一、ES一些概念
索引
_inde,文档存储的地方,类似于关系型数据中的数据库。
事实上,数据被存储和索引在分片中,索引仅仅是一个把一个或者多个分片分组在一起的逻辑空间。 索引名字必须是全部小写,不允许以下划线开头,不能包含逗号。
文档
文档id是一个字符串,与_index组合时,就可以在ElasticSearch中唯一标识一个文档。创建文档时,可以自定义_id,也可以让ES帮助自动生成。
二、使用postman入门学习
- 创建索引
创建索引库的格式为:使用put请求:ip:9200/{index}
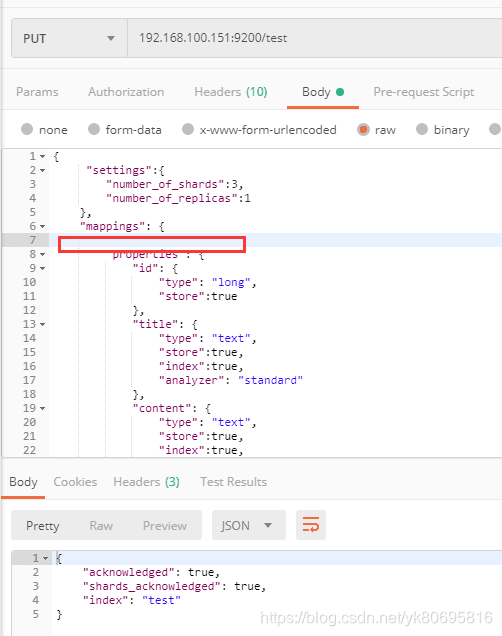
在ES7之前红框里面是可以指定type的,现在是不需要的可以使用默认的_doc为type,看到有的文档上面说type会在8.x里面彻底移除。
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings": {
"properties": {
"id": {
"type": "long",
"store":true
},
"title": {
"type": "text",
"store":true,
"index":true,
"analyzer": "standard"
},
"content": {
"type": "text",
"store":true,
"index":true,
"analyzer": "standard"
}
}
}
}
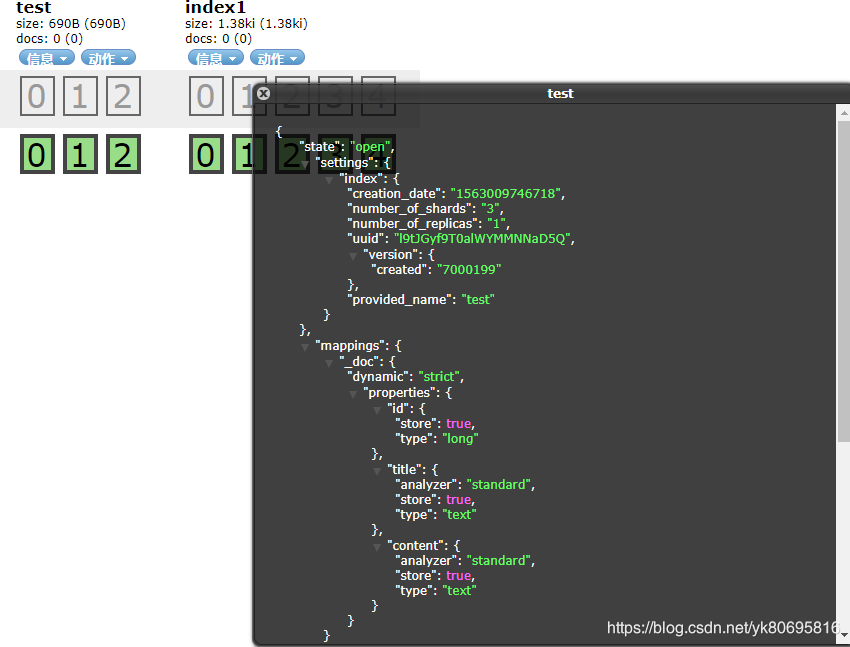
number_of_shards是用来设置分片数量的,number_of_replicas是用来设置副本数量的。在properties里面增加自己的字段,并且指定属性的类型
-
删除索引
格式:DELETE IP:9200/{index} -
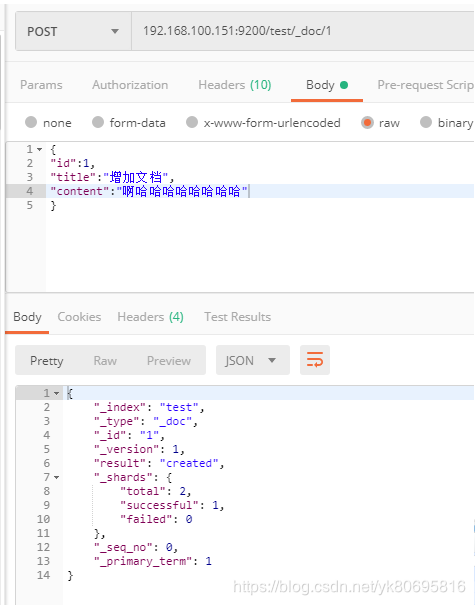
创建文档和修改文档
插入文档格式:PUT(POST) IP:9200/{index}/_doc/id 指定文档ID
POST IP:9200/{index}/_doc 随机ID

-
修改文档
格式: POST IP:9200/{index}/_doc/文档ID
其实和新增差不多,是先删除原有的在新增。 -
删除文档
格式:DELETE IP:9200/{index}/_doc/文档ID -
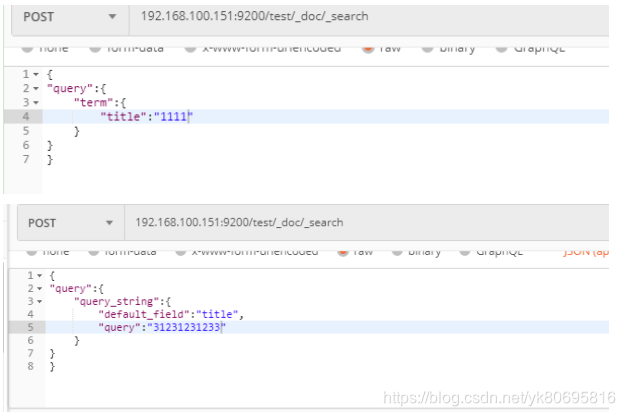
文档查询
格式:GET IP:9200/{index}/_doc/文档ID
格式:POSTIP:9200/{index}/_doc/_search
三、分词器
- 标准分词器

可以看到标准的分词器对中文处理的并不是很好
- IK分词器
1.下载地址https://github.com/medcl/elasticsearch-analysis-ik/releases
2.在/plugins下面创建一个文件夹名为ik,然后将下载好的分词器通过ftp传入ik文件夹下面,并解压
3.重启ES
IK分词器有两种算法,ik_smart(粗粒度的拆分)和ik_max_word(细粒度的拆分)
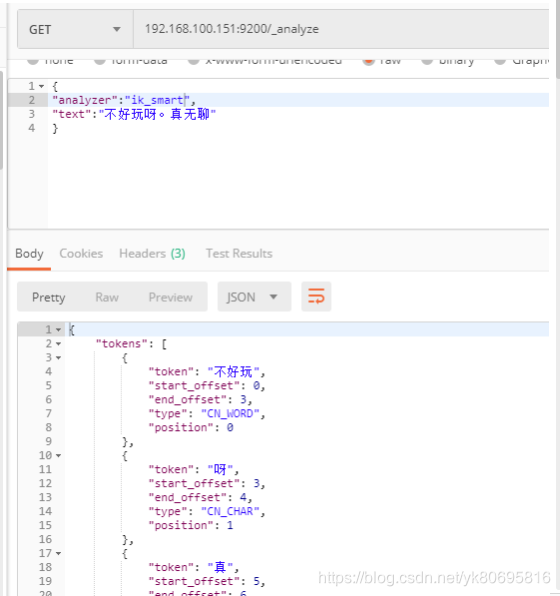
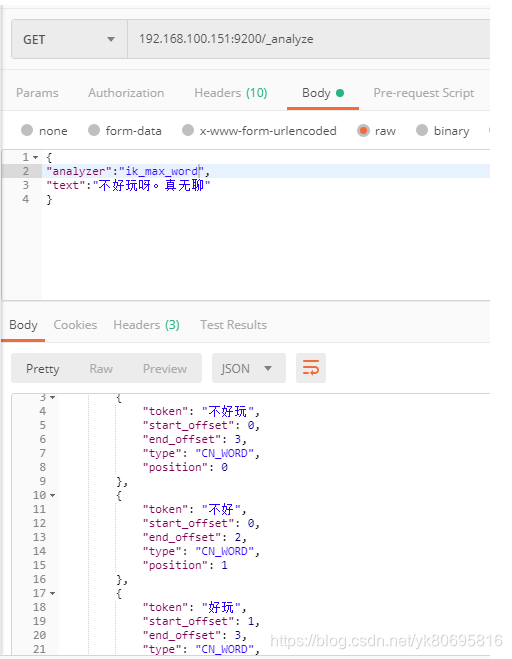
自定义词库
需要在IKAnalyzer.cfg.xml里面配置扩展的词典就OK了

不过词典的文件格式格式为utf-8(不要选择utf-8 BOM)