1.1.倒排索引
根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确
定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(invertedindex)
例如:单词——文档矩阵(将属性值放在前面作为索引)
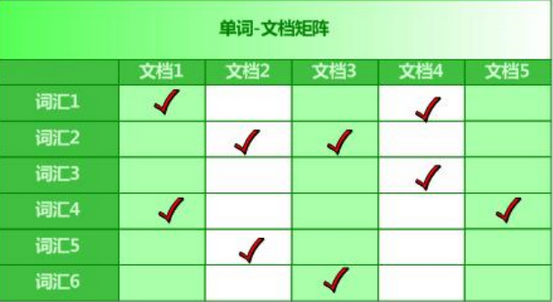
1.2.MapReduce实现倒排索引
需求:对大量的文本(文档、网页),需要建立搜索索引
代码实现:
package cn.bigdata.hdfs.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 使用MapRedeuce程序建立倒排索引文件 * 文件列表如下: * a.txt b.txt c.txt * hello tom hello jerry hello jerry * hello jerry hello jerry hello tom * hello tom tom jerry */ public class InverIndexStepOne { static class InverIndexStepOneMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); //将得到的每行文本数据根据空格" "进行切分 String [] words = line.split(" "); //根据切片信息获取文件名 FileSplit inputSplit = (FileSplit)context.getInputSplit(); String fileName = inputSplit.getPath().getName(); for(String word : words){ k.set(word + "--" + fileName); context.write(k, v); } } } static class InverIndexStepOneReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values ,Context context) throws IOException, InterruptedException { int count = 0; for(IntWritable value : values){ count += value.get(); } context.write(key, new IntWritable(count)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(InverIndexStepOne.class); job.setMapperClass(InverIndexStepOneMapper.class); job.setReducerClass(InverIndexStepOneReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //输入文件路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
运行结果输出文件:E:inverseOutpart-r-00000
hello--a.txt 3 hello--b.txt 2 hello--c.txt 2 jerry--a.txt 1 jerry--b.txt 3 jerry--c.txt 1 tom--a.txt 2 tom--b.txt 1 tom--c.txt 1
在原来的基础上进行二次合并,格式如上图单词矩阵,代码实现如下:
package cn.bigdata.hdfs.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 对第一次的输出结果进行合并,使得一个value对应的多个文档记录组成一条完整记录 * @author Administrator * */ public class IndexStepTwo { static class IndexStepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] files = line.split("--"); context.write(new Text(files[0]), new Text(files[1])); } } static class IndexStepTwoReducer extends Reducer<Text, Text, Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //定义Buffer缓冲数组 StringBuffer sb = new StringBuffer(); for (Text text : values) { sb.append(text.toString().replace(" ", "-->") + " "); } context.write(key, new Text(sb.toString())); } } public static void main(String[] args) throws Exception{ if (args.length < 1 || args == null) { args = new String[]{"E:/inverseOut/part-r-00000", "D:/inverseOut2"}; } Configuration config = new Configuration(); Job job = Job.getInstance(config); job.setMapperClass(IndexStepTwoMapper.class); job.setReducerClass(IndexStepTwoReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 1:0); } }
运行结果:
hello c.txt-->2 b.txt-->2 a.txt-->3 jerry c.txt-->1 b.txt-->3 a.txt-->1 tom c.txt-->1 b.txt-->1 a.txt-->2
总结:
对大量的文档建立索引无非就两个过程,一个是分词,另一个是统计分词在每个文档中出现的次数,根据分词在每个文档
中出现的次数建立索引文件,下次搜索词的时候直接查询索引文件,从而返回文档的摘要等信息;