MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度那么,mapTask并行实例是否越多
越好呢?其并行度又是如何决定呢?Mapper数量由输入文件的数目、大小及配置参数决定;
MapReduce将作业的整个运行过程分为两个阶段:Map阶段Reduce阶段。
Map阶段由一定数量的Map Task实例组成,例如:
- 输入数据格式解析:InputFormat
- 输入数据处理:Mapper
- 本地规约:Combiner(相当于local reducer,可选)
- 数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task实例组成,例如:
- 数据远程拷贝
- 数据按照key排序
- 数据处理:Reducer
- 数据输出格式:OutputFormat
1.MapReduce的Map阶段:
1.1.从HDFS读取数据:
一个job的Map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据
划分成逻辑上的多个split),然后每一个split分配一个MapTask并行实例处理,即就是到底启动多少个MapTask实例就意味着将
数据切成多少份(一个切片对应一个MapTask实例)
切片逻辑及形成的切片规划List描述文件,由 FileInputFormat 实现类的getSplits()方法完成:流程如下:
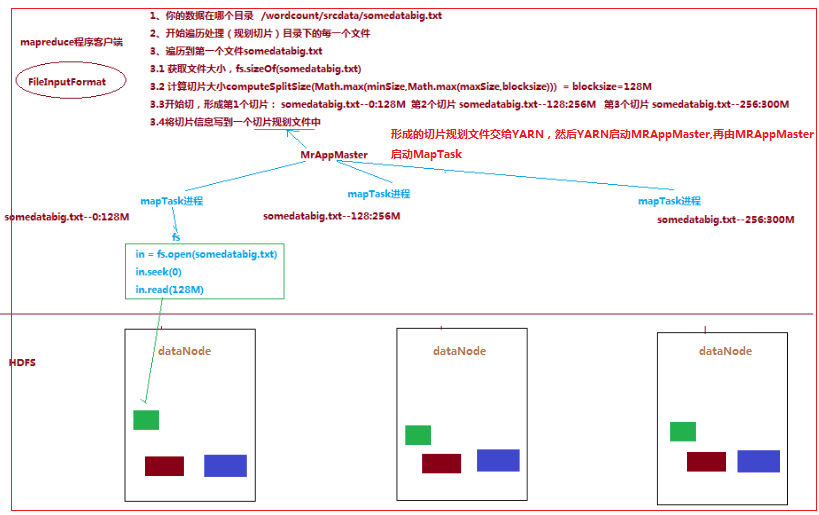
1.1.1.FileInputFormat中默认的切片机制:
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128 file1.txt.split2-- 128~256 file1.txt.split3-- 256~320 file2.txt.split1-- 0~10M
1.1.2.FileInputFormat中切片大小的参数配置:
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定
|
minsize:默认值:1 配置参数: mapreduce.input.fileinputformat.split.minsize |
|
maxsize:默认值:Long.MAXValue 配置参数:mapreduce.input.fileinputformat.split.maxsize |
|
blocksize |
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
1.5 ReduceTask并行度的决定
ReduceTask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量
的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reducetask。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小
这个对于小集群而言,尤其重要。