之前阅读也有总结过Block的RPC服务是通过NettyBlockRpcServer提供打开,即下载Block文件的功能。然后在启动jbo的时候由Driver上的BlockManagerMaster对存在于Executor上的BlockManager统一管理,注册Executor的BlockManager、更新Executor上Block的最新信息、询问所需要Block目前所在的位置以及当Executor运行结束时,将Executor移除等等。那么Driver与Executor之间是怎么交互的呢?
在Spark1.6时,Drvier的BlockManagerMaster与BlockManager之间的通信,不再是通过AkkaUtil,而是用了RpcEndpoint,也就木有了BlockManagerMasterActor,而是BlockManagerMasterEndpoint:
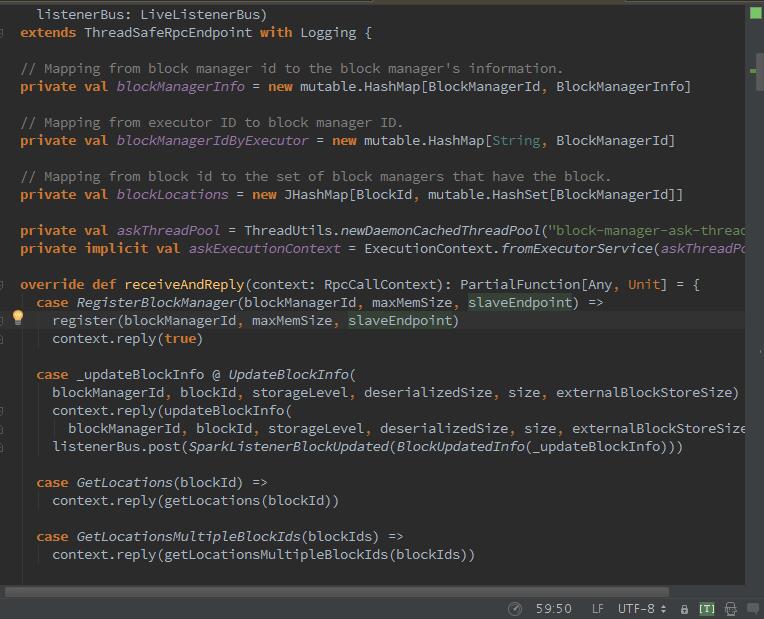
BlockManagerMaster与BlockManager之间的通信已经使用RPC远程过程调用来实现,RPC相关配置参数如下:
spark.rpc.retry.wait 3s(默认)等待时长 、 spark.rpc.numRetries 3(默认)重试次数、spark.rpc.askTimeout 120s(默认)请求时长、spark.rpc.lookupTimeout与spark.network.timeout 120s(默认)查找时长,是要一起配置。
好的,我们继续,每个executor中的BlockManager的创建,都要经过BlockManagerMaster注册BlockManagerId.
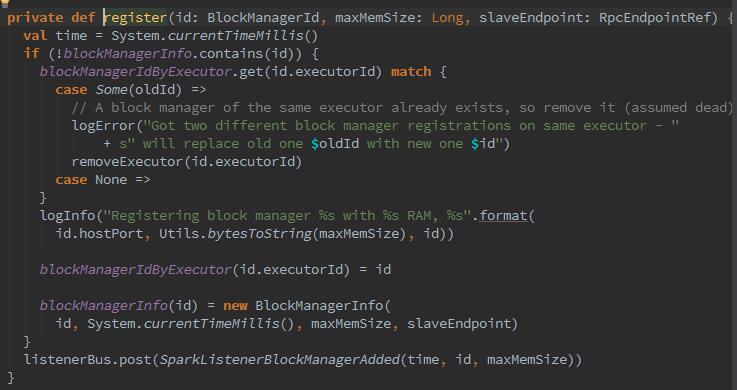
Executor或Driver自身的BlockMnager在初始化时,需要向Driver的BlockManager注册BlockMnager信息,注册的消息内容包括BlockMnagerI的d、时间戳、最大内存、以及slaveEndpoint。带有slaveEndpoint的目的是为了便于接收BlockManagerMaster回复的消息,在register方法执行结束后向发送者BlockManageMaster发送一个简单的消息true.

register方法确保blockManagerInfo持有消息中的blockManagerId及对应消息,并且确保每个Executor最多只能有一个blockManagerId,旧的blockManagerId会被移除。最后向listenerBus中post(推送)一个sparkListenerBlockManagerAdded事件。
那么下来,开始磁盘管理器DiskBlockManager的构造:
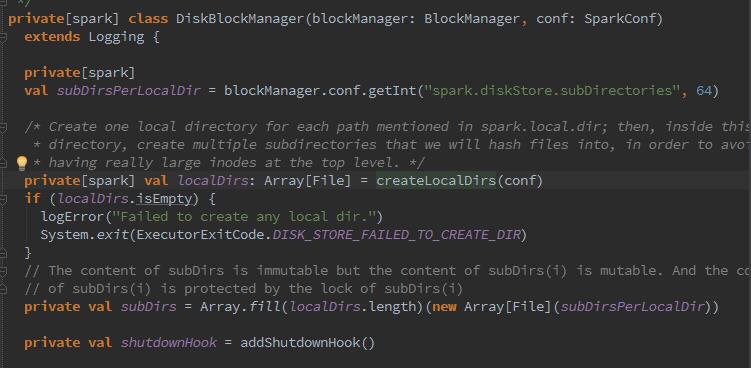
我们可以看到BlcokManager初始化时,创建DiskBlockManager,在创建时,调用了createLocalDirs方法创建本地文件目录,然后创建了二维数组subDirs,用来缓存一级目录localDirs及二级目录,其中二级目录的数量根据配置spark.diskStore.subDirectories获取,默认为64.那么为什么DisBlockManager要创建二级目录?因为二级目录用于对文件进行散列存储,散列存储可以使所有文件都随机存放,写入或删除文件更方便,存取速度快,节省空间。那么我们再细化看下这个磁盘路径是怎么配置的,从哪里来的?
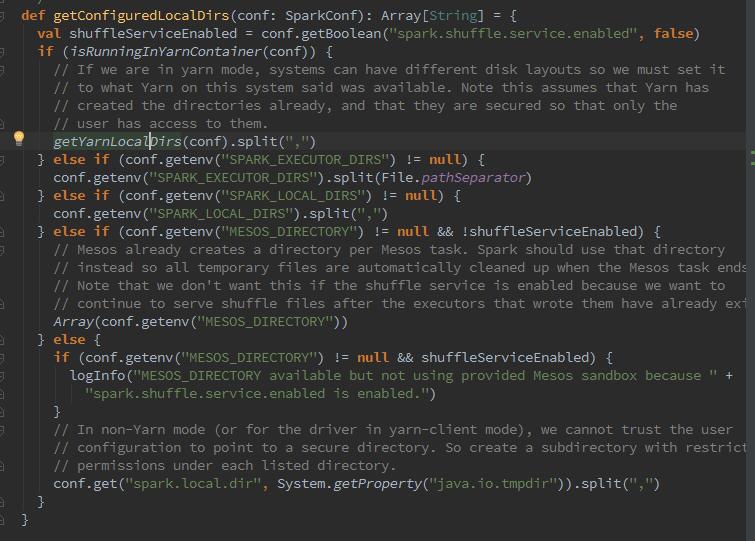
从图中可以看到,这个路径来源于spark.local.dir,但是呢,如果是spark on yarn模式,那么真正的路径是由yarn的配置参数决定的,参数为YARN_LOCAL_DIRS。
接下来查阅源码还会发现有个addShutdownHock()方法,它是干什么的呢,它是用来添加运行时环境结束时,在进程关闭的时候创建线程,通过调用Disk-BlockMnager的stop方法,清除一些临时目录:
下来我们来探索下,是如何获取磁盘文件的?
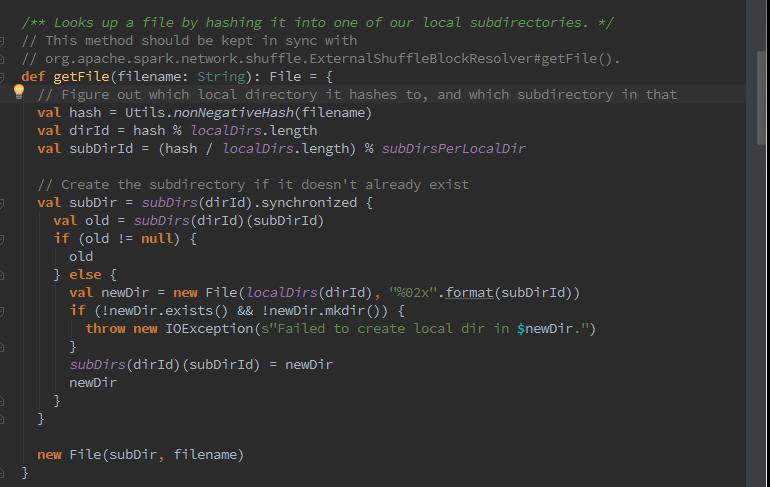
首先我们可以看到,nonNegativeHash方法,该方法用来根据文件名计算哈希值。然后根据哈希值与本地文件以及目录的总数求余数,记为dirId。随后又根据哈希值与本地文件一级目录的总数求商数,此商数与二级目录的数目再求余数,记为subDirId.那么如果dirId/subDirId目录存在,则获取dirId/subDirId目录下的文件,否则创建dirId/subDirId目录。
好的下来我们来创建本地临时文件与shuffle过程的临时文件:

我们可以看到,当MemoryStore没有足够空间时,就会使用DiskStore将块存入磁盘。当ShuffleMapTask运行结束需要把中间结果临时保存,此时就调用了createTempShuffleBlock方法创建临时Block,并返回TempShuffleBlockId与其文件的对偶,同时拼上随机字符串标识。
那么下来,我们再深入了解下MemoryStore,我们在配置spark的时候,会配置计算内存与缓存内存的比例,实质是通过MemoryStore将没有序列化的Java对象数组或者序列化的ByteBuffer存储到内存中,那么MemoryStore是如何构造的呢?

整个MemoryStore的存储分为两块:一块是被很多MemeoryEntry占据的内存currentMemory,这些currentMemory实际上是通过entryes持有的;另一块儿是通过unrollMemoryMap通过占座方式占用的内存currentUnrollMemory.其实意思就是预留空间,可以防止在向内存真正写入数据时,内存不足发生溢出。查阅数据,记录些概念:
-maxUnrollMemory:当前Driver或者Executor最多展开的Block所占用的内存,可以修改spark.storage.unrollFraction的大小。
-maxMemory:当前Driver或者Executor的最大内存。
-currentMemory:当前Driver或者Executor已经使用的内存。
-freeMemory:当前Driver或Executor未使用内存。freeMemoy = maxMemory - currentMemory。
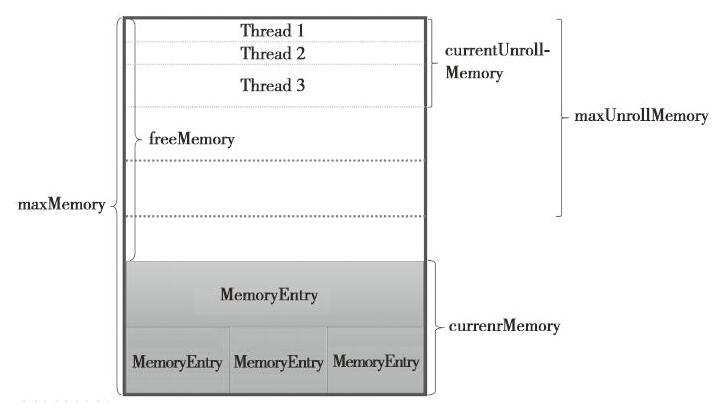
这里有个重要的点,叫做unrollSafely,为了防止写入内存的数据过大,导致内存溢出,Spark采用了一种优化方案,在正式写入内存之前,先用逻辑方式申请内存,如果申请成功,再写入内存,这个过程就跟名字一样了,称为安全展开。
就到这里好了,去吃饭~
参考文献:《深入理解Spark:核心思想与源码分析》