一、选一个自己感兴趣的主题。
对新浪新闻的时政页面进行爬取,分析今天一天的新闻关键词是什么。
二、对新浪页面进行分析
的到新浪页面的URL地址为:http://www.sohu.com/c/8/1460.html,需要得到的页面的每条新闻的链接地址,在a标签页面下用正则表达式进行过滤,得到每条新闻的链接地址。
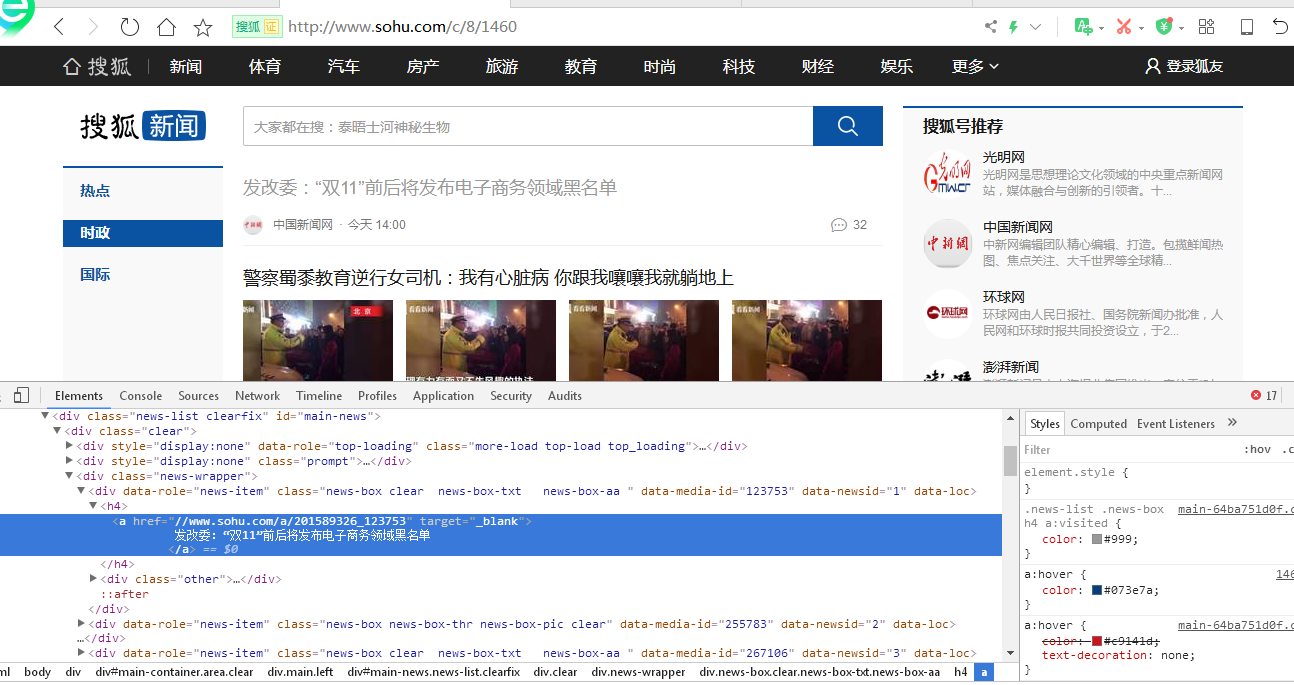
抓取每条新闻的链接地址:
#访问搜狐新闻时政界面第一页,将界面的每条新闻的地址链接挑选出来 html = requests.get('http://www.sohu.com/c/8/1460.html') html.encoding = 'utf-8' soup = BeautifulSoup(html.text,'html.parser') news_list = soup.find_all('a',href=re.compile(r'//www.sohu.com/')) news_urls = set() for url in news_list: news_url = url['href'] news_urls.add(news_url)
三、对抓取到的每个链接进行访问并下载页面
分析出每个界面的标题是拥有text-title类的div标签,每个界面的新闻是拥有article类的article标签。并将下载的新闻放到news字符串里面
news="" for url in news_urls: html = requests.get('http:' + url) html.encoding = 'utf-8' soup = BeautifulSoup(html.text,'html.parser') title=soup.find('div',class_='text-title').find('h1') content=soup.find('article',class_='article') news = news + content.get_text()
四、对抓取出来的所有新闻进行文本分析及过滤。
ex = [chr(x) for x in range(32,125)] for ch in ex: news = news.replace(ch,'') exchi= ['‘','’','“','”','。','【','】','《','》','、',':',';','!','(',')','?',',','{','}'] for ch in exchi: news = news.replace(ch,'') print(news," ") #对新闻进行文本分析 ls = [] words = jieba.lcut(news) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 ls.append(word) items = list(counts.items()) items.sort(key = lambda x:x[1], reverse = True) for i in range(10): word , count = items[i] print ("{:<10}{:>5}".format(word,count)) ex =[' ','‘','’','“','”','。','《','》','u3000',' ','n', '、',':',';','!','(',')','?',',','{','}','原标题',''] for ke in ls: if ke in ex: ls.remove(ke)
五、制作词云
wz = open('ms.txt','w+') wz.write(str(ls)) wz.close() wz = open('ms.txt','r').read() backgroud_Image = plt.imread('apple.jpg') wc = WordCloud( background_color = 'white', # 设置背景颜色 mask = backgroud_Image, # 设置背景图片 max_words = 2000, # 设置最大现实的字数 stopwords = STOPWORDS, # 设置停用词 font_path = 'C:/Users/Windows/fonts/msyh.ttf',# 设置字体格式,如不设置显示不了中文 max_font_size = 200, # 设置字体最大值 random_state = 30, # 设置有多少种随机生成状态,即有多少种配色方案 ) wc.generate(wz) image_colors = ImageColorGenerator(backgroud_Image) wc.recolor(color_func = image_colors) plt.imshow(wc) plt.axis('off') plt.show()
六、输出结果
利用jieba进行文本分析的结果。

词云的输出结果。

七、程序源代码
import re import requests from bs4 import BeautifulSoup import jieba import matplotlib.pyplot as plt from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator #访问搜狐新闻时政界面第一页,将界面的每条新闻的地址链接挑选出来 html = requests.get('http://www.sohu.com/c/8/1460.html') html.encoding = 'utf-8' soup = BeautifulSoup(html.text,'html.parser') news_list = soup.find_all('a',href=re.compile(r'//www.sohu.com/')) news_urls = set() for url in news_list: news_url = url['href'] news_urls.add(news_url) #逐一访问刚刚爬取的新闻界面,并将界面的新闻下载 news="" for url in news_urls: html = requests.get('http:' + url) html.encoding = 'utf-8' soup = BeautifulSoup(html.text,'html.parser') title=soup.find('div',class_='text-title').find('h1') content=soup.find('article',class_='article') news = news + content.get_text() ex = [chr(x) for x in range(32,125)] for ch in ex: news = news.replace(ch,'') exchi= ['‘','’','“','”','。','【','】','《','》','、',':',';','!','(',')','?',',','{','}'] for ch in exchi: news = news.replace(ch,'') #对新闻进行文本分析 ls = [] words = jieba.lcut(news) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 ls.append(word) items = list(counts.items()) items.sort(key = lambda x:x[1], reverse = True) for i in range(10): word , count = items[i] print ("{:<10}{:>5}".format(word,count)) ex =[' ','‘','’','“','”','。','《','》','u3000',' ','n', '、',':',';','!','(',')','?',',','{','}','原标题',''] for ke in ls: if ke in ex: ls.remove(ke) #制作词云 wz = open('ms.txt','w+') wz.write(str(ls)) wz.close() wz = open('ms.txt','r').read() backgroud_Image = plt.imread('apple.jpg') wc = WordCloud( background_color = 'white', # 设置背景颜色 mask = backgroud_Image, # 设置背景图片 max_words = 2000, # 设置最大现实的字数 stopwords = STOPWORDS, # 设置停用词 font_path = 'C:/Users/Windows/fonts/msyh.ttf',# 设置字体格式,如不设置显示不了中文 max_font_size = 200, # 设置字体最大值 random_state = 30, # 设置有多少种随机生成状态,即有多少种配色方案 ) wc.generate(wz) image_colors = ImageColorGenerator(backgroud_Image) wc.recolor(color_func = image_colors) plt.imshow(wc) plt.axis('off') plt.show()