innodb data written / read
计算每秒questions
数据库性能变化趋势判断服务器资源是否足够
select benchmark(100000000, 'call mysp()'); #第一个函数调用多少次,第二个函数执行的sql。 注意响应时间
select benchmark(100000000, ‘select 1+1'); #判断服务器性能,做基准测试。然后监控系统监控每秒指标,响应时长。
mysqladmin ext | grep -i trx #判断事物id,percona版本才有,官方版本查看information_schema查看trx信息&innodb status
select * from QUERY_RESPONSE_TIME; percona查看sql区间响应耗时
idle = 100% - %user - %sys - %iowait
iowait越高说明当前IO性能差,io负载高。
真正可用的内存有:free + cached + buffer
IOwait高可能是buffer poll太小导致读盘多,或者没索引走全表扫描。
常用工具:top、free、ps、df、sysstat、(sar、mpstat、iostat)dstatomstaat、netstat、oprofile、systemtap、perf
iotop
sysstat(sar、mpstat、iostat) dstat omstaat iotop
select case when sum(DATA_LENGTH)+sum(INDEX_LENGTH) is NULL then 0 else sum(DATA_LENGTH)+sum(INDEX_LENGTH) end as innodb_tabsize from information_schema.TABLES where TABLE_SCHEMA not in ('information_schema','mysql','performance_schema','test') and ENGINE = 'InnoDB';#统计is库
实际可用内存为buffer/cache + free
释放 swap:swapoff/swapon #负载高容易hang
sar -u #CPU利用率
sar -d #块设备,IO利用率,rd_sec/s wr_sec/s (读写扇区)每个扇区是512字节 ,可计算相应多少字节,可用iotop定位。await,io等待。 svctm本次io响应时间, util使用率ssd不用太担心,机械是串行写入,ssd可并行写入。
sar -r #磁盘利用率 %memused 查看是否平稳。
vmstat:
vmstat -S m 1 #只是内存用兆方式显示,1秒刷新。
r:在运行队列中等待未执行的进程数 。
b:在等待io的进程数 ,不能被中断的进程。
b:在等待io的进程数 ,不能被中断的进程。
 表示正在发生的swap
表示正在发生的swap
bi = block in to mem read from disk,io读
bo = block out from mem write to disk,io写
si = block in to swap in from disk,swap读(单位是block 4kb)
so = block out from swap out to disk,swap写(单位是block 4kb)
swpd列:总的swap
us = %user
sy = %sys
id = %idle #cpu空闲率
wa = %iowait
st = 虚拟机使用的cpu资源
cpu比较高基本是没有索引引起的
iostat -d -x 1
r/s+w/s=iops
await:总的服务时间包括队列时间。通常大于svctm
svctm:服务时间
util:util比较高说明当前io占比高。如果是磁盘阵列,因为可以并行,所以不太靠谱。ssd并行IO更好,每秒一两百m,也不太靠谱。
io不高而svctm,util比较高,说明服务器性能比较差。
avgqu-sz是平均请求队列的长度
iops iowait util #查看io瓶颈
计算机械盘iops 10000转/60s=167(iops),多盘可以并行*盘数*Linux(4kb)
配置最大连接数,如果每个线程配置的cache比较大,内存溢出导致服务不可用。
mysql监控:
1. 每秒活跃DML(sql)数,/事物数/请求数/当前并发连接数/平均响应时长
2.锁:表锁,行锁,锁等待,死锁。#最大行锁时间,发生次数。
3,内存:buffer/cache命中率、内存如果等待释放(如果内存等待释放,mysqld可能需要增加buffer)。
4.事物:事物ID增长,有没有持续稳定增长。unpurged 未清除的历史事物积压有多少。
5.慢查询:平均耗时,平均次数
mysqladmin ext|grep -i 'Innodb_buffer_pool_wait_free'
3个等待事件状态,如果有发生需要关注:
1.Innodb_buffer_pool_wait_free #innodb等待更多的buffer、page释放,比较严重,说明当前buffer使用很厉害,没有空闲。
2.innodb_log_waits #redo log 需要切换,没有足够空间。
3.table_locks_waited #请求表锁的时候没有立刻获得表锁,需要等待。
慢日志,看哪种sql发生最多,优先解决,其次解决耗时最长。
查看mysql状态:
1,show 【full processlist】 #sending data,超过1秒请求数据量太大。
2,show 【global】 status like"handler%" #读随机下一行,发生全表扫描或者全表join, 产生临时表甚至临时文件,发生多少次。
锁监控:
表锁
1.table_locks_immediate #立刻获得的表锁
2.table_locks_waited #发生的请求需要等待
行锁
1.innodb_row_lock_current_waits #当前等待的行锁数量
2.innodb_row_lock_time #从实例启动到当前,请求行锁总耗时
3.innodb_row_lock_time_avg #请求行锁平均耗时
4.innodb_row_lock_time_max #请求行锁最久耗时(ms,可以对此事物加监控)
5.innodb_row_lock_waits #行锁发生次数
show processlist;
copying to tmp table #没有索引(条件链没有合适索引)
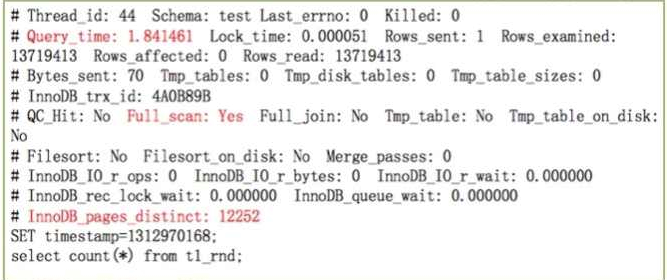
总耗时,是否发生全表扫描,全表join,扫描的数据页有12252
select count(*) 通常优先访问辅助索引。
dstatorzdba.pl #mysql两个不错的监控工具
监控事物ID的增长

这两种表示没有利用索引发生的读
show global status;或者mysqladmin extended-status 缩写、简写模式 mysqladmin ext
Aborted_clients #由于客户端没有正确关闭连接导致客户端终止而中断的连接数。
Binlog_cache_disk_use #无法使用内存保存binlog,需要使用基于磁盘的临时文件次数。
binlog-cache-size #将内存中的binlog写到磁盘之前缓冲,提升写入。如果太小导致比较大的事物无法将binlog内存,会用到磁盘。
Binlog_stmt_cache_disk_use &Binlog_stmt_cache_use #非事务性的用到磁盘文件(以myisam为主)
Created_tmp_disk_tables #用到磁盘表
Binlog_cache_use #使用临时二进制日志缓存的事务数量,越多越好。
Connections #试图连接到(不管是否成功)MySQL 服务器的连接数
Created_tmp_tables #服务器执行语句时自动创建的内存中的临时表的数量。如果 Created_tmp_disk_tables 较大,你可能要增加 tmp_table_size 值使临时表基于内 存而不基于硬盘。
Created_tmp_disk_tables #服务器执行语句时在硬盘上自动创建的临时表的数量。
tmp-table-size & max-heap-table-size #允许在内存里面最大的临时内存是多少。
Created_tmp_disk_tables/(Created_tmp_disk_tables+Created_tmp_tables)*100% #高于10%的话,就需要注意,适当 调高 tmp_table_size ,但是不能设置太大,因为它是每个 session 都会分配的, 可能会导致 OOM
Handler_commit#内部交语句数。
Handler_read_first #索引中第一条记录被读的次数。如果较高,它表明服务器正执行大量全索引扫 ; 例如,SELECT id FROM table,假定 id 有索引。
Handler_read_key #根据索引读取某一行的请求次数,例如:select … where id = 1024;
Handler_read_last #order by倒序读总次数
Handler_read_next #按照索引顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。例如:select * from t where id = 1024 order by id limit 5; 先read-key 然后4条是read-next
Handler_read_prev,例如倒序:select id from t where id = 1024 order by id DESC limit 5;往回读增加4
Handler_read_rnd #根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高,说明可能使用了大量需要MySQL扫描整个表的查询或没有正确使用索引。例如select * from t limit 1000,1; 数据库层面逻辑读
Handler_read_rnd_next #在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值会较高。通常说明你的表索引不正确或写入的查询没有利用索引。例如根据非索引列排序后再读取多少条记录(甚至发生基于磁盘的临时文件进行排序,先从数据库取到数据,再进行二次排序 select * from t order by non_key_col limit 100;
Handler_read_rnd&Handler_read_rnd_next没有利用索引应该重点关注下。
如果怀疑某些SQL效率比较差:
flush status;#先将session 值清空
select xxx; #show status like 'handler_read%';
Innodb_buffer_pool_pages_data #在innodb buffer_pool中有多少个page用来缓存热点数据的,与InnoDB status的Database pages是同一个意思
Innodb_buffer_pool_pages_dirty #表示用来缓存脏页的page 数量
Innodb_buffer_pool_pages_free #没有用到的page数量
Innodb_buffer_pool_pages_total #page总数
Innodb_buffer_pool_read_requests #InnoDB已经完成的逻辑读请求数。(Innodb所有读操作的次数)
Innodb_buffer_pool_reads# 读操作不能从Innodb buffer pool中完成读取,需要从磁盘中读取数据的次数。
Innodb_buffer_pool_wait_free #innodb buffer pool不够用了等待把热点数据或脏页的buffer pool释放次数,该参数大于0比较严重
Innodb_buffer_pool_write_requests #一共发生的写请求次数
Innodb_data_writes #实际物理写次数
Innodb_data_read #从启动到现在已经读取的数据数量(字节)
Innodb_data_written #从启动到现在已经写入的数据量(字节)。
Innodb_log_waits #我们必须等待的时间,因为redo日志缓冲区太小,我们在继续前必须先等待对它清空。
所有带wait关键字都需要引起注意。
锁:
Innodb_row_lock_current_waits #当前等待行锁的行数。
Innodb_row_lock_time #从启动到现在,行锁定花费的总时间,单位毫秒。
Innodb_row_lock_time_avg #行锁定的平均时间,单位毫秒。
Innodb_row_lock_time_max #行锁定等待的最长时间,单位毫秒(一般建议设置为10秒)。这个值太大的话,可以考虑调低 innodb_lock_wait_timeout 值
Open_tables #当前正在用打开表空间文件,打开表的数量。如果当前1个表被并发10个线程访问,每个线程打开次数都算1.
Open_table_definitions #被缓存的.frm文件数量,一般该值就是表的数量。
table-open-cache,table-definition-cache #如果表cache不够大,需要关闭历史表才可以打开新表。
flush tables #把正在打开的表关闭,这种操作会产生mdl锁,尽量不要操作。备份时的FTWRL也是将所有表重新打开一遍
Opened_tables #历史总共打开次数,如果Opened_tables较大,table_open_cache 值可能太小。
no-auto-rehash #如果表太多,客户端没使用该参数,每次打开都会统计表信息。
Queries #已经发送给服务器的查询的个数,通常指DML
Questions #发送到服务器的请求次数。
和性能有关:
Select_full_join #没有使用索引的联接的数量。如果该值不为0,你应仔细检查表的索引,可以查慢日志。
Select_scan #对一个表进行完全扫描的联接的数量
Slow_queries #查询时间超过 long_query_time秒的查询的个数
Sort_merge_passes #对一个结果进行排序时,又不能基于索引排序,需要多次 递进排序才能得到最终结果。排序算法已经执行的合并的数量,每次合并都要加1。如果这个变量值较大,应考虑增加sort_buffer_size系统变量的值,尽量不要产生基于磁盘的临时文件。
default_tmp_storage_engine #5.6开始可以强制定义产生的临时表使用引擎
Table_locks_immediate #立即获得的表的锁的次数,绝大多数指的是myisam引擎,innodb 发生dml时做DDL操作也会发生表锁。
Table_locks_waited #不能立即获得的表的锁的次数。如果该值较高,并且有性能问题,你应首先优化查询,然后拆分表
Threads_cached #当前缓存了多少个线程
Threads_connected #当前正在打开的连接的数量。
Threads_created #创建用来处理连接的线程数。如果Threads_created较大,你可能要增加thread_cache_size值。缓存访问率的计算方法Threads_created/Connections。
Threads_running #激活的(非睡眠状态)线程数
innodb_thread_concurrency #innodb内部可以允许并发的数量,设置为逻辑CPU数量即可。