需求
现在我们有一组从2006年到2016年1000部最流行的电影数据
- 问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
- 问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
工具
- python3.8
- jupyter notebook
实现
导包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
读取数据
movies = pd.read_csv("./IMDB-Movie-Data.csv")

1、获取平均分直接调用mean()函数。获得导演数量:需要先把导演数据提取,然后去重,最后通过shape[0]获取 (不懂shape函数可以看我numpy数组属性那)
### 获取平均分
movies["Rating"].mean()
### 获取导演人数
np.unique(movies["Director"]).shape[0]
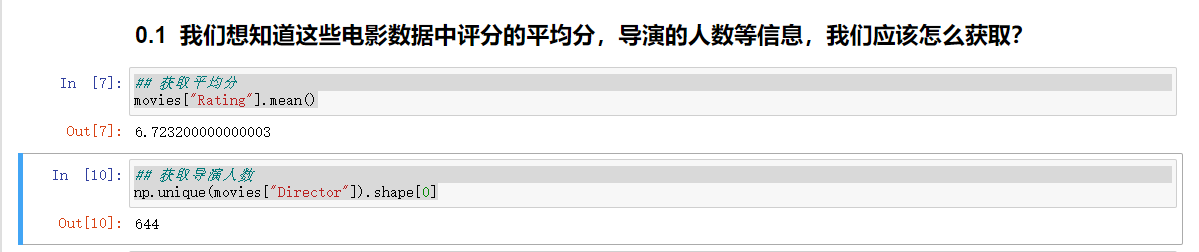
2、呈现数据用的是matplotlib,如果用pandas绘图,间隔会体现不出来,如下图
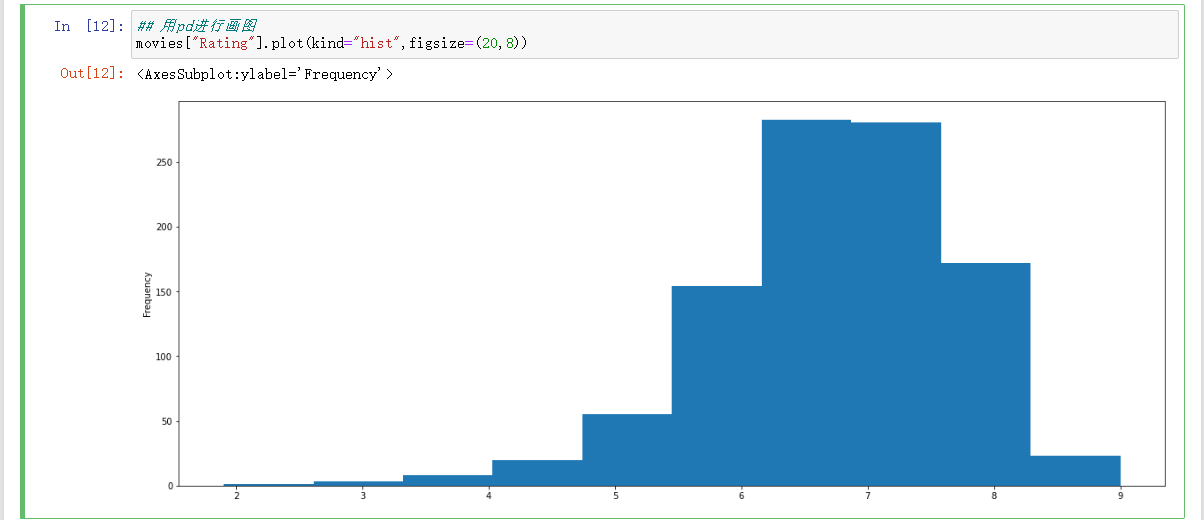
matplotlib画图三步骤:
Rating的分布情况
## Rating的分布情况
## 用 plt画图
## 1、创建画布
plt.figure(figsize=(20,8),dpi=100)
## 2、绘制图像
plt.hist(movies["Rating"], bins=20)
## 2.1 添加x刻度
x_max = movies["Rating"].max()
x_min = movies["Rating"].min()
t1 = np.linspace(x_min,x_max,21)
plt.xticks(t1)
## 2.2添加网格
plt.grid()
## 3、显示
plt.show()
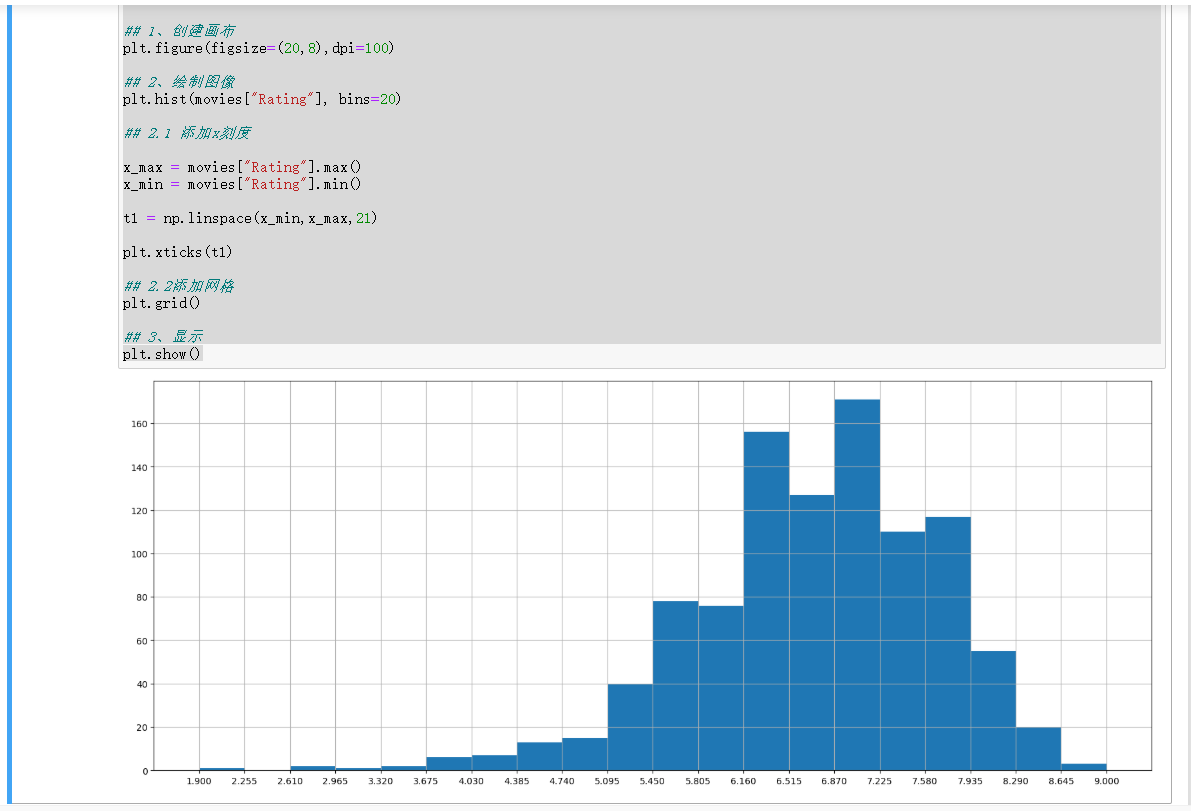
同理Runtime (Minutes)的分布情况
## Runtime (Minutes)的分布情况
## 1、创建画布
plt.figure(figsize=(20,8),dpi=100)
## 2、绘制图像
plt.hist(movies["Runtime (Minutes)"],bins=20)
## 2.1、添加x轴刻度
x_max = movies["Runtime (Minutes)"].max()
x_min = movies["Runtime (Minutes)"].min()
## 生成20个区间,需要21个数字
t = np.linspace(x_min,x_max,num=21)
plt.xticks(t)
## 2.2、添加网格
plt.grid()
## 3、显示图像
plt.show()
3、统计电影分类情况
3.1 每个电影有多种类型,先把个电影类型提取出来,然后进行分割,放到一个列表,将列表进行去重得到所有电影类型。
3.2 生成一个一电影个数为行,电影类型数为列的全0矩阵,最后再将矩阵转换成DataFrame,并以电影类型为列
3.3 for循环遍历,通过索引操作将对应电影类型变为1
3.1代码
## 用列表生成式
temp_list = [i.split(",") for i in movies["Genre"]]
type_list = np.unique([i for j in temp_list for i in j])

3.2代码
zeros = np.zeros([movies.shape[0],type_list.shape[0]])
temp_movie = pd.DataFrame(data=zeros,columns=type_list)
3.3代码
for i in range(1000):
temp_movie.loc[i,temp_list[i]] = 1
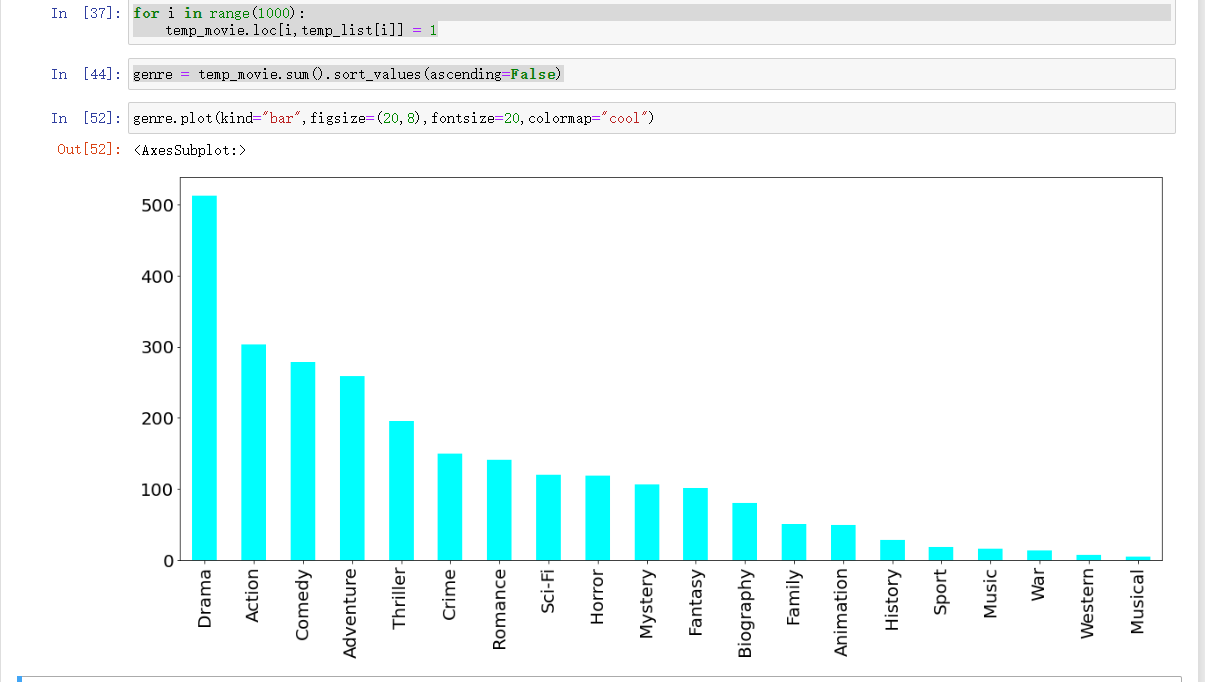
## 按降序排序
genre = temp_movie.sum().sort_values(ascending=False)
## 画图
genre.plot(kind="bar",figsize=(20,8),fontsize=20,colormap="cool")
结尾
上述案例是对numpy、matplotlib、pandas的使用案例。也是对自己学的知识的一个总结