一、前言 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。 Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。node.js现在已经成为前端工程师的必备技能。
本节涉及的基础内容:
1. node中的javascript
2.http服务能力
3.文件操作能力
一、知识
1、打开cmd窗口的三种方式
方式一:传统的cmd cd到我们要操作的目录
方式二:shift + 鼠标右键,选择快速打开窗口命令
方式三:如果你的电脑装了git 选中要操作的项目 --》右击--》git bash here
2、使用node来解析和执行文件
第一步:用编辑器建立脚本文件
第二步:使用上面的方式定义到项目目录
第三步:在cmd框中输入 node + project.js 执行node文件(这里的文件名不能起做node.js,最好不要含有中文)
3、node.js中的javascript
(1)node中没有BOM、DOM
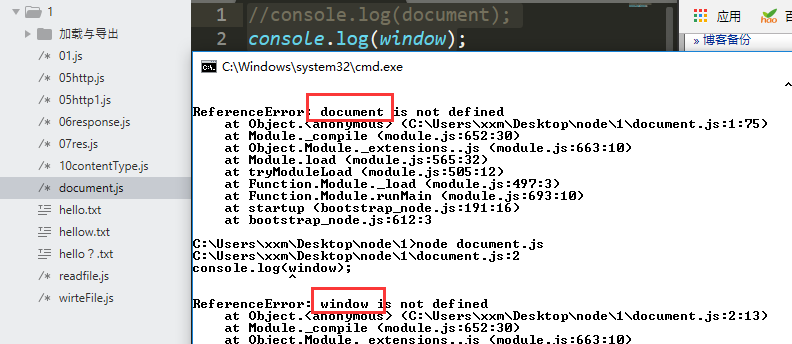
验证:在你的工程目录下新建js文件---》打开当前的命令提示框---》执行node 文件 ,说明node里面并没有BOM、DOM
console.log(document);
console.log(window)
(2)node中包含一些基本的EcmaScript基本的语言
比如:变量,方法,数据类型,内置对象,Array, Object, Date, 等
可以参考:http://www.w3school.com.cn/js/index.asp
(3)一些核心模块如:FS(文件操作)
4、node中的文件操作能力
在node中如果想要对文件进行操作就必须引入FS核心模块,核心模块中提供了文件操作相关的API
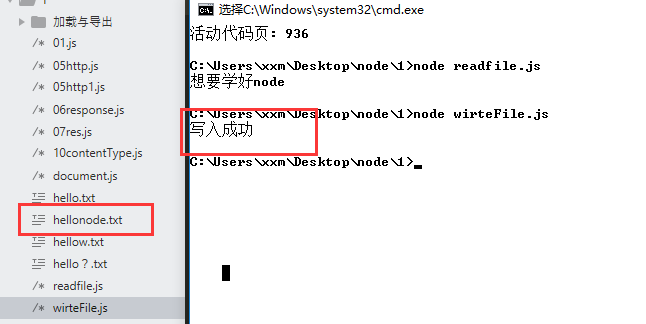
读取文件:readFile(第一个参数,第二个参数) 第一个参数:是读取的文件路径 ,第二个参数:是一个回调函数
在目录下建一个文本文件和一个js文件
1)

2)
//第一步:用require来加载核心模块 var fs=require('fs'); //第二步:调用这个API fs.readFile('hello.txt',function(error,data){ console.log(error); //读取成功返回null, console.log(data); })
3)执行文件

我们发现当读取成功的时候,error返回的是null data中返回的是用十六进制输出的数据,为什么是十六进制的数据呢?是因为计算机只认识二进制的,但是没有找到二进制数据,就将我们的文本内容转化为16进制
接下来:用toString()来转化
//第一步:用require来加载核心模块 var fs=require('fs'); //第二步:调用这个API fs.readFile('hello.txt',function(error,data){ if(error){ console.log('读取失败'); }else{ console.log(data.toString()); } })

小提示:如果发现命令提示符输出的中文为乱码,可以百度搜索解决 https://jingyan.baidu.com/article/fcb5aff775f3e3edaa4a71dd.html
写入文件:fs.writeFile(第一个参数,第二个参数,第三个参数) 第一个参数:为文件路径,第二个参数为:文件内容,第三个参数为回调函数function(error){}
//第一步:用require引入fs模块 var fs =require('fs'); //第二步:用上面的对象调用API fs.writeFile('./hellonode.txt','想要学好node',function(error){ if(error){ console.log('写入失败'); }else{ console.log('写入成功'); } });
小提示:平时我们保存文件的时候,文件的命名不能有特殊的符号,比如:* / ?之类的
5、node中的http服务
(1) 先了解几个概念:
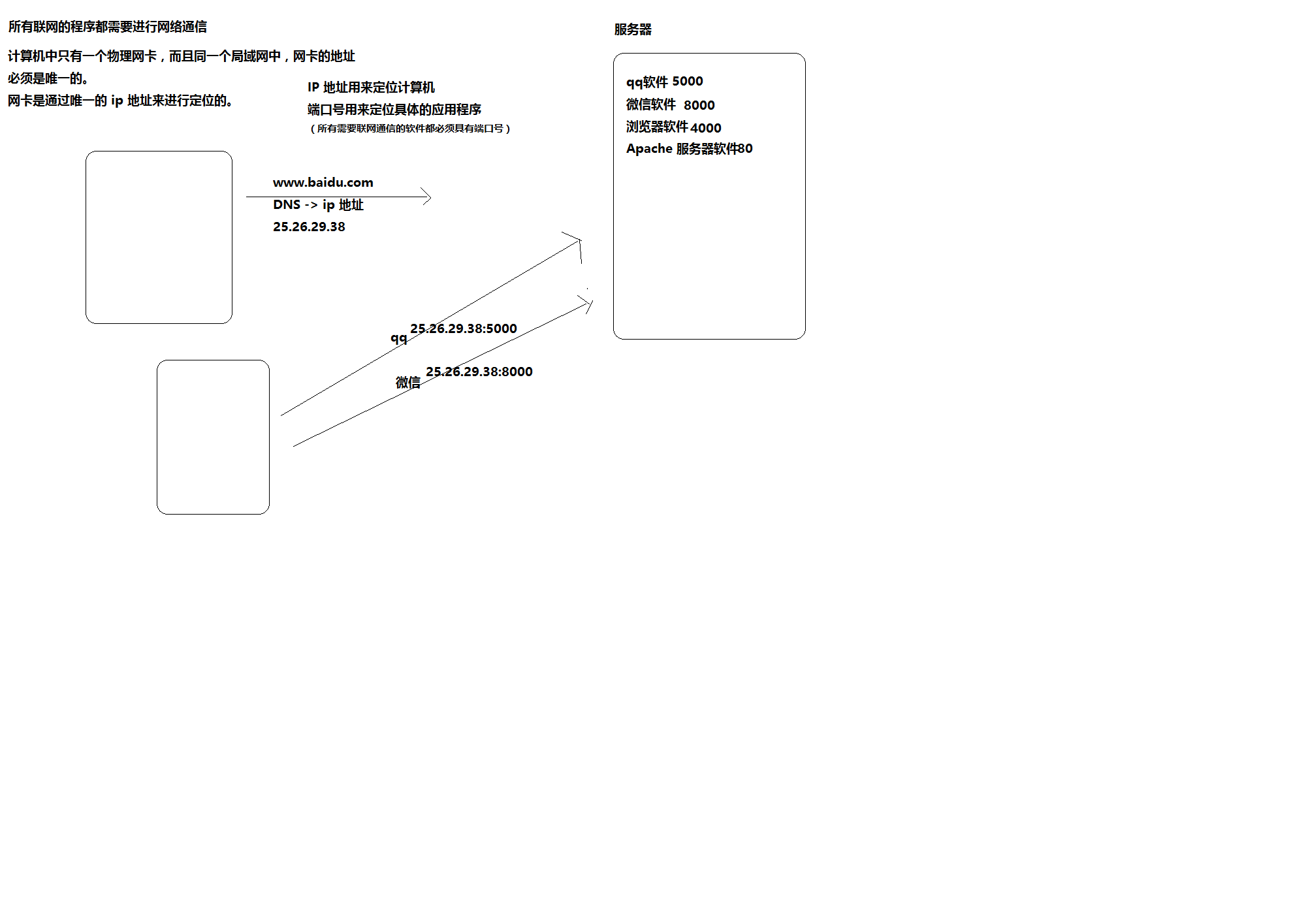
端口号:是用来定位对应的具体程序的,所有需要联网通信的程序都要占用端口号
IP地址:是用来定位计算机的
服务器:提供对数据的服务,发请求,接受请求,给用户一些反馈
还是不理解端口号和IP作用的话引用一个前辈的图来解释:
我们在访问浏览器,用微信,QQ等软件进行通信的时候需要访问服务器,那么服务器就是通过不同软件对应的不同软件来区分接收到的是哪个应用程序的信息。然后在返回给客户端想要的信息。
并且要知道端口号和ip地址才能访问(会不会有疑问我们访问百度的时候没有带端口号呀)?
客户端的浏览器会自动开启端口号,所以只要客户端来请求,服务端就知道客户端端口号
可以同时开启多个服务,但是一定确保不同服务占用端口号不一致
说白了,在一台计算机中,同个端口号,同一时间只能被一个程序使用
(2)使用node来轻松构建一个web服务器
//第一步:加载http核心模块 var http = require('http'); //第二步:调用createServer()方法来创建 var server=http.createServer(); //第三步:注册request事件,当客户端发过来请求之后执行回调函数,对接受的数据进行反馈 server.on('request',function(){ console.log('接受到了客户端的请求,请通过服务端http://localhost:3000访问'); }); //第四步:给我们的服务器设置一个端口号,客户端要知道这个端口号才能访问 server.listen(3000,function(){ console.log('服务启动成功了'); });
启动服务器:

之后浏览器中输入 localhost:3000访问我们的服务器,服务器接受到响应执行回调

web服务器的响应:平时我们访问百度,或者其他网站的时候,会根据输入不同的访问路径返回给客户端不同的信息,那么他们是怎么做的呢?
请求百度:

返回给我们百度首页:
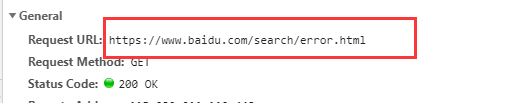
如果找不到输入的路径就会反馈给我们一个错误提示页

所以我们可以知道,服务器就是看这个Request URL来区别用户查找的不同内容,并且给出不同的反馈
优化刚刚的代码,并且用write()函数让浏览器反馈
var http = require('http'); var sever=http.createServer(); sever.on('request',function(request,response){ if(request.url==='/'){ response.write('index js'); }else if(request.url==='/login'){ console.log('登录'); }else{ console.log('404 not found'); } }); sever.listen(3000,function(){ console.log('服务器已经启动'); })
下面通过不同的访问路径来访
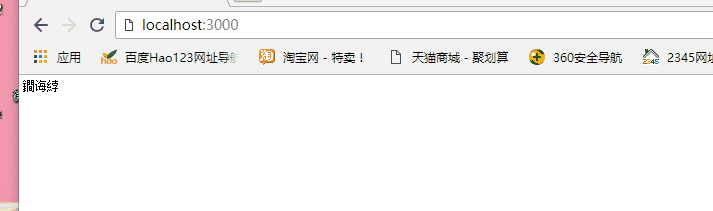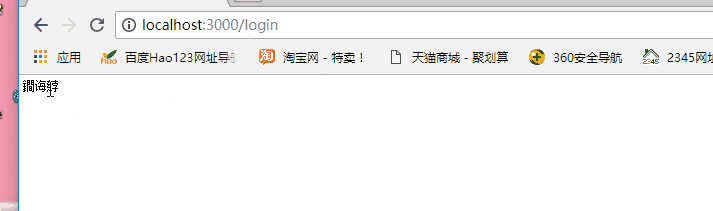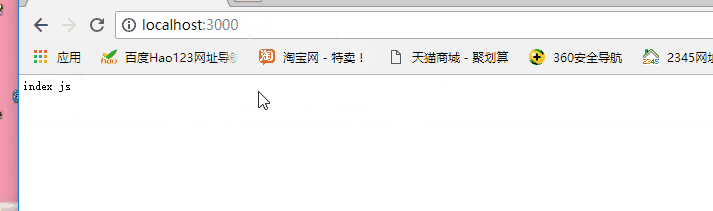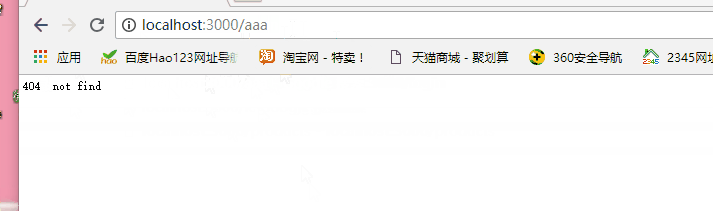
发现上面的中文乱码了,为什么?因为服务器响应的类型只能为二进制和字符串,具体解决方法看下篇: https://www.cnblogs.com/xxm980617/p/10506183.html
一、总结
- Node.js 中的 JavaScript
- 没有 BOM、DOM
- EcmaScript 基本的 JavaScript 语言部分
- 在 Node 中为 JavaScript 提供了一些服务器级别的 API
- 文件操作的能力
- http 服务的能力
- http服务:
- require
- 端口号
- ip 地址定位计算机
- 端口号定位具体的应用程序
- Content-Type
- 服务器最好把每次响应的数据是什么内容类型都告诉客户端,而且要正确的告诉
- 不同的资源对应的 Content-Type 是不一样,具体参照:http://tool.oschina.net/commons
- 对于文本类型的数据,最好都加上编码,目的是为了防止中文解析乱码问题
- 通过网络发送文件
- 发送的并不是文件,本质上来讲发送是文件的内容
- 当浏览器收到服务器响应内容之后,就会根据你的 Content-Type 进行对应的解析处理