
二叉排序树或者是一棵空树;或者是具有如下特性的二叉树:
(1)若它的左子树不空,则左子树上所有结点的值均小于根结点的值;
(2)若它的右子树不空,则右子树上所有结点的值均大于根结点的值;
(3)它的左、右子树也都分别是二叉排序树。
用二叉链表来存储,即每个结点包含数据、左右孩子结点指针域
中序遍历该二叉排序树即可得到从小到大的有序序列!


2.平衡二叉树:
平衡二叉树又称AVL树,它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。
定义平衡因子:平衡因子=|左子树深度-右子树深度|《1
平均查找长度:
它的深度和log2 n是同数量级的, 由此,它的平均查找长度 也和log2 n 同数量级。
查找的时间复杂度:O(logn)
查找小窍门:
假设由于在二叉排序树上插入结点而失去平衡的最小子树根结点的指针为a,即a是离插入点最近且平衡因子绝对值超过1的祖先结点:
将离插入点最近且从0变到绝对值为1的点移到a的位置。
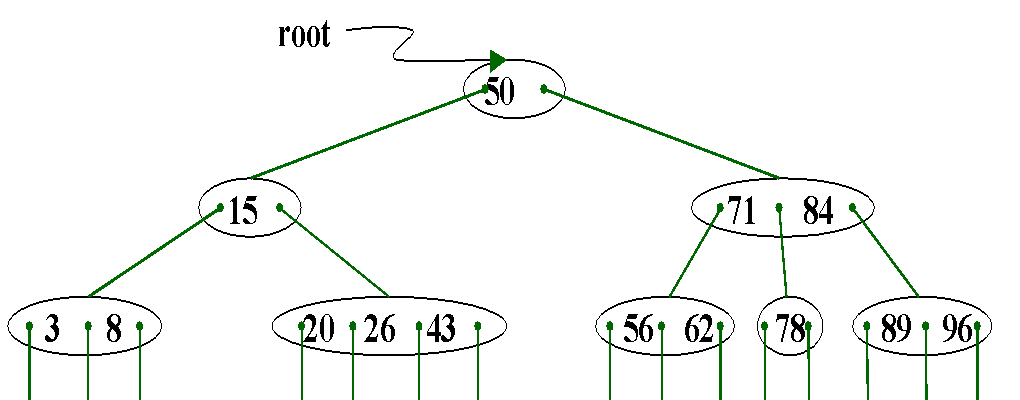
3.B-树:
B-读作:B树,而不是B减树! 即B树和B-树其实就是一个东西,B+树才是另外一种东西


(此处图片来源为https://www.e-learn.cn/content/qita/2465295,不用做商用仅用于自己学习总结)
B-树的特征如下:
一棵m阶的B-树,或为空树,或为满足下列特性的m叉树:
(1) 所有的非终端结点中包含下列信息数据 (n,A0,K1, A1,K2,A2,…, Kn,An) 其中:n—关键字个数(「m/2]-1<=n<=m-1). Ki(i=1,2,…,n): 关键字,且ki<ki+1(i=1,2,…,n-1); Ai(i=1,2,…,n): 指向子树根结点的指针,且指针Ai-1所指子树中所有结点的关键字均小于ki(i=1,2,…,n-1), Ai+1所指子树中所有结点的关键字均大于ki.
(2) 树中每个结点至多有m棵子树,即结点中的关键字个数<=m-1;
(3) 若根结点不是叶子结点,则至少有两棵子树;
(4) 除根之外的所有非终端结点至少有m/2(往上取)棵子树;
(5)所有的叶子结点都出现在同一层次上,并且不带信息。
B-树在文件系统中很有用,是大型数据库文件的一种组织结构。
B-树查找效率主要取决于B-树的深度

若当前树中含有 N 个关键字,则叶子结点必为 N+1 个
插入关键字的算法:




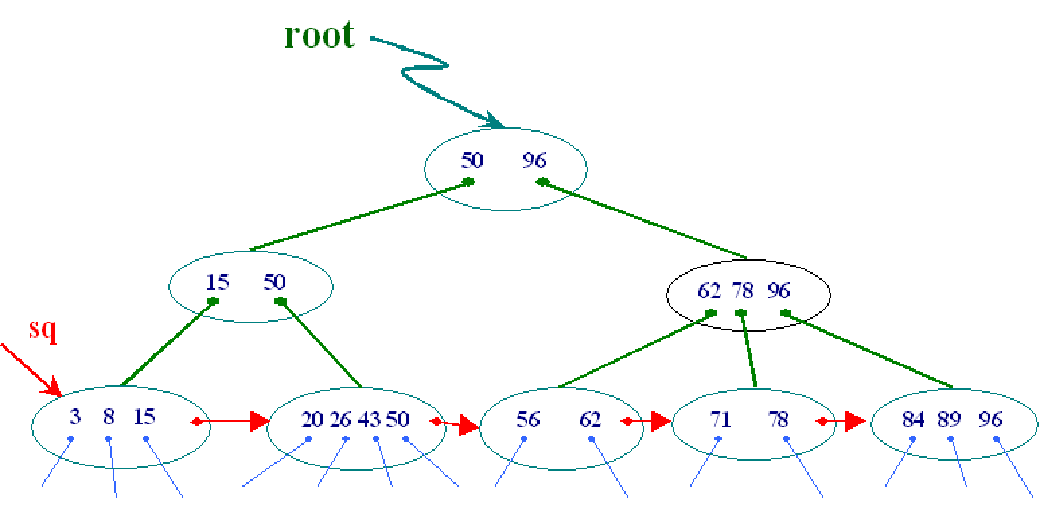
4.B+树:
B+树和B树的区别:
(1)在B-树中,有n棵子树的结点中有n-1个关键字,而在B+树,有n棵子树的结点中有n个关键字;
(2) B+树比B-树多一层叶子结点,所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小从小而大顺序链接.
(3)在B-树中,每个非叶子结点中的关键字满足大于相邻左指针所指子树中所有结点的关键字,小于相邻右指针所指子树中所有结点的关键字;
而在B+树中,每个非叶子结点中关键字和一个指针对应,这些关键字和对应的指针满足该关键字是对应指针所指子树中所有关键字的最大值. 所有的非终端结点可以看成是索引部分,结点中仅含有其子树(根结点)中的最大(或最小)关键字。
同一个序列,B-树长这样:
B+树长这样:
5.哈希表:
解决冲突的办法:



哈希表的查找:
用开放定址法解决冲突(即除了链地址法的冲突解决办法)
哈希表分析:
α=n/m 值的大小(n—记录数,m—表的长度) α越大,添入表中的元素较多,产生冲突的可能性就越大;α越小,添入表中的元素较少,产生冲突的可能性就越小。
哈希表查找成功和失败的平均查找长度:
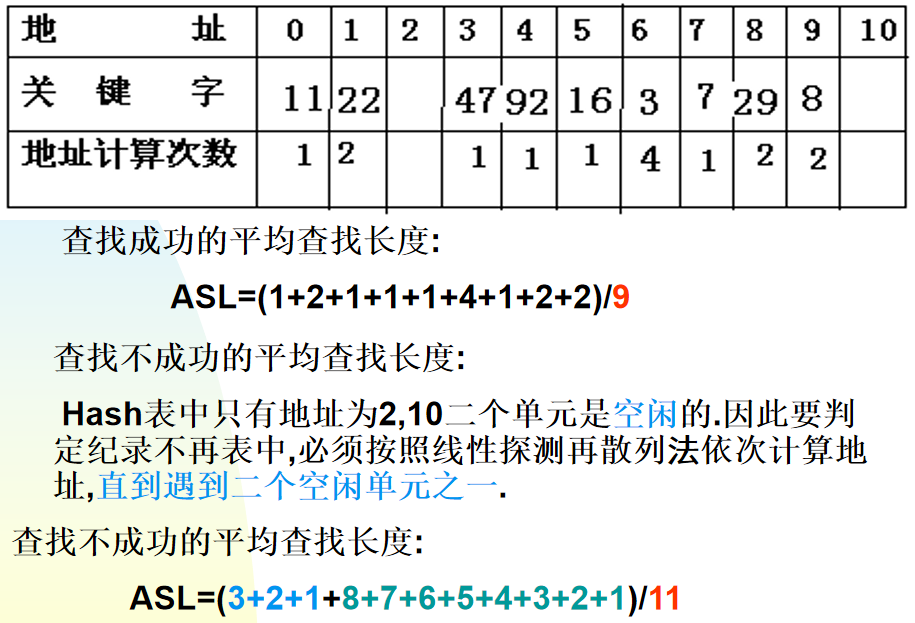
线性探测在散列在处理冲突的过程中易产生记录的二次聚集,而链地址法处理冲突时不会发生类似情况,故其平均查找长度较优。

查找成功有如下结果:

由此可知,平均查找长度跟n无关而是跟装填因子a有关。
用哈希表构造查找表时,可以选择一个适当的装填因子 a ,使得平均查找长度限定在某个范围内。
装填因子:a=表中填入的记录数/哈希表的长度。a越大,表示冲突出现的可能性越高,a越小,表示冲突出现的可能性越小。