org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor
以下所有源码均在此类中
首先我们看下log4j2异步队列的初始化

从这里面我们可以看到,使用的是单例的线程池,这里请注意,这个线程池里定义的是后台线程

并且对于线程池的实现我们不可以自定义配置,是写死的,为什么要这样做呢?原因是为了保证日志的顺序性.
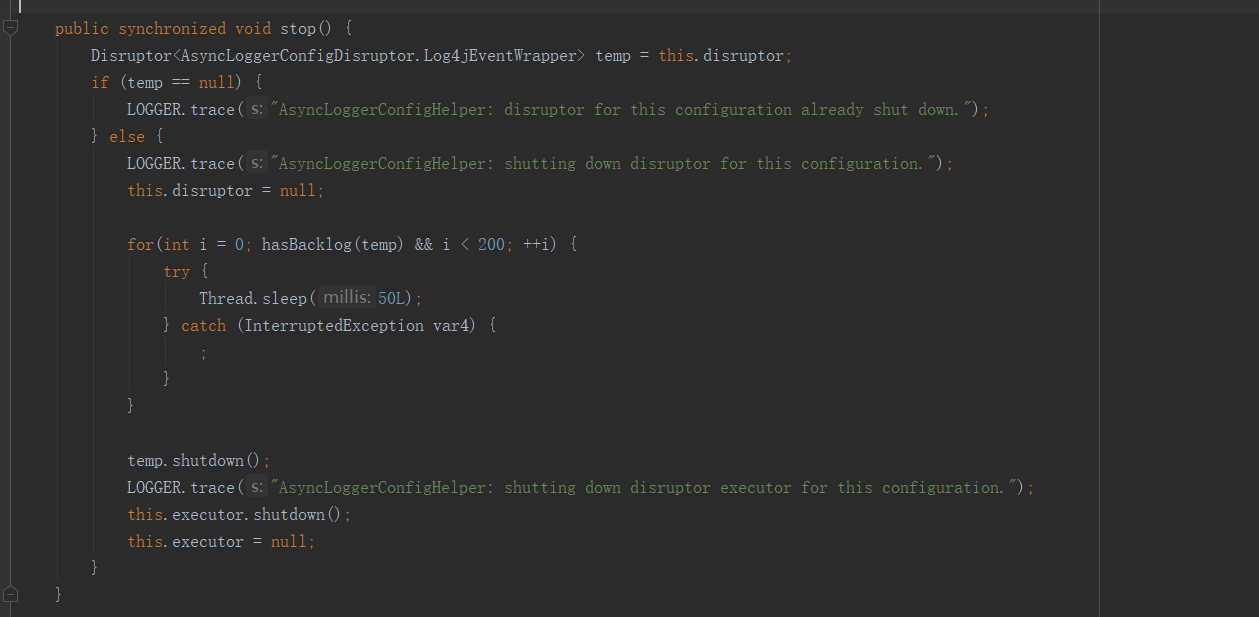
而在stop()方法也就是服务关闭的处理逻辑里,将循环条件设置为(队列不为空&&次数<200次),每次则将线程休眠50毫秒,为什么要这样做呢?这是为了拖延jvm的关闭,因为我们的线程池使用的是后台线程,所以刷日志线程也不会延长jvm的生命周期,因此需要一个前台线程保证jvm不会马上关闭
说完这个,再说说Discuptor那边的消费者阻塞策略,因为消费者并不是直接操作RingBuffer的,而是通过ConsumerBarrier对象间接地操作RingBuffer。像生产者一样,Consumer要知道它的下一个读取需要才能读取。Consumer并不是一个个地读取数据,而是批量读取,举个栗子:如果它处理完了6号slot以前的数据,那么接下来它期待处理7号slot。ConsumerBarrier返回RingBuffer的最大可访问序号,假如是10。如果7号以后的slot还没有数据,那么它会根据ConsumerBarrier里面的WaitStrategy策略进行等待,直到生产者生产完数据。同时,生产者每次生产完一个数据之后都会通知Consumer,而不是Consumer每次都去询问。直到生产完10号slot的数据之后,Consumer才会一次性读取几个slot的数据,然后才更新自己的cursor。
它们分别是
Block:阻塞等待
Timeout: 使用LockSupport的parkNanos()方法来睡眠,好处是在睡眠的时候不会浪费CPU,坏处是因为是定时睡眠,所以会导致延迟较大
Yield: 空转调用Thread.yield(),让出CPU资源给其它线程,但是自己依然会去抢时间片,这个是最及时的
Sleep: 是一种混合方式,先开始spin(CPU空转),之后没有就绪就 Thread.yield(),在之后就会block,这个算是最佳方案吧
关于这个如何设置

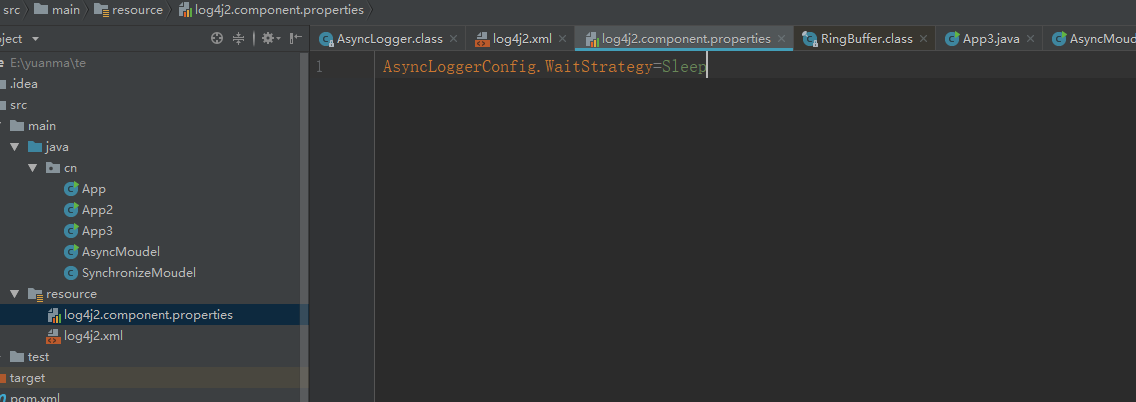
根据源码分析到要在classpath下建立一个这个名字的文件,然后写上这样的属性

如下图:
我们再说说队列满的情况下的拒绝策略吧
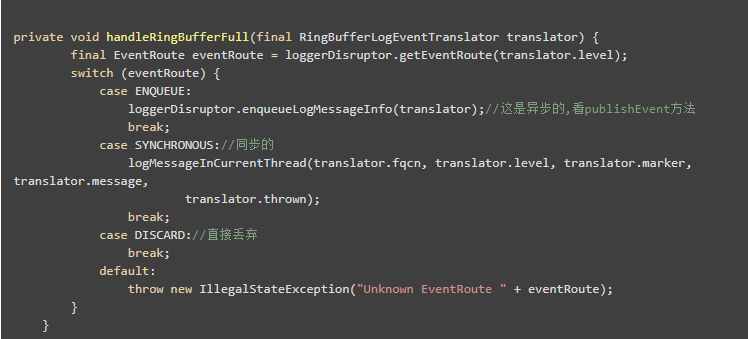
就是这三种,第一种的意思是,继续异步线程调用排队,第二种的意思是,阻塞当前线程等待,第三种就是丢弃
我们可以这样子指定

或者按照官网说的这样做就行
