Q:给定一个字符串s和一组单词dict,判断s是否可以用空格分割成一个单词序列,使得单词序列中所有的单词都是dict中的单词(序列可以包含一个或多个单词)。
例如:
给定s=“leetcode”;
dict=["leet", "code"].
返回true,因为"leetcode"可以被分割成"leet code".
A:
第一反应是是我从字符串s的第一个开始遍历并申请一个tem变量来记录为被匹配的字符串,当匹配到字符串之后重新将tem设置为"",最后遍历完毕之后判断tem是否为空从而得到是否可以满足。这种思路缺陷就是我们能考虑有一种情况就是s="aaaaaaa", wordlidt=["aaaa", "aaa"],对于这个情况,她会每次都先匹配"aaa",这样导致最后还剩下一个"a"。输出False,所以不正确。
话说,这也是个陷阱,基本上网上大家的结果都这么错过……
后来看的别人的解答。
引用:https://blog.csdn.net/c_flybird/article/details/80703494
https://www.cnblogs.com/GoodRnne/p/10950784.html
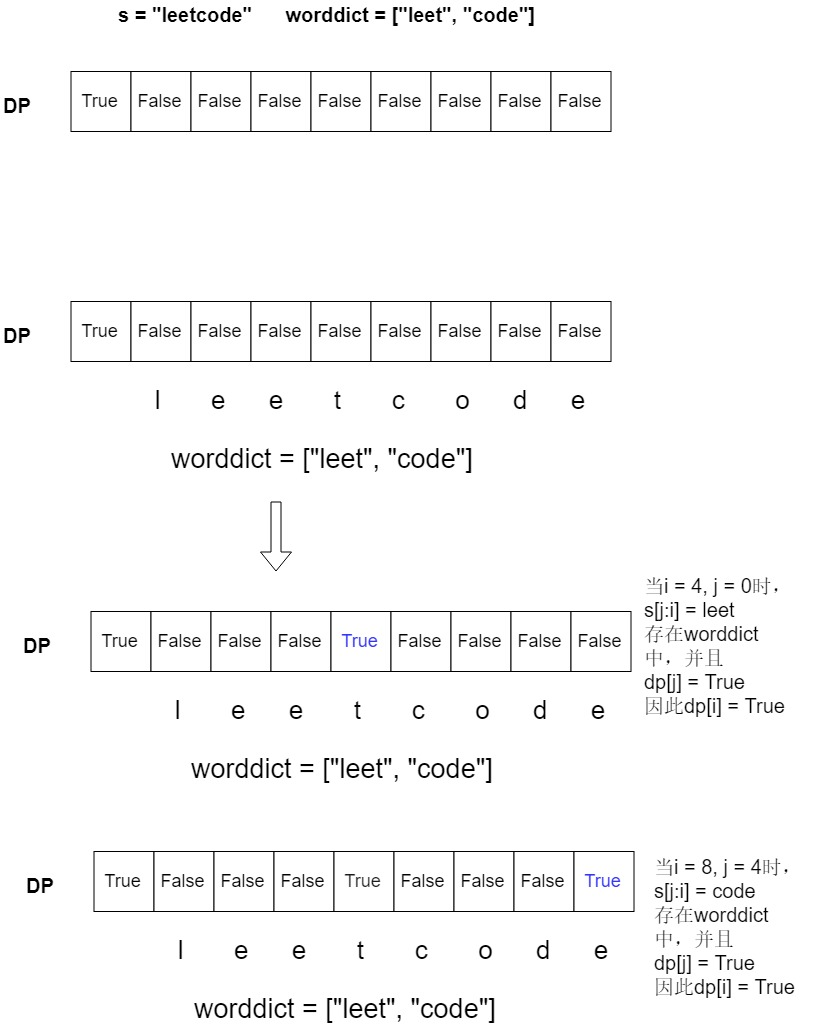
这里的第一层 i 循环,其实就是我们刚才讲的1,也就是子问题。可以理解为 i 从1一直到s.length() ,分别表示从下标0开始,长度为1的子问题,长度为2的子问题,……,长度为s.length()的子问题。而长度为s.length()的子问题的解,其实也就是原问题的解了。
现在再来解释flag数组。可以理解为 flag[i] == true表示长度为i的子问题是可以成功被划分的。 现在假设已经有 flag[i] == true,即长度为 i 的子问题是可以被划分的。现在已经遍历到 i+x 长度的子问题。遍历到j == i时,也就是 flag[j] == flag[i] 由我刚才的假设知 ==true,即 长度为 i 的子问题是可以被划分的并且有s.substr(j,i-1) 这个子串包含在 dict中。所以长度为j的子问题现在就可以被划分成 长度为i的子问题+s.substr(j,i-1) 。所以 长度为 j 的子问题是可以被划分的,也就可以break了。这样,是不是就利用了前面 子问题i 的计算结果避免了重复计算 子问题i呢。
如图:
代码:
public boolean wordBreak(String s, Set<String> dict) {
if (s.length() == 0 || dict.size() == 0)
return false;
int size = s.length();
boolean[] array = new boolean[size + 1];
array[0] = true;
for (int i = 1; i <= size; i++) {
for (int j = i - 1; j >= 0; j--) {
if (array[j] && dict.contains(s.substring(j, i))) {
array[i] = true;
break;
}
}
}
return array[size];
}