本文主要介绍 ElasticSearch 搜索相关的知识,首先会介绍下 URI Search 和 Request Body Search,同时也会学习什么是搜索的相关性,如何衡量相关性。
Search API
我们可以把 ES 的 Search API 分为两大类,第一类是 URI Search,用 HTTP GET 的方式在 URL 中使用查询参数已达到查询的目的;另一类为 Request Body Search,可以使用 ES 提供的基于 JSON 格式的格式更加完备的查询语言 Query DSL(Domain Specific Language)
| 语法 | 范围 |
|---|---|
| /_search | 集群上所有的索引 |
| /jvm/_search | jvm |
| /jvm,sql/_search | jvm 和 sql |
| /jvm*/_search | 以 jvm 开头的索引 |
在查询的时候需要通过 _search 来标明这个请求为搜索请求,同时可以指定 index,也可以指定多个 index,也可以使用通配符的方式对 index 进行搜索。
下面来看下 URI Search:
URI Search
GET /users/_search?q=username:wupx
URI Search 使用的是 GET 方式,其中 q 指定查询语句,语法为 Query String Syntax,是 KV 键值对的形式;上面的请求表示对 username 字段进行查询,查询包含 wupx 的所有文档。
URI Search 有很多参数可以指定,除了 q 还有如下参数:
- df:默认字段,不指定时会对所有字段进行查询
- sort:根据字段名排序
- from:返回的索引匹配结果的开始值,默认为 0
- size:搜索结果返回的条数,默认为 10
- timeout:超时的时间设置
- fields:只返回索引中指定的列,多个列中间用逗号分开
- analyzer:当分析查询字符串的时候使用的分词器
- analyze_wildcard:通配符或者前缀查询是否被分析,默认为 false
- explain:在每个返回结果中,将包含评分机制的解释
- _source:是否包含元数据,同时支持
_source_includes和_source_excludes - lenient:若设置为 true,字段类型转换失败的时候将被忽略,默认为 false
- default_operator:默认多个条件的关系,AND 或者 OR,默认为 OR
- search_type:搜索的类型,可以为
dfs_query_then_fetch或query_then_fetch,默认为query_then_fetch
在了解了基本的查询参数后,让我们先来看下什么是指定字段查询和什么是泛查询?
比如 GET /movies/_search?q=2012&df=title 这个例子就是指定字段查询,同样 GET /movies/_search?q=title:2012 也可以达到指定字段查询的目的。
再举一个泛查询的例子 GET /movies/_search?q=2012,会对所有字段进行查询。
接下来,看下什么是 Term Query 和 Phrase Query:
比如:Beautiful Mind 等效于 Beautiful OR Mind;"Beautiful Mind"等效于 Beautiful AND Mind,另外还要求前后顺序保存一致。
当为 Term Query 的时候,就需要把这两个词用括号括起来,请求为 GET /movies/_search?q=title:(Beautiful Mind),意思就是查询 title 中包括 Beautiful 或者 Mind。
当为 Phrase Query 的时候就需要用引号包起来,请求为 GET /movies/_search?q=title:"Beautiful Mind"。
另外还支持布尔操作,比如 AND(&&)、OR(||)、NOT(!),需要注意大写,不能小写。
在这里举一个 NOT 的例子:GET /movies/_search?q=title:(Beautiful NOT Mind),这个请求表示查询 title 中必须包括 Beautiful 不能包括 Mind 的文档。
URI Search 还包括一些范围查询和数学运算符号,比如指定电影的年份大于 1994:GET /movies/_search?q=year:>=1994。
URI Search 还支持通配符查询(查询效率低,占用内存大,不建议使用,特别是放在最前面),还支持正则表达式,以及模糊匹配和近似查询。
URI Search 好处就是操作简单,只要写个 URI 就可以了,方便测试,但是 URI Search 只包含一部分查询语法,不能覆盖所有 ES 支持的查询语法。
因此让我们来看下 Request Body Search:
Request Body Search
在 ES 中一些高阶用法只能在 Request Body 里做,所以我们尽量使用 Request Body Search,它支持 GET 和 POST 方式对索引进行查询,需要指定操作的索引名称,同样也要通过 _search 来标明这个请求为搜索请求,我们可以在请求体中使用 ES 提供的 DSL,下面这个例子就是简单的 Query DSL:
POST /users/_search { "query": { "match_all": {} } }
上面的请求的意思就是把所以的结果都返回。
也可以在 Request Body 中加入 from 和 size 参数以达到分页的效果:
POST /movies/_search { "from":10, "size":20, "query":{ "match_all": {} } }
默认 from 从 0 开始,返回 10 个结果,获取靠后的翻页成本较高。
如果想对搜索的结果排序也可以在请求体中加上 sort 参数:
POST /movies/_search { "sort":[{"year":"desc"}], "query":{ "match_all": {} } }
最好在“数字型”与“日期型”字段上排序,因为对于多值类型或者分析过的字段排序,系统会选一个值,无法得知该值。
如果 _source 的数据量比较大,有些字段也不需要拿到这个信息,那么就可以对它的 _source 进行过滤,把需要的信息加到 _source 中,比如以下请求就是 _source 中只返回 title:
POST /movies/_search { "_source":["title"], "query":{ "match_all": {} } }
如果 _source 没有存储,那就只返回匹配的文档的元数据,同时 _source 也支持使用通配符。
接下来介绍下脚本字段,脚本字段可以使用 ES 中的 painless 的脚本去算出一个新的字段结果。
GET /movies/_search { "script_fields": { "new_field": { "script": { "lang": "painless", "source": "doc['year'].value+'_hello'" } } }, "query": { "match_all": {} } }
这个例子中就使用 painless 把电影的年份和 _hello 进行拼接形成一个新的字段 new_field。
在上面我们刚介绍了在 URI Search 中的 Term Query 和 Phrase Query,接下来让我们看下 Request Body 中是怎么做的吧!
在此之前先来插播一条小知识-字段类查询,字段类查询主要包括以下两类:
- 全文匹配:针对 text 类型的字段进行全文检索,会对查询语句先进行分词处理,如 match,match_phrase 等 query 类型
- 单词匹配:不会对查询语句做分词处理,直接去匹配字段的倒排索引,如 term,terms,range 等 query 类型
好了,现在我们来接着往下看。
可以在 Request Body 中使用在 query match 的方式把信息填在里面,我们先来看下 Match Query,比如下面这个例子,填入两个单词,默认是 wupx or huxy 的查询条件,如果想查询两者同时出现,可以通过加 "operator": "and" 来实现。
POST /users/_search { "query": { "match": { "title": "wupx huxy" "operator": "and" } } }
我们通过一张图来看下 Match Query 的流程:

首先对查询语句进行分词,分成 wupx 和 huxy 两个 Term,然后 ES 会拿到 username 的倒排索引,对 wupx 和 huxy 去进行匹配的算分,比如 wupx 对应的文档是 1 和 2,huxy 对应的文档为 1,然后 ES 会利用算分算法(比如 TF/IDF 和 BM25,BM25 模型 5.x 之后的默认模型)列出文档跟查询的匹配得分,然后 ES 会对 wupx huxy 的文档的得分结果做一个汇总,最终根据得分排序,返回匹配文档。
Request Body 中还支持 Match Phrase 查询,但在 query 条件中的词必须顺序出现的,可以通过 slop 参数控制单词间的间隔,比如加上 "slop" :1,表示中间可以有一个其他的字符。
首先对查询语句进行分词,分成 wupx 和 huxy 两个 Term,然后 ES 会拿到 username 的倒排索引,对 wupx 和 huxy 去进行匹配的算分,比如 wupx 对应的文档是 1 和 2,huxy 对应的文档为 1,然后 ES 会利用算分算法(比如 TF/IDF 和 BM25,BM25 模型 5.x 之后的默认模型)列出文档跟查询的匹配得分,然后 ES 会对 wupx huxy 的文档的得分结果做一个汇总,最终根据得分排序,返回匹配文档。
Request Body 中还支持 Match Phrase 查询,但在 query 条件中的词必须顺序出现的,可以通过 slop 参数控制单词间的间隔,比如加上 "slop" :1,表示中间可以有一个其他的字符。
POST /movies/_search { "query": { "match_phrase": { "title":{ "query": "one love" "slop":1 } } } }
了解完 Match Query,让我们再来看下 Term Query:
如果不希望 ES 对输入语句作分词处理的话,可以用 Term Query,将查询语句作为整个单词进行查询,使用方法和 Match 类似,只需要把 match 换为 term 就可以了,如下所示:
POST /users/_search { "query": { "term": { "username":"wupx" } } }
Terms Query 顾名思义就是一次可以传入多个单词进行查询,关键词是 terms,如下所示:
POST /users/_search { "query": { "terms": { "username": [ "wupx", "huxy" ] } } }
另外 DSL 还支持特定的 Query String 的查询,比如指定默认查询的字段名 default_field 就和前面介绍的 df 是一样的,在 query 中也可以使用 AND 来实现一个与的操作。
POST users/_search { "query": { "query_string": { "default_field": "username", "query": "wupx AND huxy" } } }
下面来看下 Simple Query String Query,它其实和 Query String 类似,但是会忽略错误的查询语法,同时只支持部分查询语法,不支持 AND OR NOT,会当作字符串处理,Term 之间默认的关系是 OR,可以指定 default_operator 来实现 AND 或者 OR,支持用 + 替代 AND,用 | 替代 OR,用 - 替代 NOT。
下面这个例子就是查询 username 字段中同时包含 wu 和px 的请求:
{ "query": { "simple_query_string": { "query": "wu px", "fields": ["username"], "default_operator": "AND" } } }
到此为止,我们就对 DSL 做了个简单介绍,更高阶的 DSL 会在以后的文章中进行介绍。
然后,我们来看下请求后返回的结果 Response 长什么样吧!
Response
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 0.9808292, "hits" : [ { "_index" : "users", "_type" : "_doc", "_id" : "1", "_score" : 0.9808292, "_source" : { "username" : "wupx", "age" : "18" } } ] } }
其中 took 表示花费的时间;total 表示符合条件的总文档数;hits 为结果集,默认是前 10 个文档;_index 为索引名;_id 为文档 id;_score 为相关性评分;_source 为文档的原始信息。
搜索的相关性(Relevance)
那么我们平时在搜索的时候,比如输入小米手机,会返回很多结果,从用户角度关心的有:是否找到所有相关的内容,有多少不相关的内容被返回了,比如输入的小米手机的时候不应该返回粮食的小米给用户,同时文档应该按照打分的方式进行排序,也就是搜索结果中的 _score,另外,搜索引擎需要结合业务需求,平衡结果排名。
如何评估相关性?
在信息检索学中对相关性是有指标去评估的,第一个是查准率(Precision),具体含义是尽可能返回较少的无关文档给用户;第二个为查全率(Recall),也就是尽量返回较多的相关文档;第三个为是否能够按照相关度进行排序(Ranking)。
下面通过一张图来对查准率和查全率有一个更形象的理解:
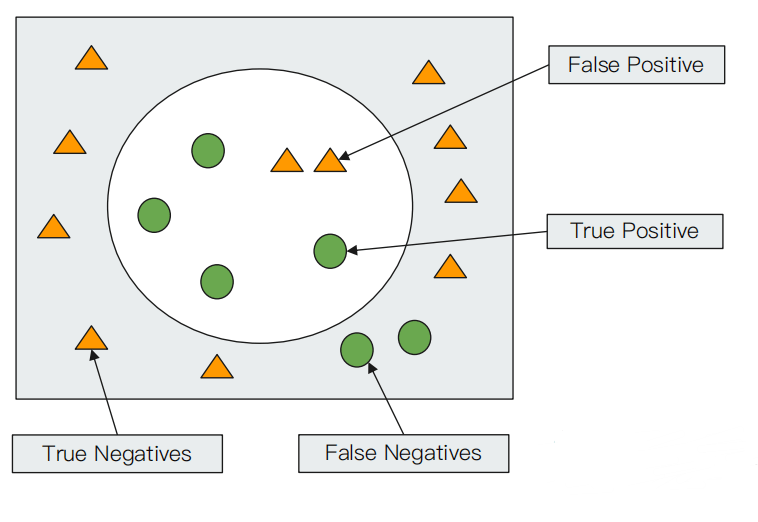
其中黄色的三角形代表不相关的内容,绿色的圆代表相关的内容;在搜索结果中,黄色的三角形起名为 False Positive(纳伪,简写 fp),通常称作误报,绿色的圆起名为 True Positive(纳真,简写 tp);在没有被搜索到的范围中,绿色的圆的起名为 False Negatives(去真,简写 fn),也常称作漏报,黄色的三角形起名为 True Negative(去伪,简写 tn)。
那么我们可以得到:
- 查准率等于正确的搜索结果除以全部返回的结果,即 Precision = tp / ( tp + fp )
- 查全率等于正确的搜索结果除以所有应该返回的结果,即 Recall = tp / ( tp + fn )
在 ES 中提供了许多的查询相关参数来改善搜索的 Precision 和 Recall。
总结
本文主要简单介绍了 ES Search API 的两种形式,学习了 URI Search 的基本方法,还学习了 Term Search 和 Phrase Search 的区别,同时介绍了什么叫搜索相关性,以及如何评估相关性。
参考文献
《Elasticsearch技术解析与实战》
Elastic Stack从入门到实践
Elasticsearch顶尖高手系列
Elasticsearch核心技术与实战
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search.html