本文导读:
1、基于storm的应用
2、storm的单点故障解决
3、strom与算法的结合学习
4、杂记——常见问题的解答
5、http://www.blogchong.com/catalog.asp?tags=问题整理(storm)
Storm存在的一些问题:(V 0.7.4之前)
1、编程门槛对普通用户较高
2、框架无持久化存储
3、框架不提供消息接入模块 —— kafka
4、storm ui 功能简单
5、跨topology的boit复用
6、nimbus单点故障
7、topology不支持动态部署
storm业务需求:
1、条件过滤 这是storm最基本的处理方式,对符合条件的数据进行实时过滤,将符合条件的数据保存下来,这种实时查询的业务需求在实际应用中很常见。 2、中间件计算 我们需要改变数据中某一个字段(例如是数值),我们需要利用一个中间值经过计算(值比较、求和、求平均等)后改变该值,然后将数据重新输出。 3、求TopN 相信大家对TopN类的业务需求也是比较熟悉的,在规定的时间窗口内,统计数据出现的TopN,该类处理在购物及电商业务需求中,比较常见。 4、分布式RPC storm有对RPC进行专门的设计,分布式RPC用于对storm上大量的函数调用进行并行计算,最后将结果返回给客户端。 5、推荐系统 在实时处理时从mysql及hadoop中获取数据库中的信息,例如在电影推荐系统中,传入数据为用户当前点播电影信息,从后数据库中获取的是该用户之前的一些点播电影信息统计。 6、批处理 所谓批处理就是数据积攒到一定触发条件 ,就批量输出,所谓的触发条件类似事件窗口到了,统计数量够了及检测到某种数据传入等等。 7、热度统计 热度统计实现依赖于TimeCacheMap数据结构,该结构能够在内存中保持近期活跃的对象。我们可以使用它来实现例如论坛中的热帖排行统计等。
1、基于storm的应用系统:
(1)基于storm的网络爬虫系统的设计与实现:
大体框架:
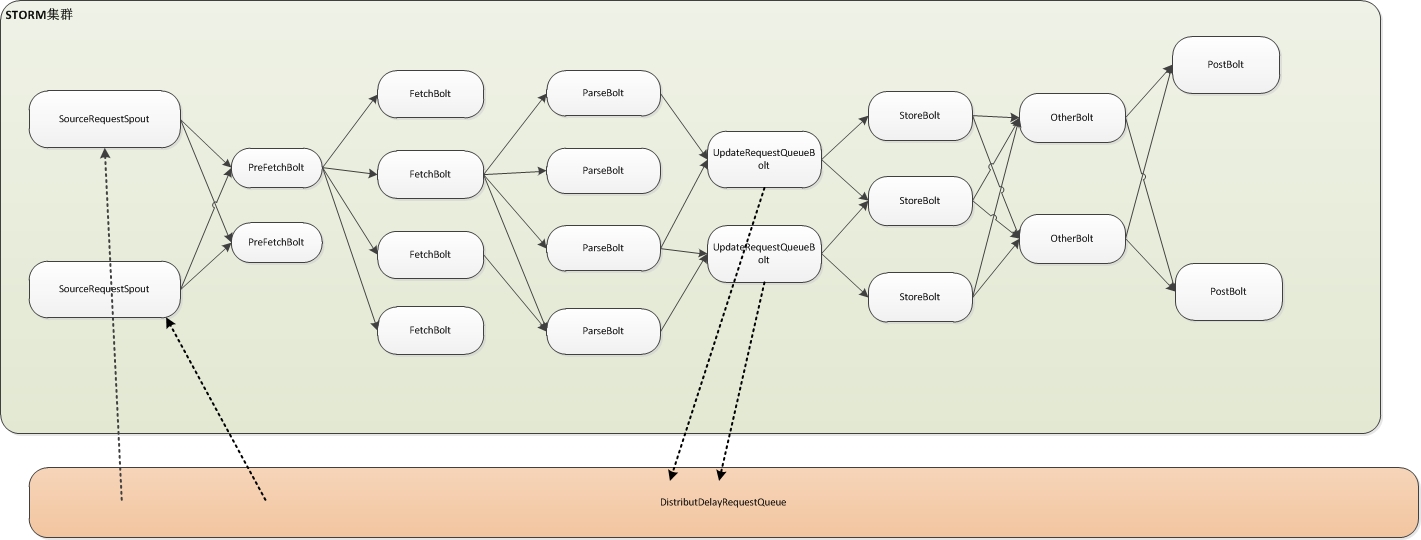
众所周知,爬虫系统里几个必不可少的模块,像下载、解析、回写待爬资源、存储等,本质上他们像是一个责任链,但后一个module又基于前一个module,所以可以理解为一种流处理模型,从我们拿到待爬URL一直到处理完毕存储数据,这是一个完整的过程。如您看到的这张图,如果我们实现了storm化,那么基于storm强大的功能,我们的爬虫可以完美运行在storm集群上,并且每类处理器我们都可以非常灵活的分配其线程数,耗时的处理我们多开几个线程,可以实现资源合理利用,当然既然是集群,你的某个任务具体运行在哪里,storm已经帮您分配好了,并且帮我们实现了节点失效等处理。
最后如果bolt间传输的消息量比较大,有可能网络是个瓶颈。
其他应用:——基于storm的实时交通状况的设计与分析
............
2、storm单点故障问题:
(1)采用master组解决单点故障
思路:
zookeeper解决方案还是相当复杂的,最近想到使用master组来解决这一问题,一个系统只有一个master组,它由若干个节点组成,好处:
1、结构简单,容易理解和实现
2、master组中的一个节点不管理集群内所有元数据,而只分担其中一部分,这样系统的扩展能力更强,不会受限于元数据
3、master组中的节点互备,可以解决单点故障问题
4、为性能而优化,专注于解决小文件性能问题,目标是达到实时检索
讨论:P2P解决方案
问:master组的实现,hadoop的热备份等都比较困难?
答:master数据备份可以直接采用多写方式,只有一个异常的master恢复时,才需要同步。
问:zookeeper是仅仅适用于hbase这种master slave模式还是也适应于multi master?
答:ZooKeeper使用没有限制的,比如它的分布式锁能力和配置能力,有广泛的应用。关于Master组腾讯的XFS就采用了,不过仍然有个单点的顶层Master,采用了ZooKeeper做主备切换。顶层的单点Master,通常有两个备,在数据未同步时,叫Newbie(学习者),只有数据一致后才叫Standby,数据的一致是通过两阶段来保证的。
----讨论-----后续见:storm源码之一个class解决nimbus单点问题【转】
--单点问题可以参考hdfs的实现~
--hdfs的namenode也是单节点,secondnode也只是为合并操作日志以缩短namenode的启动时间而设。目前hadoop的namenode单点问题也是下一代hadoop要解决的重要问题。
--那是2.0之前的版本,现在两个namenode之间采用nfs共享元数据,通过zookeeper选举一个作为当前active,另一个作为standby,当active挂了之后,能够在短时间内切换到standby节点,实现高可用~
--nimbus节点利用nfs共享存储也是一种解决方案。可以通过将Froastman实现的storage.clj作如下修改:
(^boolean isSupportDistributed [this] true))))
Nathanmarz因此在0.8.2版本的基础上,新开了storm-0.8.2-ha分支,专门用来解决nimbus单点问题,并将Frostman已完成的nimbus-storage代码合并到该分支。
Rostman在nimbus-storage基础上继续增加了nimbus多节点选举机制,(目前尚未被Nathanmarz合并入storm-ha分支)。
nimbus单点问题的解决思路
1、Frostman的工作已为彻底解决nimbus单点问题奠定了重要基础:
-
- nimbus ip地址动态获取
- topology代码存储方案可定制
- nimbus多节点选举,宕机自动切换
- nimbus leader状态ui展示
在Frostman工作的基础上继续深入,将极大减少工作量。
2、Frostman并未解决topology代码如何在多个nimbus节点或集群所有节点间共享的问题。Nathamarz的理想规划是:实现storm集群中所有nimbus、supervisor机器之间通过P2P协议共享topology代码,但目前限于BitTorrent未完成的工作,目前暂停了nimbus-ha分支的开发。
3、最终选定的解决方案:实现定制的nimbus-storage插件NimbusCloudStorage,使得所有nimbus节点在启动后均从leader 轮询下载本地不存在的topology代码。依次满足supervisor在nimbus节点切换后下载代码的需求。
3、Storm与算法的结合:
...........
基于storm的聚类算法的分析与实现,基于storm的关联规则的分析与实现,storm平台一致性哈希算法的分析与研究等等...
4、杂记:
——storm常见问题解答
转载于http://blog.csdn.net/hguisu/article/details/8454368#t3 (20121231)
一、我有一个数据文件,或者我有一个系统里面有数据,怎么导入storm做计算?
你需要实现一个Spout,Spout负责将数据emit到storm系统里,交给bolts计算。怎么实现spout可以参考官方的kestrel spout实现:
https://github.com/nathanmarz/storm-kestrel
如果你的数据源不支持事务性消费,那么就无法得到storm提供的可靠处理的保证,也没必要实现ISpout接口中的ack和fail方法。
二、Storm为了保证tuple的可靠处理,需要保存tuple信息,这会不会导致内存OOM?
Storm为了保证tuple的可靠处理,acker会保存该节点创建的tuple id的xor值,这称为ack value,那么每ack一次,就将tuple id和ack value做异或(xor)。当所有产生的tuple都被ack的时候, ack value一定为0。这是个很简单的策略,对于每一个tuple也只要占用约20个字节的内存。对于100万tuple,也才20M左右。关于可靠处理看这个:
https://github.com/nathanmarz/storm/wiki/Guaranteeing-message-processing
三、Storm计算后的结果保存在哪里?可以保存在外部存储吗?
Storm不处理计算结果的保存,这是应用代码需要负责的事情,如果数据不大,你可以简单地保存在内存里,也可以每次都更新数据库,也可以采用NoSQL存储。storm并没有像s4那样提供一个Persist API,根据时间或者容量来做存储输出。这部分事情完全交给用户。
数据存储之后的展现,也是你需要自己处理的,storm UI只提供对topology的监控和统计。
四、Storm怎么处理重复的tuple?
因为Storm要保证tuple的可靠处理,当tuple处理失败或者超时的时候,spout会fail并重新发送该tuple,那么就会有tuple重复计算的问题。这个问题是很难解决的,storm也没有提供机制帮助你解决。一些可行的策略:
(1)不处理,这也算是种策略。因为实时计算通常并不要求很高的精确度,后续的批处理计算会更正实时计算的误差。
(2)使用第三方集中存储来过滤,比如利用mysql,memcached或者redis根据逻辑主键来去重。
(3)使用bloom filter做过滤,简单高效。
五、Storm的动态增删节点
我在storm和s4里比较里谈到的动态增删节点,是指storm可以动态地添加和减少supervisor节点。对于减少节点来说,被移除的supervisor上的worker会被nimbus重新负载均衡到其他supervisor节点上。在storm 0.6.1以前的版本,增加supervisor节点不会影响现有的topology,也就是现有的topology不会重新负载均衡到新的节点上,在扩展集群的时候很不方便,需要重新提交topology。因此我在storm的邮件列表里提了这个问题,storm的开发者nathanmarz创建了一个issue 54并在0.6.1提供了rebalance命令来让正在运行的topology重新负载均衡,具体见:
https://github.com/nathanmarz/storm/issues/54
和0.6.1的变更:
http://groups.google.com/group/storm-user/browse_thread/thread/24a8fce0b2e53246
storm并不提供机制来动态调整worker和task数目。
六、Storm UI里spout统计的complete latency的具体含义是什么?为什么emit的数目会是acked的两倍?
这个事实上是storm邮件列表里的一个问题。Storm作者marz的解答:
tuple being acked on the spout. So it tracks the time for the whole tuple
tree to be processed.
If you dive into the spout component in the UI, you'll see that a lot of
the emitted/transferred is on the __ack* stream. This is the spout
communicating with the ackers which take care of tracking the tuple trees.
简单地说,complete latency表示了tuple从emit到被acked经过的时间,可以认为是tuple以及该tuple的后续子孙(形成一棵树)整个处理时间。其次spout的emit和transfered还统计了spout和acker之间内部的通信信息,比如对于可靠处理的spout来说,会在emit的时候同时发送一个_ack_init给acker,记录tuple id到task id的映射,以便ack的时候能找到正确的acker task。
七、strom不能实现不同topology之间stream的共享
Storm中Stream的概念是Topology内唯一的,只能在Topology内按照“发布-订阅”方式在不同的计算组件(Spout和Bolt)之间进行数据的流动,而Stream在Topology之间是无法流动的。
对于不同topology前半部分共用Spouts和Bolts不能直接复用,解放方案有以下三种:
(1)kill原topology,共用前半部分的Spouts和Bolts,在分支Bolt处分别处理,重新打包形成新的topology并提交;
(2)从相同的外部数据源单独读取数据,设计与前一个topology相同的新topology处理后面的新任务;
(3)通过Kafka消息中间件实现不同topology的Spout共享数据源,重新部署运行新的topology即可。
参考链接:Storm数据流模型的分析及讨论
参考链接: