一、思想
聚类:人以群分、物以类聚,使得簇内的距离接近,簇间距离远。
可以做推荐冷启动,区域推荐热榜、用户画像
二、算法步骤:
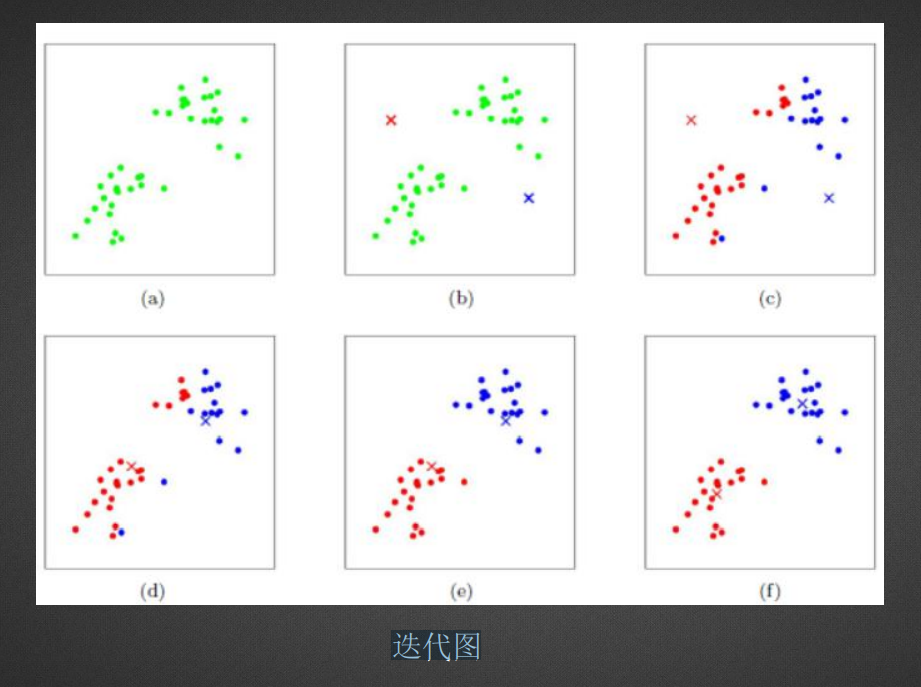
- 1、随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,从中选出距离最近的⼀个点作为⾃⼰的标记
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值或切尾均值)
- 4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步
如何排除初始值落在异常值的影响:
可以把数据分为K堆,对每一堆都排序,去掉最小的和最大的25%,取中间的50%的数据取均值作为初始的聚类中心
三、优缺点:
优点:
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k
缺点:
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感
四、评估指标



参考:1、非监督学习-k-means