autoencoder可以用于数据压缩、降维,预训练神经网络,生成数据等等。
autoencoder的架构
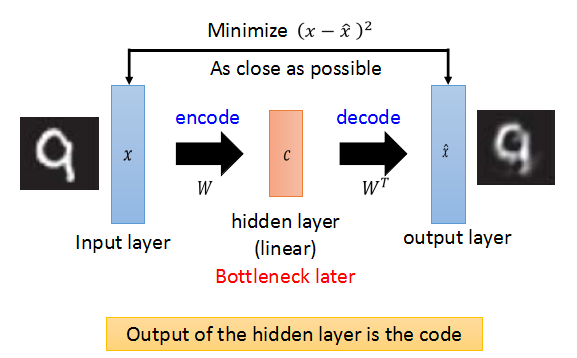
autoencoder的架构是这样的:
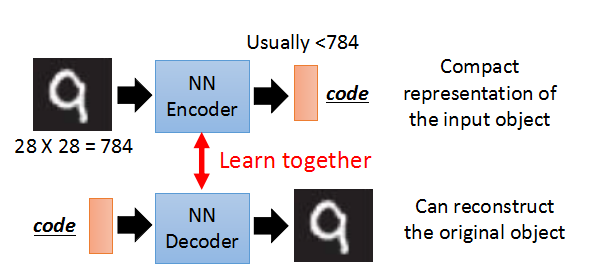
需要分别训练一个Encoder和一个Decoder。
比如,一张数字图片784维,放入Encoder进行压缩,编程code,通常要小于原来的784维;
然后可以将压缩后的code,放入Decoder进行reconsturct,产生和原来相似的图片。
Encoder和Decoder需要一起进行训练。
下面看看PCA对于数据的压缩:
输入同样是一张图片,通过选择W,找到数据的主特征向量,压缩图片得到code,然后使用W的转置,恢复图片。
我们知道,PCA对数据的降维是线性的(linear),恢复数据会有一定程度的失真。上面通过PCA恢复的图片也是比较模糊的。
所以,我们也可以把PCA理解成为一个线性的autoencoder,W就是encode的作用,w的转置就是decode的作用,最后的目的是decode的结果和原始图片越接近越好。
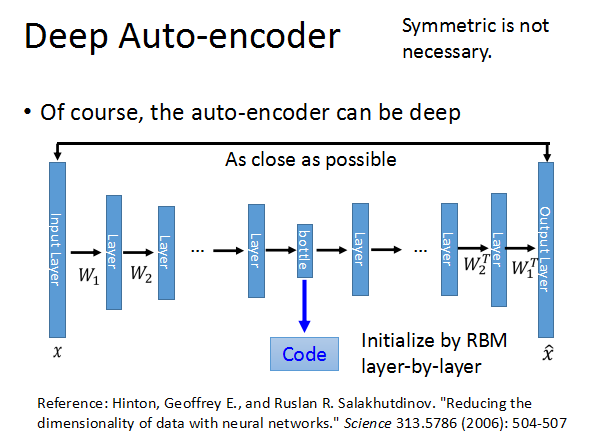
现在来看真正意义上的Deep Auto-encoder的结构。通常encoder每层对应的W和decoder每层对应的W不需要对称(转置)。
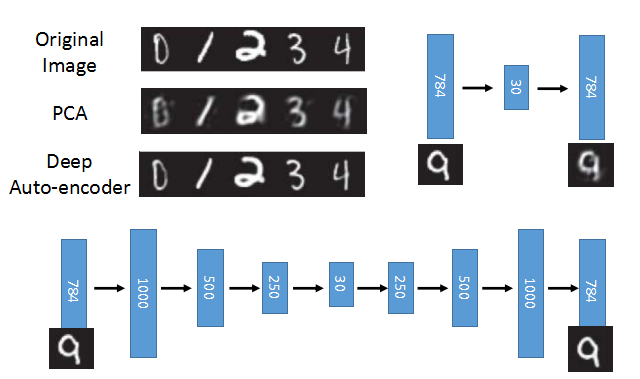
从上面可以看出,Auto-encoder产生的图片,比PCA还原的图片更加接近真实图片。
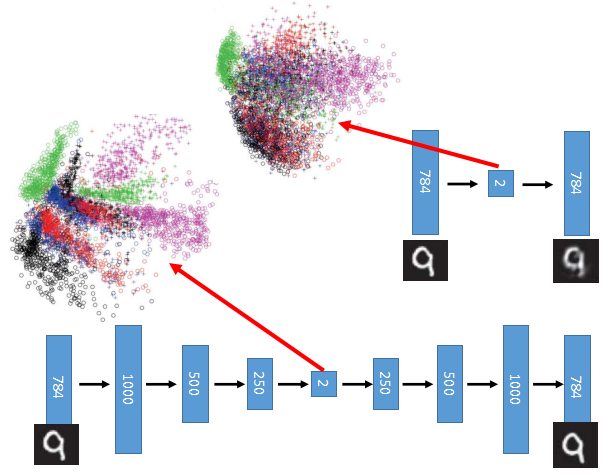
上面是使用PCA和autoencoder对于数字图片压缩后的可视化结果,明显autoencoder的区分度更高。
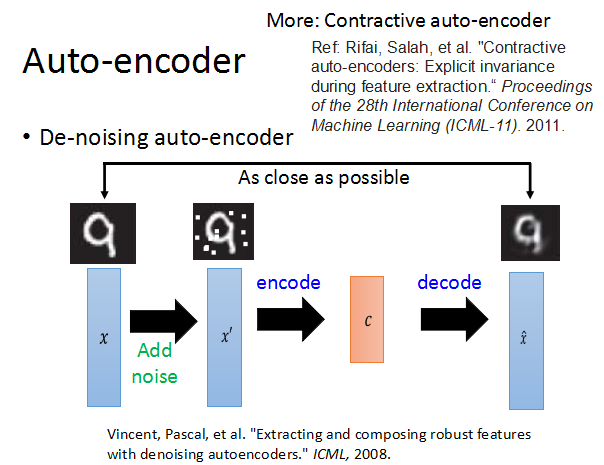
De-noising auto-encoder
为了让aotoencoder训练的更好,更加robust,我们在训练的时候加入一些noise,这就是De-noising auto-encoder。
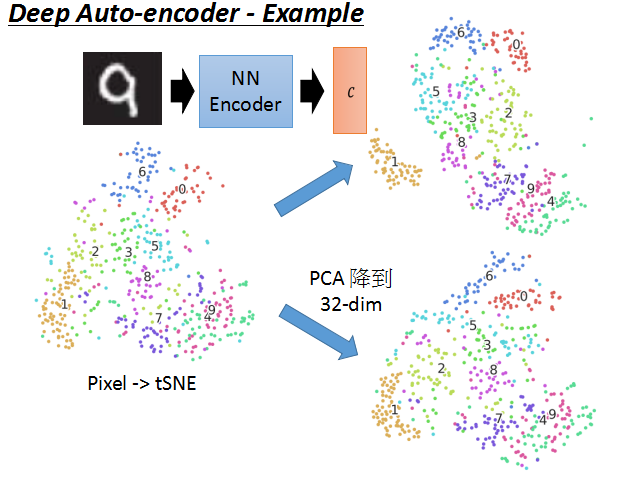
examples
接下来再看两个例子。
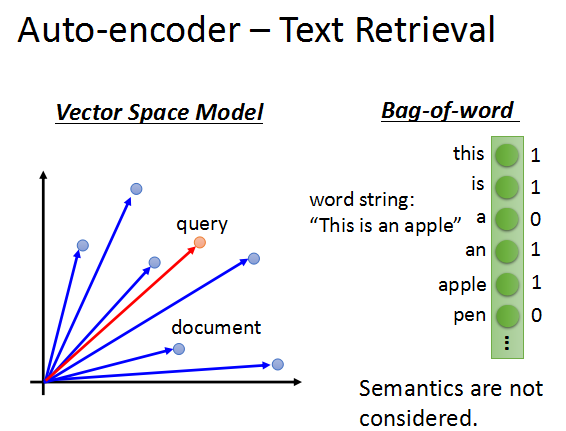
文本检索,简单的词袋模型,将文本转化成词向量。
当搜索的词和文本向量角度越接近,就说明内容越相关。
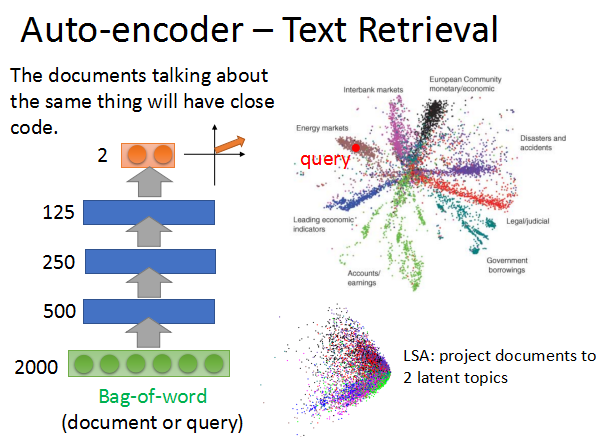
将词向量放入autoencoder中进行压缩,得到code,内容相近的文本,code也越接近。
不同主题的文本被明显的分开,得到右上的2维图像。
搜索图片的相似性。
搜索红框中的迈克杰克逊的照片,下面是使用像素点之间的欧式距离得到的搜索结果。

下面使用autoencoder编码后的code,进行相似性的搜索结果。


使用CNN实现autoencoder
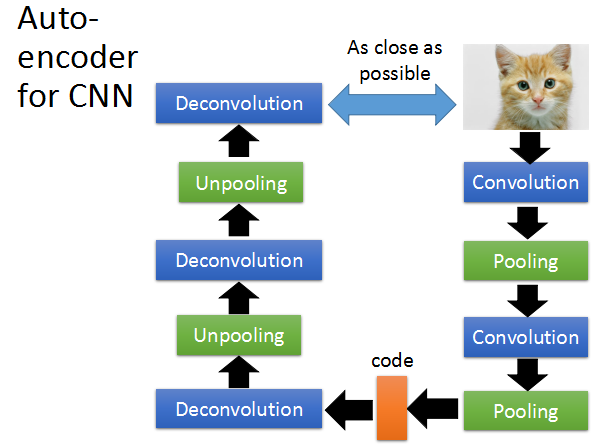
经过多次convolution和pooling后的code,可以再经过deconvolution和unpooling恢复。
下面将如何实现unpooling和deconvolution。
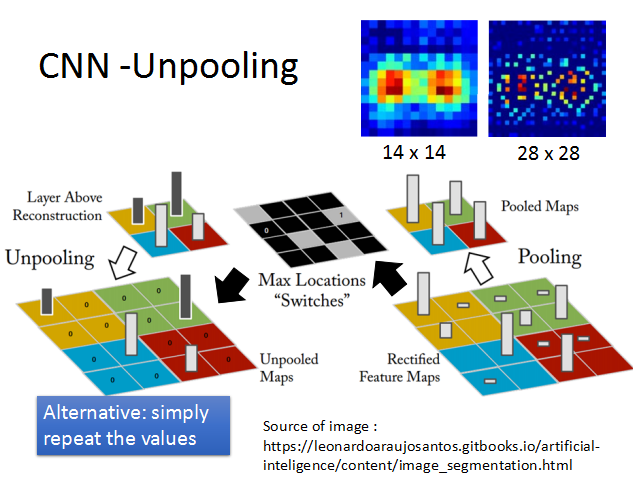
在maxpooling时,需要记住max值在图片中的位置。
当进行unpooling时,把小的图片做扩展,先把max值恢复到之前的位置,然后在之前进行maxpooling的field内的像素都置为0.
接下来看Deconvolution
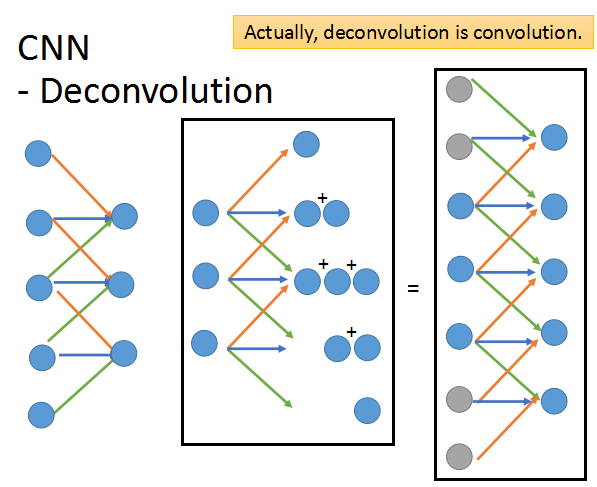
现在假设一个field里面有3个像素点,每个filter的3个weight作用下得到一个output,如图左。
而deconvolution就是要让这3个output复原成原来那么多的点,一个output变成3各点,把重叠的点加起来,如图中。
现在,将3个output进行扩展,给扩展的点的值为0,然后就依然做convolution,还是可以得到和图中相同的结果。
所以,deconvolution其实就是convolution。
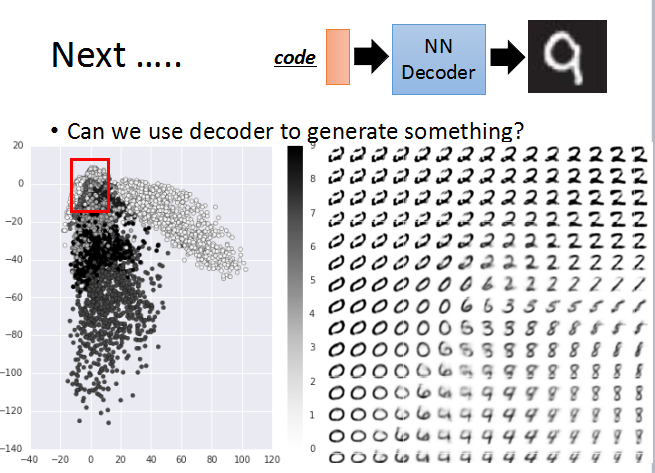
最后,我们可以使用autoencoder压缩后的code,输入到decoder里,得到一张新的图像,如下所示。