什么是文档
Elasticsearch是面向文档的,文档是可搜索数据区的最小单元,例如:日志文件中的日志项,一个电影的详细信息等。在Elasticsearch中文档被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
{
"GenTime" : """"2019-12-26 09:13:36"""",
"EventName" : "HTTP_XSS脚本注入",
"EventID" : "152526081",
"SerialNum" : "0113211811149999",
"@timestamp" : "2019-12-26T01:13:36.670Z",
"deamon" : "IPS",
"time" : "Dec 26 09:13:36",
"SMAC" : "f4:15:63:d4:3a:05",
"EventLevel" : "2",
"EventsetName" : "All",
"SecurityID" : "28",
"SrcPort" : "65320",
"Action" : "PASS Vsysid=0",
"syslog5424_pri" : "212",
"DstIP" : "10.3.160.112",
"EvtCount" : "1",
"Protocol" : "TCP",
"InInterface" : "ge0/3"
}
文档元数据
元数据是丰富文档的相关信息
... { "_index" : "ips-event2019.12.26", "_type" : "_doc", "_id" : "UYHEP28BhfJeQd0SJfMF", "_score" : 1.0, "_source" : { "GenTime" : """"2019-12-26 09:13:36"""", "EventName" : "HTTP_XSS脚本注入", "EventID" : "152526081", ..... }
- _index 文档所属索引名称
- _type 文档所属的类型名
- _id 文档唯一id
- _score 相关性打分
- _source 文档的原始数据
什么是索引
索引是文档的容器,是一类相似文档的集合
- Index体现了逻辑空间的概念,每个索引都有自己的mapping定义,用于定义包含的文档的字段名和字段类型
- Shard 体现物理空间的概念,索引中的数据分散到各个Shard上
索引的Mapping和Setting
- Mapping是定义索引中的所有文档中的字段类型
- Setting是定义数据的不同分布
常见API使用
以下可以在DevTools中实验
#查看索引相关信息,可以看到Mapping和Setting的定义 GET movies #查看索引的文档总数 GET movies/_count #查看索引前10条文档 GET movies/_search { }
节点
master节点
- 每一个节点启动后,默认就是mastrt eligible节点(可以设置node.master: flase 禁止)
- mastrt eligible节点可以参加选主流程,成为master节点
- 当第一个节点启动时,它将会把自己选举成master节点
- 每一个节点都保存集群状态,只有master节点才能修改集群的状态
- 集群状态,维护一个集群中的必要信息
- 所有节点信息
- 所有索引和其相关的Mapping和Setting信息
- 分片的路由信息
- 集群状态,维护一个集群中的必要信息
Data节点
- 可以保存数据的节点,负责保存分片数据,在数据扩展中起到了至关重要的作用
Coordianting 节点
- 负责接收Clent端的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordianting Node的职责
Hot & warm节点
- 不同硬件配置的Data Node。把热门索引或者近期索引放在高配置节点(Hot节点)上,反而冷门索引和相对久远的数据放到低配置节点(warm节点)上。从而节省资源
Machine Learning 节点
- 用来跑机器学习的job,来发现数据中的异常
配置节点类型
- 开发环境中一个节点可以承担多个角色
- 生产环境,应该设置单一的角色节点
| 节点类型 | 配置参数 | 默认值 |
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| Coordianting only | 无 | 每个节点默认都是Coordianting。设置其他类型为false |
|
machine learning |
node.ml | true(需要enable x-pack) |
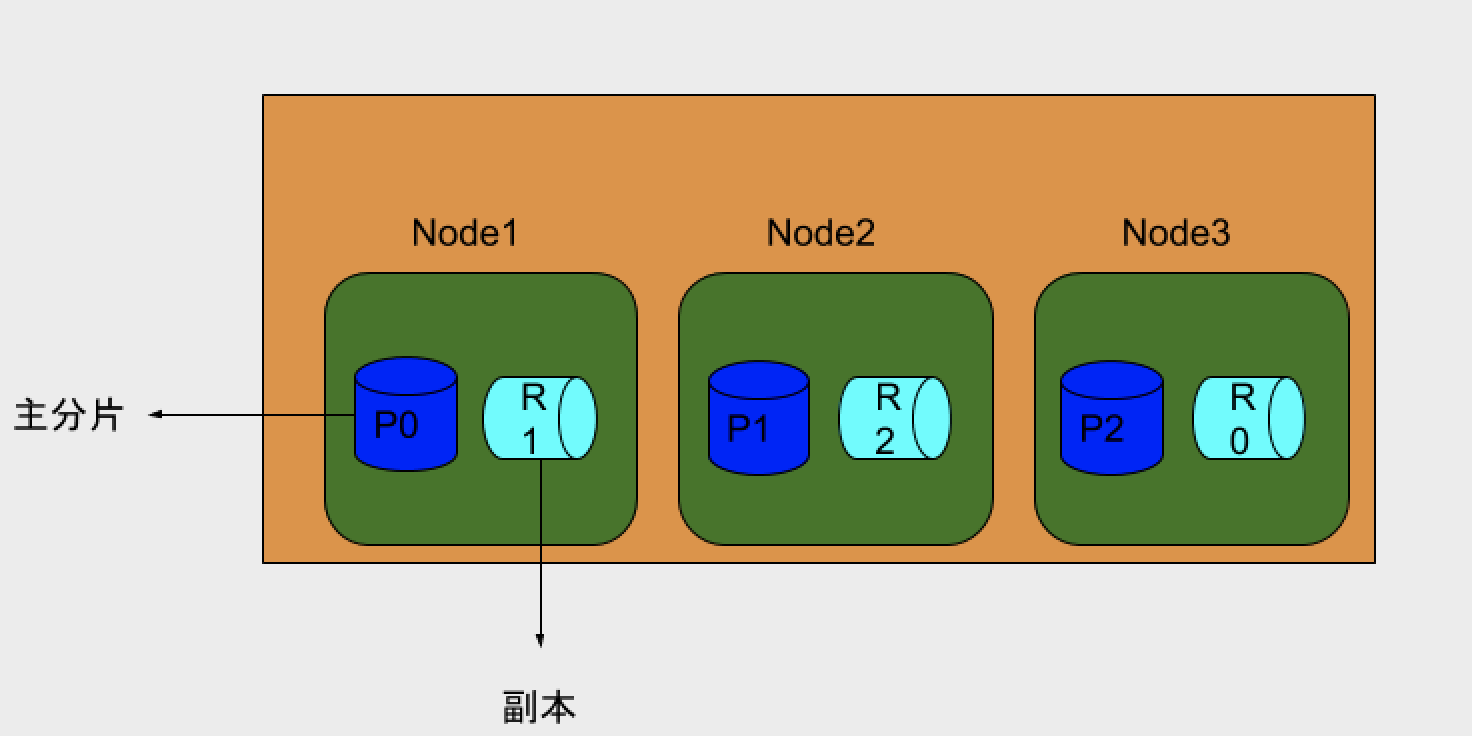
分片
分片分为两种,主分片和副本:
主分片用于解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的Lucene实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
副本用以解决数据高可用的问题,分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
查看一个三节点集群的分片和副本的分布情况:
创建一个三分片一副本的索引:

查看分布情况:
分片设定
对于生产的分片设定,需要提前设计好容量规划
- 分片数设置过下
- 导致后续无法增加节点实现水平扩展
- 单个分片数据量过大,导致数据重新分片耗时
- 分片数设置过大,7.0之后,默认主分片是1,解决了over-sharding的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多分片,会导致资源浪费,同时会影响性能
集群监控状态说明:
GET _cluster/health { "cluster_name" : "Sxp-Ops-ES-Cluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 3, "number_of_data_nodes" : 3, "active_primary_shards" : 10, "active_shards" : 20, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
Green
- 主分片和副本分配正常
Yellow
- 主分片全部正常,有副本未能正常分配
Red
- 有主分片未能分配
文档的CRUD
| Index | PUT myindex/_doc/1 |
| Create |
PUT myindex/_create/1 POST myindex/_doc(不指定ID 自动生成) |
| Read | GET myindex/_doc/1 |
| Update | POST myindex/_update/1 |
| Delete | DELETE myindex/_doc/1 |
创建文档
#创建文档POST方法 POST jaxzhai/_doc { "user": "jaxzhai", "Postdate":"20191226T20:23", "message":"This test create doc" } #指定ID存在 就报错 PUT jaxzhai/_doc/1?op_type=create { "user": "jax", "Postdate":"20191226T20:26", "message":"This test create doc" }
获取一个文档
#获取一个文档,通过ID GET jaxzhai/_doc/1
执行结果
{ "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 1, "_primary_term" : 1, "found" : true, "_source" : { "user" : "jax", "Postdate" : "20191226T20:26", "message" : "This test create doc" } }
PUT更新一下文档 通过ID
PUT jaxzhai/_doc/1 { "user": "zhaikun" } #执行结果 { "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1 }
我们看到version发生变化
源文档增加字段
#增加字段 POST jaxzhai/_update/1/ { "doc":{ "postdate":"20191226T20:34", "message":"This test update" } } #执行结果 { "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 3, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1 } #GET结果 { "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 3, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "user" : "zhaikun", "postdate" : "20191226T20:34", "message" : "This test update" } }
BULK API
BULK API是一次调用中执行多种操作,这样节省网络开销
支持以下4种操作:
- Create
- Update
- Index
- Delete
可以在URI中指定Index 也可以在请求的Playload中进行
操作中单条失败,并不会影响其他操作
返回结果包含每条执行结果
#Bulk POST _bulk {"index":{"_index": "test","_id":"1"}} {"field1":"v1"} {"delete":{"_index": "test","_id":"2"}} {"create":{"_index": "test2","_id":"3"}} {"field1":"v3"} {"update":{"_index": "test","_id":"1"}} {"doc":{"field2":"v2"}} #执行结果 { "took" : 184, "errors" : false, "items" : [ { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2", "_version" : 1, "result" : "not_found", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1, "status" : 404 } }, { "create" : { "_index" : "test2", "_type" : "_doc", "_id" : "3", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "update" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1, "status" : 200 } } ] }
批量读取 mget
GET /_mget { "docs":[ { "_index": "test", "_id": "1" }, { "_index": "test", "_id": "2" } ] } #执行结果 { "docs" : [ { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 2, "_seq_no" : 2, "_primary_term" : 1, "found" : true, "_source" : { "field1" : "v1", "field2" : "v2" } }, { "_index" : "test", "_type" : "_doc", "_id" : "2", "found" : false } ] }
常见错误返回
| 问题 | 原因 |
| 无法连接 | 网络故障或集群挂了 |
| 连接无法关闭 | 网络故障或节点错误 |
| 429 | 集群过于繁忙 |
| 4xx | 请求体格式错误 |
| 500 | 集群内部错误 |
URISearch
#URI查询 #查询2012,并查询结果里有df=title GET /movies/_search?q=2012&df=title { "profile": "true" } #泛查询 GET /movies/_search?q=2012 { "profile": "true" } #指定字段查询 GET /movies/_search?q=title:2012 { "profile": "true" }
指定指端 vs 泛查询
- q=title:2012 / q=2012
Term vs Phrase
- Beautiful Mind 等效 Beautiful 或者 Mind(两者有一 既返回)
- "Beautiful Mind" 等效 Beautiful AND Mind。(两者都存在才能返回) Phrase查询,要保持先后顺序
分组 vs 引号
- title:(Beautiful AND Mind)
- title="Beautiful Mind"
#使用引号,Phrase查询 GET /movies/_search?q=title:"Beautiful Mind" { "profile": "true" } #查询结果,可以看到查询出一条,查询type是PhraseQuery { "took" : 11, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 13.68748, "hits" : [ { "_index" : "movies", "_type" : "_doc", "_id" : "4995", "_score" : 13.68748, "_source" : { "title" : "Beautiful Mind, A", "genre" : [ "Drama", "Romance" ], "year" : 2001, "@version" : "1", "id" : "4995" } } ] }, "profile" : { "shards" : [ { "id" : "[ybtUpGB4StCgJIP3Rp05Xg][movies][0]", "searches" : [ { "query" : [ { "type" : "PhraseQuery", "description" : """title:"beautiful mind"""", "time_in_nanos" : 6930465, "breakdown" : { "set_min_competitive_score_count" : 0, "match_count" : 1, "shallow_advance_count" : 0, "set_min_competitive_score" : 0, "next_doc" : 27865, "match" : 69781, "next_doc_count" : 1, "score_count" : 1, "compute_max_score_count" : 0, "compute_max_score" : 0, "advance" : 293949, "advance_count" : 2, "score" : 8335, "build_scorer_count" : 4, "create_weight" : 2263785, "shallow_advance" : 0, "create_weight_count" : 1, "build_scorer" : 4266740 } } ], "rewrite_time" : 4433, "collector" : [ { "name" : "CancellableCollector", "reason" : "search_cancelled", "time_in_nanos" : 44976, "children" : [ { "name" : "SimpleTopScoreDocCollector", "reason" : "search_top_hits", "time_in_nanos" : 34993 } ] } ] } ], "aggregations" : [ ] } ] } }
#查找美丽心灵,Mind 为泛查询 GET /movies/_search?q=title:Beautiful Mind { "profile": "true" } #使用分组,Bool (类似把口号内容作为一个词组查询) GET /movies/_search?q=title:(Beautiful Mind) { "profile": "true" }
布尔操作
- AND/OR/NOT或者&&/||/!
- 必须大写
- title:(matrix NOT reloaded)
分组
- + 表示must
- - 表示must_not
- title:(matrix - reloaded)
#查找美丽心灵 #"type" : "BooleanQuery", #"description" : "+title:beautiful +title:mind",(同时满足beautiful mind) GET /movies/_search?q=title:(Beautiful AND Mind) { "profile": "true" } #查找美丽心灵 #"type" : "BooleanQuery", #"description" : "title:beautiful -title:mind",(满足必须包含beautiful 不能包含mind) GET /movies/_search?q=title:(Beautiful NOT Mind) { "profile": "true" }
范围查询
- 区间表示:[]闭区间,{}开区间
- year:{2019 TO 2018}
- year:[* TO 2018]
算符符号
- year:>2010
- year:(+2010 && <=2018)
- year:(+>2010 +<2018)
#范围查询,区间写法,数学写法 GET /movies/_search?q=year:>=1980 { "profile": "true" }
通配符查询(通配符查询效率低下,占用内存大,不建议使用,特别是放在最前面)
- ?代表一个字符,*代表0或多个字符
- title:mi?d
- title:be*
正则表达式
- title:[bt]oy
模糊匹配和近似查询
- title:befutifl~1
- title:"lord rings"~2
#模糊匹配 近似度匹配 GET /movies/_search?q=title:beautifl~1 { "profile": "true" } GET /movies/_search?q=title:"Lord Rings"~2 { "profile": "true" }
Request Body Search
POST /movies/_search { "from":10, "size":20, "query": { "match_all": {} } }
- 将语句通过HTTP Request Body 发送给Elasticsearch
- Query DSL
- from和size 达到分页效果
- sort 排序
- _source filtering 顾虑只需要的字段
POST /movies/_search { "_source": ["title","year"], "from":10, "size":20, "query": { "match_all": {} } }
查询方式
POST /movies/_search { "query": { "match": { "title": { "query": "Last Christmas", "operator": "and" } } } } POST /movies/_search { "query": { "match_phrase": { "title": { "query": "one love" , "slop": 1 } } }
Mapping
什么是Mapping
Mapping 类似数据库中的schema的定义,作用如下:
- 定义索引中的字段和名称
- 定义字段的数据类型,例如:字符串、数字、布尔
- 字段、倒排索引的相关配置
Mapping会把Json文档映射成Lucene所需的扁平格式
一个Mapping属于一个索引的Type
- 每一个文档都属于一个type
- 一个type有一个mapping定义
- 7.0开始,不需要在mapping定义中指定type信息
字段数据类型
简单类型
- Text/Keyword
- Data
- Integer/Floating
- Boolean
- IPv4 & IPv6
复杂类型
- 对象类型 / 嵌套类型
特殊类型
- geo_point & geo——shape / percolator
什么是Dynamic Mapping
- 在写入文档的时候,如果索引不存在,会自动创建索引
- Dynamic Mapping 的机制,使得我们无需手动定义Mappings,Elasticsearch会自动根据文档信息,推算出字段类型
- 但是有时候推算的不正确,例如地理位置信息
- 当类型设置不对时,会导致一些功能无法正常运行,例如Range查询
如何自动生成的类型:
PUT mapping_test/_doc/1 { "uid":"123", "isvip":false, "isadmin":"true", "age":19, "heigh":180 } GET mapping_test/_mapping { "mapping_test" : { "mappings" : { "properties" : { "age" : { "type" : "long" }, "heigh" : { "type" : "long" }, "isadmin" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "isvip" : { "type" : "boolean" }, "uid" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
能否更改Mapping字段
新增字段:
- Dynamic 设置为true时,一旦有新字段的文档写入,Mapping同时也会被更新
- Dynamic 设置为false时,Mapping不会被更新,新增字段的数据无法被索引,但是信息会出现在_source中。
- Dynamic 设置为strict,文档写入失败
对已有的字段
- Lucene实现的倒排索引,一旦生成后,就不允许修改
如果希望改变字段类型,必须Reindex API,重建索引
#默认Mapping支持Dynamic,写入的文档中加入新的字段 #写入一个新索引 PUT mapping_dynamic_test/_doc/1 { "field":"somevalue" } #查看是否可以被索引(可以) POST mapping_dynamic_test/_search { "query": { "match": { "field": "somevalue" } } } #修改dynamic的值为false PUT mapping_dynamic_test/_mapping { "dynamic":false } #新增字段anotherField PUT mapping_dynamic_test/_doc/10 { "anotherField":"sv" } #查看是否可以被索引(不可以,但不报错) POST mapping_dynamic_test/_search { "query": { "match": { "anotherField": "sv" } } } #查看mapping配置(没有anotherField字段) GET mapping_dynamic_test/_mapping #修改dynamic的值为strict PUT mapping_dynamic_test/_mapping { "dynamic": "strict" } #再尝试加入一个字段(写入数据错误,400) PUT mapping_dynamic_test/_doc/10 { "lastfield":"v3" }
如何显示定义一个mapping
为了减少输入量,并减少错误,可以依照下面几步操作:
- 创建一个临时索引,写入一些样本数据
- 通过访问Mapping API 获得该临时文件的动态mapping定义
- 修改后,使用该配置创建所需的索引
- 删除临时索引
Index 控制字段是否被索引,默认是true,如果设置成false,该字段不可索引。
什么是Index Template
Index Template 帮助设定mapping和setting,并按照一定的规则自动匹配到新建索引上
- 模板仅在索引被新创建时使用,修改模板不是影响已创建的索引
- 可以设定多个索引模板,这些设置可以“合并”在一起
- 可以指定“order”的数值,控制“合并中”的过程
工作方式:
当一个索引被创建时:
- 应用Elasticsearch默认的mapping和setting
- 应用order数值低Index Template 中的设定
- 应用order数值高的Index Template模板中,之前的会被覆盖
- 应用索引被创建时,用户指定的Settings和Mappings,并覆盖之前的模板中的设定
##Index Template 测试(默认方式) PUT template_test/_doc/1 { "Sn":"1", "Sd":"2019/12/27" } #查看 sd正确推断成date类型,而Sn是text类型 GET template_test/_mapping #创建两个模板 PUT _template/template_default { "index_patterns":["*"], "order":0, "version":1, "settings":{ "number_of_shards":1, "number_of_replicas":1 } } PUT _template/template_test { "index_patterns":["test*"], "order":1, "version":1, "settings":{ "number_of_shards":1, "number_of_replicas":2 }, "mappings":{ "date_detection": false, "numeric_detection": true } } #查看Index Template GET /_template/template_default GET _template/temp* #写入一个test开头的index PUT testtemplate/_doc/1 { "Sn":"1", "Sd":"2019/12/27" } #我们发现原本sd转换日期类型的没有转换,而sn转换成长整形 GET testtemplate/_mapping #因为我们之前设置成2副本,查看settings,副本数为2 GET testtemplate/_settings
什么是Dynamic Template
根据Elasticsearch识别的数据类型,结合字段名称,来动态设定字段类型
- 所有字符串类型都设成keyword,或者关闭keyword字段
- is开头的字段都设置成boolean
- long_开头的都设置成long类型
#创建Dynamic Template PUT myindex { "mappings": { "dynamic_templates": [ { "full_name": { "path_match": "name.*", "path_unmatch": "*.middle", "mapping": { "tyep": "text", "copy_to": "full_name" } } } ] } } PUT myindex/_doc/1 { "name":{ "first":"zhai", "middle":"jax", "last": "anni" } } GET myindex/_search?q=full_name:zhai