计算与软件工程 作业4
| 作业要求 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 课程目标 | 完成简单软件功能的开发,会对简单代码进行审核,学会结对编程,和队友搭档一起开发新的功能,会对代码进行单元测试等,分析代码的利用率 |
| 实现自我目标 | 主要和队友搭档完成程序开发,进行代码复审,简单修改代码挺高代码利用率 |
| 参考文献 | https://blog.csdn.net/weixin_44396540/article/details/88085543 https://blog.csdn.net/lbj1260200629/article/details/89600055https://jingyan.baidu.com/article/4f34706e11e052e387b56dd2.html https://jingyan.baidu.com/album/f96699bbeeda8d894e3c1b8d.html?picindex=4 https://www.cnblogs.com/lsdb/p/9201029.html https://www.cnblogs.com/xinz/archive/2011/11/20/2255971.html https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html |
| 作业正文 | https://www.cnblogs.com/yangqiuyan/ |
课前阅读阶段:
讲义3 结对编程(Pair Programming)和两人合作
https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html
结对编程形式:
在结对编程模式下,一对程序员肩并肩地、平等地、互补地进行开发工作。两个程序员并排坐在一台电脑前,面对同一个显示器,使用同一个键盘,同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起单元测试,一起集成测试,一起写文档等。
结对编程优点:(结对编程能得到更高的投入产出比)
(1)在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作能有更强的解决问题的能力。
(2)对开发人员自身来说,结对工作能带来更多的信心,高质量的产出能带来更高的满足感。
(3)在心理上, 当有另一个人在你身边和你紧密配合, 做同样一件事情的时候, 你不好意思开小差, 也不好意思糊弄。
(4)在企业管理层次上,结对能更有效地交流,相互学习和传递经验,能更好地处理人员流动。因为一个人的知识已经被其他人共享。
复审阶段:
开发中的复审主要包括:设计复审、代码复审、测试计划复审、文档复审。
| 复审 | 问题 |
|---|---|
| 复审出现的问题 | a. 复审人缺乏对程序的深入了解,降低了复审的效果; b. 不能持久、定时地进行复审; c. 对需求和设计的不了解导致无法实现全面有效的复审。 |
| 团队复审的缺点 | a. 什么时候开会做复审?不可能一个团队天天开会。要找到一个所有人都能出席的时间,并不容易; b. 牵涉的人员众多,理解程度不一,复审的速度和效果不能得到有效的平衡——太快则有人不懂,太慢则浪费许多人的时间; c. 正是由于成本问题,无法对所有的设计和代码进行深入的复审; d. 由于人员众多,有面子问题。 |
两人合作的不同阶段:
1.萌芽(Forming)
2.磨合阶段(Storming)
3.规范阶段(Norming)
4.创造阶段(Performing)
5.解体阶段(Deforming)
课后作业阶段:
作业一:(作业互评)
1.https://www.cnblogs.com/lazycat777/p/12483269.html
代码风格:代码未按照固定格式进行缩进,括号未加在同一的位置上,函数的取名符合代码风格与规范,有大小写分辨。但不能很好地添加注释,没办法很好的进行代码复用。
代码设计:函数表达式明确,定义完整。头文件并不完整,且该函数的测试每一次的数组输入都需要在主函数中重新定义,利用率很低。输出的数组最大子数组和的开始与结束位置与平时习惯并不相同。主要是从0开始计数,而不是1。
2.https://www.cnblogs.com/parida/p/12469460.html
代码风格:代码设计严格按照代码设计格式进行书写,有缩进,有严格的括号书写。对于类及函数的命名也可按照要求合理给出,大小写安排合理。但注释方面没有很好地给出有提示性的参照,不利于代码复用和读取。
代码设计:函数可以明确给出代码循环,思路明确,但是并没有实现出显示最大子数组和的开始和结尾的位置。且并没有对代码进行单元测试,不知道代码的利用率。
3.https://www.cnblogs.com/hxf98/p/12483784.html
代码风格:代码未按照固定格式进行缩进,括号未加在同一的位置上,函数的取名符合代码风格与规范,有大小写分辨。可以较好地添加注释,程序比较容易读懂。
代码设计:函数表达式明确,定义完整。但该函数的测试每一次的数组输入都需要在主函数中重新定义,利用率低。输出的数组是最大子数组但是不是要求中的子数组开始与结束的位置。
4.https://www.cnblogs.com/zxy123456/p/12449427.html
代码风格:代码设计严格按照代码设计格式进行书写,有缩进,有严格的括号书写。对于类及函数的命名也可按照要求合理给出,大小写安排合理。人机交互方面也很友好,但注释方面没有在每一个函数或类处很好地给出有提示性的参照,不利于代码复用和读取。
代码设计:函数表达式明确,定义完整,分块明确,可以很好地展现出数组中的各个属性和性能,代码整体性和完整性很高。测试代码也很完整,可以明确看到代码运行率。
5.https://www.cnblogs.com/yuhanzhou/p/12361161.html
代码风格:代码设计严格按照代码设计格式进行书写,有缩进,有严格的括号书写。对于类及函数的命名也可按照要求合理给出,大小写安排合理。人机交互方面也很友好,可以实现非常复杂的功能。虽然没有太多注释,但由于输出汉字较多,故在代码功能理解方面很好地给出了信息提示,比较利于代码读取。
代码设计:功能非常全面,但是无法实现一次生成多道题目,并进行总体批改,给出正确率的统计。另外在代码编写方面简单易懂,但是很多代码重复率很高,if循环里的东西很多单重复,可以考虑用分支语句进行改写,提高代码每一句的利用率。
6.https://www.cnblogs.com/hyjlove/p/12367291.html
代码风格:截图中的代码部分很好地遵循了代码编程的各个要求,但在后面附上的代码中没有做好格规范,给代码的读取造成了小小的不便利。代码注释虽然不多,但是会有很多提示语句,对代码复用影响不大。
代码设计:程序功能很完整,可以满足不同难度的选择(以加入运算符的多少决定),但是无法一次性给出多道题目并统一给出正确率。而在人机交互方面做得很好,提示语句到位,可以给多个选择。
7.https://www.cnblogs.com/wanghuiru/p/12460279.html
代码风格:代码设计严格按照代码设计格式进行书写,有缩进,有严格的括号书写。对于类及函数的命名也可按照要求合理给出,大小写安排合理。人机交互方面也很友好,可以实现非常复杂的功能。虽然没有太多注释,但由于输出汉字较多,故在代码功能理解方面很好地给出了信息提示,比较利于代码读取。
代码设计:代码整体完整度很高,可以基本满足小学生学习的要求。但是在代码中重复段落较多,很多代码是重复的,可以考虑适当简化。测试代码部分分开实行,也看到代码的利用率。正常情况下代码效率达到百分之70到90,可以很好地执行原来的功能,太低则不行,所以可以进一步对代码进行修改。
8.https://www.cnblogs.com/shixiaomao12138/p/12404101.html
代码风格:代码设计严格按照代码设计格式进行书写,有缩进,有严格的括号书写。对于类及函数的命名也可按照要求合理给出,大小写安排合理。但没有太多注释,但由于输出汉字较多,故在代码功能理解方面很好地给出了信息提示,比较利于代码读取。
代码设计:该代码比较简易,虽无法实现年级选择,但是对四则运算的法则和判断题目对错方面呢都很完整。但是无法一次性做100题并整体判别正确率。而出题显示由于选择一行输出所以排版上不是很完美。
总体汇总:
1.代码风格:在此方面其实大部分有编程经验的人都会很好的遵循编程技巧,严格加括号换行或者其他操作,但在注释方面大多数还是没办法很好给出。其实,注释中更应该的是简介明了,在必要的函数和类后加入注释,可以方便未来代码的复用,方便其他程序员的读写借鉴,也方便自己的查验。最好在整个代码前面写好整个代码实现的功能等性质。
2.代码设计:代码设计基本都可以完成基本的功能,很多情况也可以顾及到合理的人机互动界面。但是在很多情况下大家都不会太在意代码的重复,可能每一次写代码实现一个功能后在后面还需要设计一个和以前类似的函数时不能很好地利用前面的代码。代码设计方面其实更多的是我们并没办法很好地提高代码的利用率。虽然没有从头到尾都自己编写,但根据要求也可以进行简单地代码改写和复用。
作业二:结对编程
具体要求
1.实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
2.进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
3.针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
4.将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
实验效果
红楼梦
直观图表:
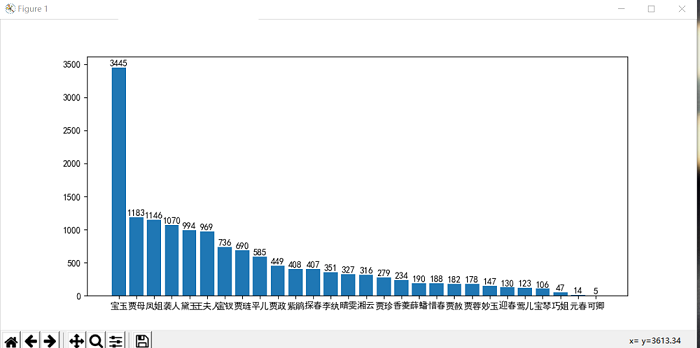
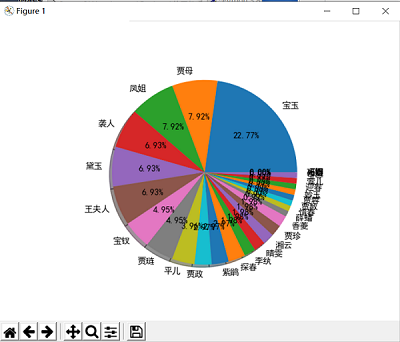
csv输出:

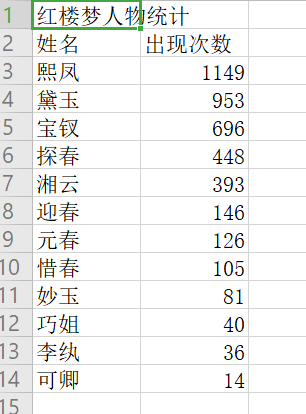
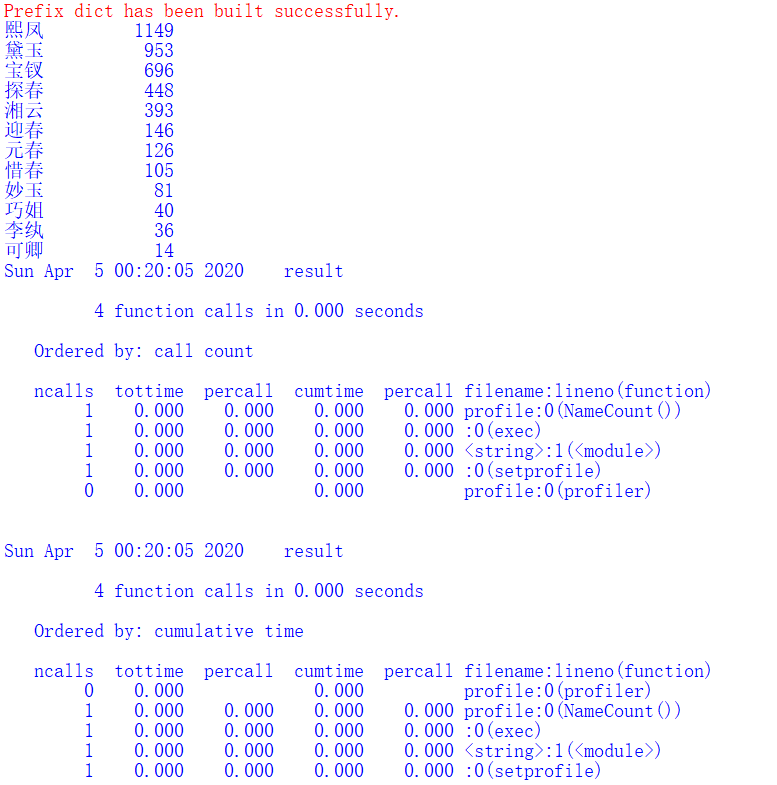
测试:
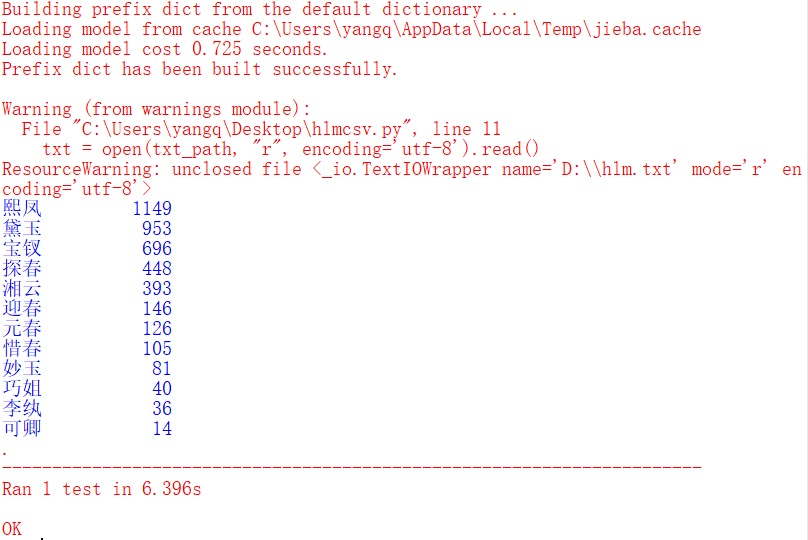
水浒传
csv输出:
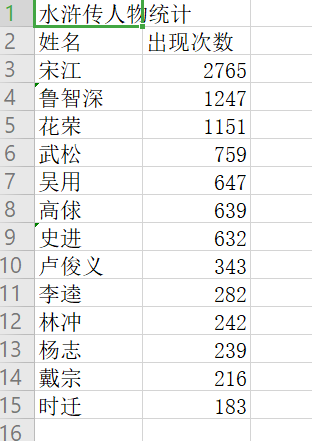
测试:

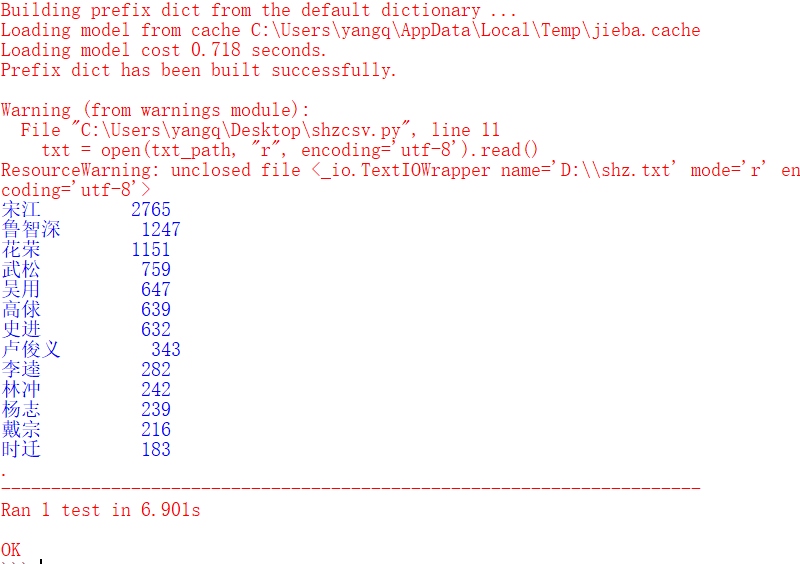
PSP表格:
| PSP | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 一天 | 一天 |
| Estimate | 估计这个任务需要多少时间 | 一周 | 两周 |
| Development | 开发 | 一周 | 一周多 |
| Analysis | 需求分析(包括学习新技术) | 二天 | 3天 |
| Coding Standard | 代码规范 | 1小时 | 1小时 |
| Design | 具体设计 | 2天 | 2天 |
| Coding | 具体编码 | 3天 | 5天 |
| Code Review | 代码复审 | 2小时 | 3小时 |
| Test | 测试 | 1小时 | 2小时 |
| Reporting | 报告 | 1小时 | 2小时 |
| Size Measurement | 计算工作量 | 1小时 | 1小时 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 1小时 | 1小时 |
| 合计 | --- | 两周 | 两周 |
实验总结:
此次作业第一次采用结对编程方法进行代码设计,通过两人连麦沟通共同完成此次作业。由于第一次使用该方式,比较新颖同时也比较具有挑战性。另外此次作业并没有按照我们以往的学习语言进行编写。刚开始虽然也尝试了几种学习过的语言,但是结果都没有达到预计的效果。最后还是决定参考网上的一种新的语言Python进行代码编写。在安装过程中其实我们都遇到比较多的问题。考虑到各个版本问题,最终我们选择的是3.8版本,但其实光下载该软件无法实现题目要求,还必须新找到库并进行画图代码书写,才可以达到画图目的。Python语言的书写规则也与平时我们学过的语言相差较大,故此次作业还是借助了很多网络信息的。
本次作业中主要进行Python软件的学习与应用,在结对编程的条件下进行代码开发,极大程度地结合了两个人的思想理解,在问题解决上速度效率较高,但在实现初期学习时工作分配不均,不易提高效率。
本次实验通过测试两个经典文本中的人物出现频率进行人物分析等操作,在一开始想用C++或Java语言进行开发,但随着进一步深入发现,C++只适合英文输入下的文本分析,中文的效率较低,不易表达。参考网络中代码,其实可以很快发现Python语言更加适合本次实验要求,故我们最终选择用Python语言完成本次实验。更加清晰地可以统计出人物出场次数,同时通过测试也可以分析代码测试的速率。
遇到困难:安装python和之前的软件安装不大相同,主要是后台控制,随着实验需要其实还需要进一步安装其他库来实现需要。在编写测试文件时,由于任务出场顺序读入顺序问题,出现过多次不匹配情况,最终在网上找到了类似错误的解决方案。
还需解决的问题:本次我们并没有研究出分章节讨论任务出场频率的分析,如果要细分,其实要人工操作,并没有想到好的解决方案。最后的测试也较为单一,没办法对方面分析代码。
代码托管
此次托管只需将新文件直接提交到个人仓库中。
码云链接:https://gitee.com/yang_qiu_yan/ruangong
附录代码
红楼梦图标分析:
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
# 此函数用于绘制条形图
def showNameBar(self,name_list_sort,name_list_count):
# x代表条形数量
x = np.arange(len(name_list_sort))
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制条形图,bars相当于句柄
bars = plt.bar(x,name_list_count)
# 给各条形打上标签
plt.xticks(x,name_list_sort)
# 显示各条形具体数量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
# 显示图形
plt.show()
# 此函数用于绘制饼状图
def showNamePie(self, name_list_sort, name_list_fracs):
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制饼状图
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
# 显示图形
plt.show()
def getNameTimesSort(self,name_list,txt_path):
# 将所有人名临时添加到jieba所用字典,以使jieba能识别所有人名
for k in name_list:
jieba.add_word(k)
# 打开并读取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分词
jieba_cut = jieba.cut(file_obj)
# Counter重新组装以方便读取
book_counter = Counter(jieba_cut)
# 人名列表,因为要处理凤姐所以不直接用name_list
name_dict ={}
# 人名出现的总次数,用于后边计算百分比
name_total_count = 0
for k in name_list:
if k == '熙凤':
# 将熙凤出现的次数合并到凤姐
name_dict['凤姐'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新组装以使用most_common排序
name_counter = Counter(name_dict)
# 按出现次数排序后的人名列表
name_list_sort = []
# 按出现次数排序后的人名百分比列表
name_list_fracs = []
# 按出现次数排序后的人名次数列表
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
print(k+':'+str(v))
# 绘制条形图
self.showNameBar(name_list_sort, name_list_count)
# 绘制饼状图
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['宝玉', '黛玉', '宝钗', '元春', '探春', '湘云', '妙玉', '迎春', '惜春', '凤姐', '熙凤', '巧姐', '李纨', '可卿', '贾母', '贾珍', '贾蓉', '贾赦', '贾政', '王夫人', '贾琏', '薛蟠', '香菱', '宝琴', '袭人', '晴雯', '平儿', '紫鹃', '莺儿']
# 红楼梦txt文件所在路径,修改成自己文件所在路径
txt_path = 'D:hlm.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)
红楼梦效率分析及csv文件输出:
# 红楼梦
import jieba
import csv
class NameCount():
def getNameTimesSort(self, name_list, txt_path):
# 添加jieba分词
mydict = ['琏二奶奶', '凤哥儿', '凤丫头', '宝姑娘', '颦儿', '二姑娘', '三姑娘', '四姑娘', '云妹妹', '蓉大奶奶']
for item in mydict:
jieba.add_word(item)
#打开并读取txt文件
txt = open(txt_path, "r", encoding='utf-8').read()
# 定义别名列表
bieming = [["王熙凤", "凤丫头", '琏二奶奶', '凤姐', '凤哥儿', '凤辣子','熙凤'],["林妹妹", "黛玉", '林姑娘', '林黛玉'], ["宝钗", '宝姑娘', '宝丫头', '宝姐姐', '薛宝钗'],
['探春', '三姑娘', '贾探春'], ['湘云', '云妹妹', '史湘云'],['迎春', '二姑娘', '贾迎春'],['元春', '大姑娘', '娘娘', '贵妃', '元妃', '贾元春'],
['惜春', '四姑娘', '贾惜春'], ['妙玉'],['巧姐'], ['李纨', '大嫂子'], ['秦可卿', '可卿', '蓉大奶奶']]
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# 计算出场次数(各个别名的合计次数)
lst = list()
for i in range(12):
lt = 0
for item in bieming[i]:
lt += counts.get(item, 0)
lst.append(lt)
items = list()
for i in range(12):
items.append([name_list[i], lst[i]])
items.sort(key=lambda x: x[1], reverse=True)
f = open('红楼梦人物统计.csv', 'w', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['红楼梦人物统计'])
csv_writer.writerow(["姓名", "出现次数"])
for i in range(12):
word, count = items[i]
csv_writer.writerow([word, count])
print("{0:<10}{1:>5}".format(word, count))
f.close()
return items
if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['熙凤', '黛玉', '宝钗', '探春', '湘云', '迎春', '元春', '惜春', '妙玉', '巧姐', '李纨', '可卿']
# txt文件所在路径
txt_path = 'D:hlm.txt'
NameCount().getNameTimesSort(name_list,txt_path)
import pstats
import profile
if __name__ == '__main__':
profile.run('NameCount()', 'result')
# 直接把分析结果打印到控制台
p = pstats.Stats('result') # 创建Stats对象
p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序
p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序
红楼梦各类测试
import unittest
from hlmcsv import*
class MyTestCase(unittest.TestCase):
def setUp(self):
pass
def test_something(self):
name_list = ['熙凤', '黛玉', '宝钗', '探春', '湘云', '迎春', '元春', '惜春', '妙玉', '巧姐', '李纨', '可卿']
txt_path = 'D:hlm.txt'
name_list_count = [1149, 953, 696, 448, 393, 146, 126, 105, 81, 40, 36, 14]
items = list()
for i in range(12):
items.append([name_list[i], name_list_count[i]])
self.assertEqual(items, NameCount().getNameTimesSort(name_list,txt_path))
def tearDown(self):
pass
if __name__ == '__main__':
unittest.main()
水浒传csv文件输出及效能测试
#水浒传
import jieba
import csv
import pstats
import profile
class NameCount():
def getNameTimesSort(self, name_list, txt_path):
mydict = ['及时雨','黑旋风', '行者','豹子头','花和尚', '智多星', '玉麒麟', '神行太保', '小李广','九纹龙','青面兽', '高太尉','鼓上蚤']
for item in mydict:
jieba.add_word(item)
txt = open(txt_path, "r", encoding='utf-8').read()
bieming = [['及时雨', '宋江', '呼保义', '孝义黑三郎', '宋公明', '宋押司'],['黑旋风', '李逵', '铁牛'],['武松', '武二郎', '行者', '武行者', '武都头'],['豹子头', '林冲', '林教头'],
['鲁提辖', '鲁达', '智深', '花和尚', '鲁智深'],['智多星', '吴用', '吴学究', '吴加亮', '赛诸葛', '加亮先生'],['卢俊义', '玉麒麟', '卢员外'], ['戴宗','戴院长','神行太保'],['花荣', '花知寨', '小李广'],
['九纹龙', '史进'], ['杨志', '杨制使', '杨提辖', '青面兽'], ['高俅,‘高二','高太尉'],['时迁','鼓上蚤'] ]
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# 计算出场次数(各个别名的合计次数)
lst = list()
for i in range(13):
lt = 0
for item in bieming[i]:
lt += counts.get(item, 0)
lst.append(lt)
items = list()
for i in range(13):
items.append([name_list[i], lst[i]])
items.sort(key=lambda x: x[1], reverse=True)
f = open('水浒传人物统计.csv', 'w', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['水浒传人物统计'])
csv_writer.writerow(["姓名", "出现次数"])
for i in range(13):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
csv_writer.writerow([word, count])
f.close()
return items
if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['宋江', '鲁智深', '花荣', '武松', '吴用', '高俅', '史进', '卢俊义', '李逵', '林冲', '杨志','戴宗','时迁']
# 水浒传txt文件所在路径
txt_path = 'D:shz.txt'
NameCount().getNameTimesSort(name_list, txt_path)
print("效能测试:")
profile.run('NameCount()', "result")
# 直接把分析结果打印到控制台
p = pstats.Stats('result') # 创建Stats对象
p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序
p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序
水浒传测试文件
import unittest
from shzcsv import*
class MyTestCase(unittest.TestCase):
def test_something(self):
name_list = ['宋江','鲁智深 ', '花荣', '武松', '吴用','高俅','史进 ', '卢俊义','李逵', '林冲', '杨志', '戴宗','时迁']
txt_path = 'D:shz.txt'
name_list_count = [2765, 1247, 1151, 759, 647, 639, 632, 343, 282, 242, 239, 216,183]
items = list()
for i in range(13):
items.append([name_list[i], name_list_count[i]])
self.assertEqual(items, NameCount().getNameTimesSort(name_list, txt_path))
if __name__ == '__main__':
unittest.main()