参考博客:http://www.cnblogs.com/284628487a/p/5584714.html
首先,你需要知道的就是ASCII、unicode、utf-8、gbk等都属于编码格式,他们都是将文字转化为bytes类型,
bytes的取值范围为0-255,你也可能看到b'xe6xb5x8‘这种格式,其实也属于bytes类型,对应的数字分别是230181139,
之后,你再将byte类型转化为二进制,也就是后面这样0b11100110�b10110101�b10001011的形式,这样就属于机器码了。
在unicode之前,用的都是ASCII。ASCII码非常简单,每个英文字符都以7位二进制的方式存储在计算机内,其范围是32~126。
ASCII编码的文件小巧易读。一个程序只需要简单的把文件的每个字读出来,把对应的数值转换成字符显示出来就可以了。
但是ASCII字符只能表示95个可打印字符,后来软件厂商把ASCII扩展到了8位,这样ASCII就可以表示223字符了。但是这对非英语文字的地区来说肯定是不够的。
为了解决全球化的文字性问题,就创建了万国码,即unicode。
unicode通过是用一个或多个字节来表示一个字符的方法突破了ACSII的限制。
unicode在很长一段时间内无法推广,直到互联网的出现。为解决unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。UTF-8就是在互联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。
ASCII:一个英文占1个字节,没有中文。
unicode(定长2):在python2中一个中文占两个字节,一个英文占两个字节。
(定长4)在python3中,一个中文占四个字符,一个英文也占四个字节。
GBK(定长2):使用两个字节编码,一个中文占两个字节,一个英文也占两个字节。
utf-8:变长,一个中文占三个字节,一个引文占一个字节,字符长都可以在1-4之间流动。
utf-16:也是一种边长编码,但是并不能向后兼容ASCII,使用较少。
不同的编码之间不能相互识别,会产生乱码
unicode由于太占内存,因此默认存储和传输都是用的utf-8、gbk等方式,但绝对不是unicode
再python3中,汉字默认使用utf-8,英文和数组默认使用ASCII的编码方式。
print(chardet.detect('abc123'.encode())) #{'encoding': 'ascii', 'confidence': 1.0, 'language': ''} print(chardet.detect('测试'.encode())) #{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}
因此unicode模式的文件必须转换
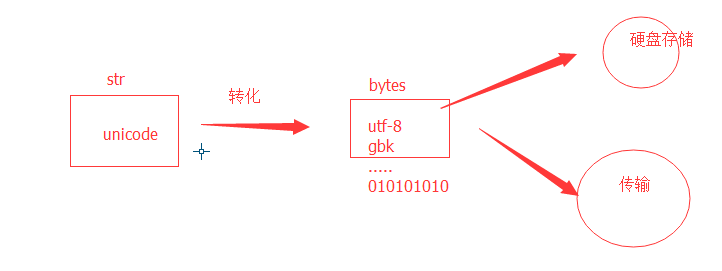
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8或gbk编码。
用记事本编辑的时候,从文件读取的UTF-8或着gbk字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8或gbk保存到文件:
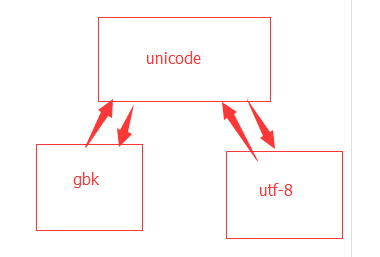
不同编码之间的转化
gkb——》unicode《——utf8,因为unicode是万国码,因此gbk和unf-8能够与Unicode直接转化
但是gbk和utf-8之间就不能直接转了,必须要有过度 gkb——》unicode——》utf-8
下面这个函数可以查询python默认的编码方式
python2 >>> import sys >>> sys.getdefaultencoding() 'ascii' python3 >>> import sys >>> sys.getdefaultencoding() 'utf-8'
在python2中,如果你在编写代码的时候在文件开头没有指定编码格式,类似下面这样:
#coding:utf-8
那么程序就会直接报错:
SyntaxError: Non-ASCII character 'xe6' in file F:/py_test_dir/test_code/venv/test_code/encode_test.py on line 6, but no encoding declared;
总之在python2中,编码是一个大问题。
decode解码是将其解码称为unicode,
因此在window和linux下面,decode的方式不一样,一个是使用GB2312,另一个是utf-8.
而encode必须是基于unicode的对象,因此在python2下面,编码之前先要解码,但是在python3中就统一成了unicode,不论你在那个平台。