一、程序的定义
程序 = 数据结构 + 算法
程序是为了解决实际问题而存在的。然而为了解决问题,必定会使用到某些数据结构以及设计一个解决这种数据结构的算法。例如:有些交友网站能够列出你可能认识的好友,是为了解决网络聊天的问题。要解决这个问题,必定会使用到图这种数据结构(最短路径), 然而光有数据结构还不行,要实现这个功能,必须在图这种数据结构的基础上,设计一种算法,一步一步的操作,这些一步一步的操作就是算法,算法是特定问题求解步骤的描述。 再如: abbyy软件(一款OCR识别软件,简单说就是把图片还原成word的形式), 是为了解决图片处理的问题。要解决表格还原这个问题,必定会使用到"树"这种数据结构,在树这种结构上,一步一步实现还原功能。类似的软件还有五子棋中的判断输赢算法, 走迷宫算法等等。
二、数据结构的定义
一般来说,用计算机解决一个具体问题时,首先从具体问题抽象出一个适当的数学模型(也就是数据结构), 然后设计一个解决此数学模型的算法。
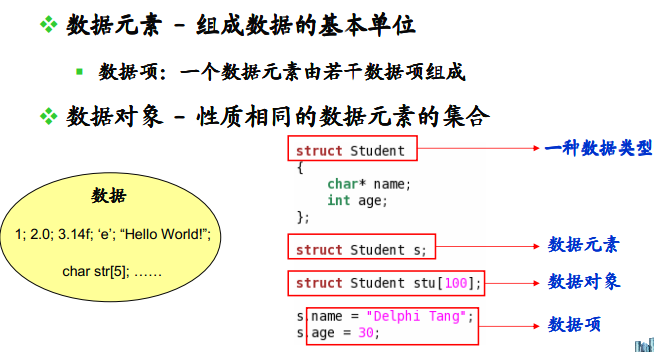
数据结构: 我们要研究对象的数据元素之间的关系。通常我们说的数据结构是一种逻辑结构,程序运行时必须把这些逻辑结构转为物理结构。
常见逻辑数据结构:集合结构(两个函数中分别定义的局部变量,两者没有任何关系),线性结构,树形结构,图形结构。

物理结构:顺序存储,链式存储。
三、算法的定义
算法是特定问题求解步骤的描述
算法是独立存在的一种解决问题的方法和思想
四、成为一个算法需要满足的条件
要看是否是一个算法,必须满足下面的这些条件
1. 输入
算法具有0个或者多个输入
2. 输出
至少有1个或者多个输出
3. 有穷性
算法在执行有限的步骤之后会自动结束而不会进行死循环状态
4. 确定性
算法中的每一步都有意义,不会出现二义性
5. 可行行
算法中每一步都必须可行
五、如何评判一个算法的好坏
1、正确性:
对于合法输入能够得到满足的结果
算法能够处理非法处理,并得到合理结果
算法对于边界数据和压力数据都能得到满足的结果
2、可读性:
算法要方便阅读,理解和交流,只有自己能看得懂,其它人都看不懂,谈和好算法。
3、健壮性:
算法不应该产生莫名其妙的结果,一会儿正确,一会儿又是其它结果
4、高性价比
利用最少的时间和资源得到满足要求的结果,可以通过(时间复杂度和空间复杂度来判定)
六、时间复杂度与空间复杂度
通常判定一种算法的效率可以采用事后统计法和事前分析估算
事后统计法缺点:
必须编写相应的测试程序,严重依赖硬件和运行时的环境,算法的数据采集相当的困难。
事前分析估算:
主要取决于问题的规模。
1、时间复杂度
公式: T(n) = O( f(n) ); 其中f(n)是问题规模n的函数,也就是执行某个操作的次数。
在没有特殊说明的情况下,我们所分析的时间复杂度都是指最坏的时间复杂度
常见时间复杂度:
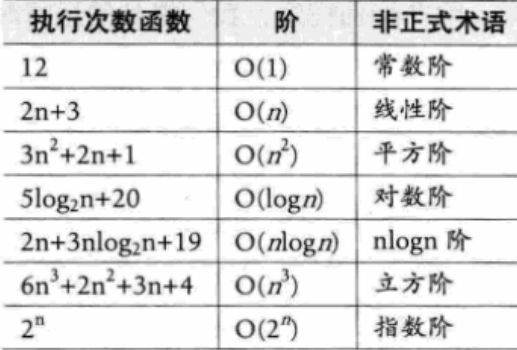
此外还有O(n!)等
各个时间复杂度的关系:

2、空间复杂度
公式: S(n) = O( f(n) ) 其中f(n)是在问题规模为n时所占用的内存空间大小;
大O表示法同样也适合空间复杂度,这里就不在重复说明了。
3.时间复杂度与空间复杂度的策略
多算情况下,算法的执行时所用的时间更令人关注;
如果有必要,可以增加空间复杂度来降低时间复杂度;
同理,也可以添加时间复杂度来降低空间复杂度,例如像51单片机,嵌入式设备,内存资源是很珍贵的,就可以通过增加时间复杂度来降低空间复杂度;
因此,我们在实现算法的时候,需要分析具体问题对执行时间和空间的要求;
下面看一个通过添加空间复杂度来降低时间复杂度的例子:
#include <stdio.h> #include <stdlib.h> //功能: 从1---1000中,找出出现次数最多的那个数字 int Search(int array[], int nLen); int main() { int array[] = {1, 1, 3, 4, 5, 6, 6, 6, 2, 3}; Search( array, sizeof(array) / sizeof(array[0]) ); return 0; } int Search(int array[], int nLen) { int anTemp[1000] = {0}; int nIndex = 0; int nTempPos = 0; int nMax = 0; //把1---1000中的某一个数存储在anTemp数组中的位置 //把把1---1000中的某一个数的个数加1 for(nIndex = 0; nIndex <nLen; nIndex++) { nTempPos = array[nIndex] - 1; anTemp[nTempPos]++; } //在anTemp中找出最大值 for(nIndex = 0; nIndex < 1000; nIndex++) { if(nMax < anTemp[nIndex]) { nMax = anTemp[nIndex]; } } //输出1---1000之间出现最多的那个数字 for(nIndex = 0; nIndex < 1000; nIndex++) { if(nMax == anTemp[nIndex]) { printf("%d ", nIndex + 1); } } return 0; }
在这个例子中,通过开辟一个int anTemp[1000]大小的存储空间,用来存放1---1000中每个数字出现的次数,虽然增加了空间复杂度,但是降低了时间复杂度。
类似的例子还有表驱动算法,也是通过开辟一个空间,然后从该空间中找到需要的内容。举个例子:像计算某年是否是闰年,就可以通过开辟一个2050大小的空间(1--2050年),并根据事先已经知道的结果,是闰年的就设为1,否则设为0;例如判断2014是否是闰年,就只需要查找这个数组中索引为2013那个元素内容是否为1就可以了。