The scheduler of Hadoop
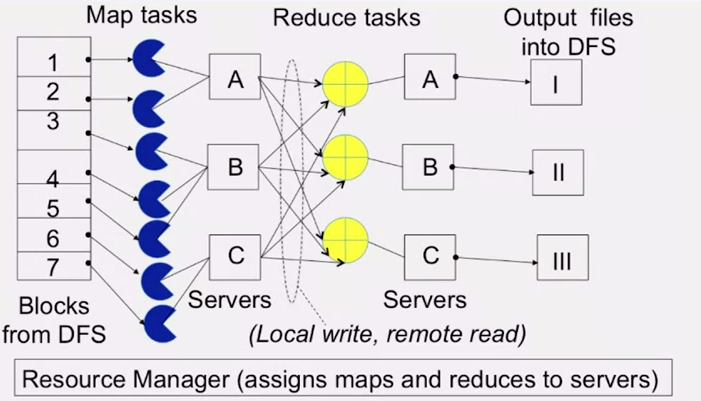
Programming MapReduce

在有些情况下,reducer也可以先开始于Map.但为了便于理解,在这儿我们都是使reduce不会早于map发生
the traffic that data from map to reduce is called shuffle traffic,这些shuffle traffic可以并行运行(map task还在运行), shuffle phase可以与map phase并行运行.一旦
shuffle phase结束,则reduce phase可以开始了.
Inside MapReduce

map的input数据是存储在distributed file system中的.
map的output放在map task运行的本地机器上(local disk),这些数据不是被用户需要的,它们只是被reduce阶段需要,为了不增加distributed file system的负载(因为它们可能会在Distributed file system中被复制),这样就可以加快reduce task取数据的速度。
Reduce阶段结束后,数据会被存储回distributed file system中
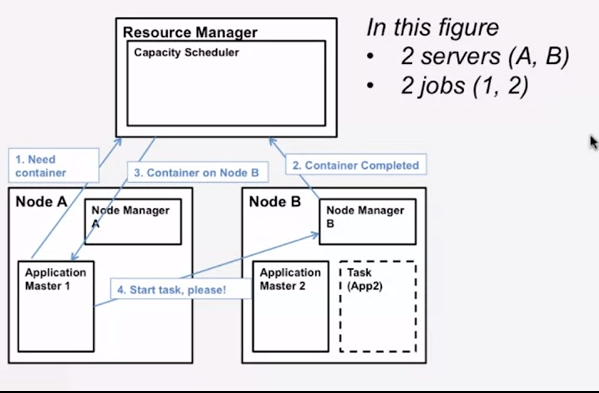
The YARN schedular(Hadoop 2.x +)

如果一个server有4个cores,4 gigabytes RAM,若每个container有一个core,1 gigabyte of RAM,则这个server有4个containers,可以运行4个tasks
只有一个global resource manager,每个server都有一个node managert,1个job有一个AM(application master)在其中一台server上.
YARN:一个job怎么得到container