0与1:
信息存储和逻辑计算的元数据,都是0和1。
机器数:
一个数在计算机中的二进制表示形式(如1的二进制表示为 0000 0001),叫做这个数的机器数。
机器数是带符号的,在计算机用机器数的最高位存放符号,正数为0,负数为1,最高位不参与数据表示。
机器数的真值:
因为第一位是符号位,所以机器数的形式值就不等于真正的数值。
例如有符号数 1000 0011,其最高位1代表负,其真正数值是 -3,而不是形式值131(1000 0011转换成十进制等于131)。所以,为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
例:0000 0001的真值 = +000 0001 = +1,1000 0001的真值 = –000 0001 = –1
原码、反码、补码:
正数的原码、反码和补码都相同,负数的补码是反码加1。
原码(true form):是一种计算机中对数字的二进制定点表示方法。原码表示法在数值前面增加了一位符号位(即最高位为符号位):正数该位为0,负数该位为1(0有两种表示:+0和-0),其余位表示数值的大小
原码是计算机机器数中最简单的一种形式,数值位就是真值的绝对值,符号位位“0”时表示正数,符号位为“1”时表示负数,原码又称带符号的绝对值
缺点:原码不能直接参与运算,原因是原码的符号位不能参与运算,必须和其他位分开
反码:为了解决原码不能参与运算的问题,发明了反码
正数的反码是其本身
负数的反码是在其原码的基础上,符号位不变,其余各个位取反
补码:二进制整数都是以补码的形式出现的。补码是计算机把减法运算转化为加法运算的关键编码(反码运算会出现+0和-0的问题)
正数的补码就是其本身
负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(也即在反码的基础上+1)
这样可以使减法运算也可以使用加法器实现,符号位也参与运算。
位移运算:
向右移动1位近似表示除2,十进制的奇数转化为二进制数之后,在向右移时,最右边的1将被直接抹去,说明向右移对于奇数并非完全相当于除以2。
在左移 << 和右移 >> 两种运算中,符号位均参与移动,除负数往右移动,高位补1之外,其他情况均在高位补 0。
左移运算由于符号位参与向左移动,在移动后的结果中,最左位可能是1或者0,即正数向左移动的结果可能为正,也可能为负;负数向左移动的结果同样可能是正,也可能是负。
>>> 无符号向右移动,注意不存在(<<<无符号向左移动的运算),当向右移动时,正负数高位均补0,正数不断向右移动的最小值是0,负数不断向右移动的最小值是1。
字符集与乱码
在计算机中,所有的数据在存储和运算时都要使用二进制数表示,而具体用哪些二进制表示哪个符号,就叫编码。
ASCII码使用7位二进制数(剩下的1位最高位为0),共128种组合来表示所有的大写和小写字母、标点符号,以及在美式英语中使用的特殊控制字符。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等
一个字节最多只能表示256个字符,而汉字最多有10万个,因此汉字编码GB2312和GBK采用双字节编码,一个汉字占用两个字节。
在日常开发中,字符集如果不兼容则会造成乱码。编码的字符集和查看的字符集不一致且不兼容时,就会出现乱码。
CPU和内存
CPU(Central Processing Unit)是一块精密的集成电路板,是计算机的核心部件,承载着计算机的主要运算和控制功能,是计算机指令的最终解释模块和执行模块。
CPU的内部由控制器、运算器和寄存器组成。
1)控制器
控制器由控制单元、指令译码器、指令寄存器组成。其中控制单元是CPU的大脑,由时序控制和指令控制组成
2)运算器
运算器的核心是算术逻辑运算单元(ALU),能够执行算术运算或逻辑运算等各种命令,运算单元会从寄存器中提取或存储数据。
任何算术运算和指令最后都会以0与1的组合流方式在运算器中完成最终计算,并保存到寄存器,最后送出CPU。
3)寄存器
最著名的寄存器是CPU的高速缓存L1、L2,它们是CPU和内存之间的缓冲区。缓存结构和容量对CPU的运行速度影响非常大。毕竟CPU的运行速度远大于内存的读写速度,更远大于磁盘。
计算机中所有的程序都在内存中运行,它的容量与性能如果存在瓶颈,即使CPU再快,也是枉然。
TCP/IP
网络协议:
计算机之间发送和接收数据的过程需要相应的协议来支撑,可以按互相可以理解的方式进行数据的打包与解包。
TCP/IP(Transmission Control Protocol/ Internet Protocol),传输控制协议/因特网互联协议,是一个协议族,因为TCP(传输层协议)、IP协议是其中最核心的协议,所以就把该协议族成为TCP/IP。
链路层:单个0、1是没有意义的,链路层以字节为单位把0与1进行分组,定义数据帧,写入源和目标机器的物理地址、数据、校验位来传输数据
网络层:根据IP定义网络地址,区分网段。子网内根据地址解析协议(ARP)进行MAC寻址,子网外进行路由转发数据包,这个数据包即IP数据包。
传输层:数据包经过网络层发送到目标计算机后,应用程序在传输层定义逻辑端口,确认身份后,将数据包交给应用程序,实现端口到端口间通信。最典型的传输层协议是TCP和UDP。
应用层:传输层的数据到达应用程序时,以某种统一规定的协议格式解读数据。
总结:程序在发送消息时,应用层按既定的协议打包数据,随后传输层加上双方的端口号,由网络层加上双方的IP地址,由链路层加上双方的MAC地址,并将数据拆分成数据帧,经过多个路由器和网关后,到达目标机器。
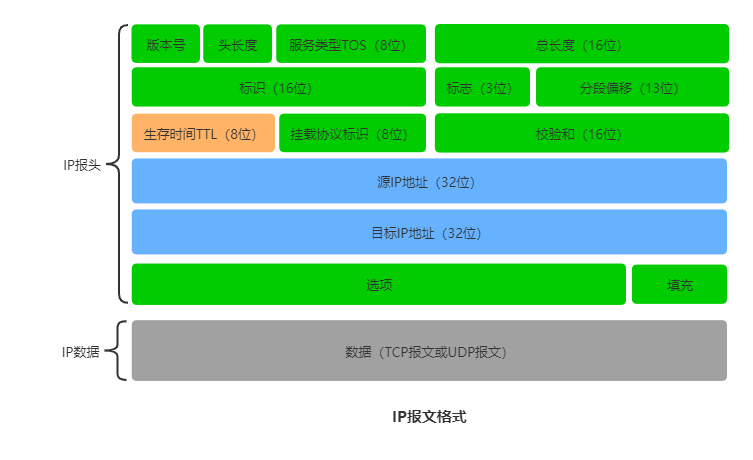
IP协议:
IP是面向无连接、无状态的,没有额外的机制保证发送的包是否有序到达。
IP首先规定出IP地址格式,该地址相当于在逻辑意义上进行了网段的划分,给每台计算机额外设置了一个唯一的详细地址。
既然链路层可以通过唯一的MAC地址找到机器,为什么还需要通过唯一的IP地址再来标识呢?简单来说,在世界范围内,不可能通过广播的方式,从数以千万计的计算机中找到MAC地址的计算机而不超时。在数据投递时就需要对地址进行分层管理。根据IP进行路由。
IP地址属于网络层,主要功能在WLAN内进行路由寻址,选择最佳路由。
TCP协议:
传输控制协议(Transmission Control Protocol),是一种面向连接、确保数据在端到端间可靠传输的协议。
面向连接是指在发送数据前,需要先建立一条虚拟的链路,然后让数据在这条链路上完成传输。为了确保数据的可靠传输,不仅需要对发出的每一个字节进行编号确认,校验每一个数据包的有效性,在出现超时情况时进行重传,还需要通过实现滑动窗口和拥塞控制等机制,避免网络状态恶化而最终影响数据传输的极端情形。
每个TCP数据包是封装在IP包中的,每一个IP头的后面紧接着的是TCP头,TCP报文格式如下图:
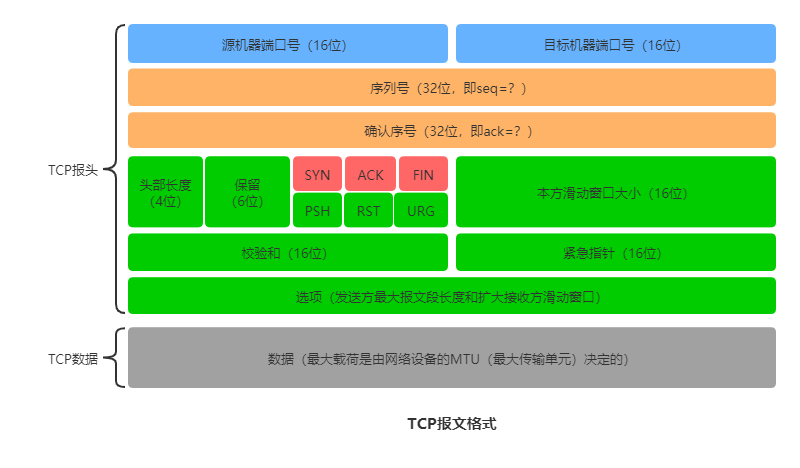
SYN(Synchronize Sequence Numbers)用作建立连接时的同步信号;
ACK(Ackonwledgement)用于对收到的数据进行确认,所确认的数据由确认序列号表示
FIN(Finish)表示后面没有数据需要发送,通常意味着所建立的连接需要关闭了。
TCP中连接建立的原理:
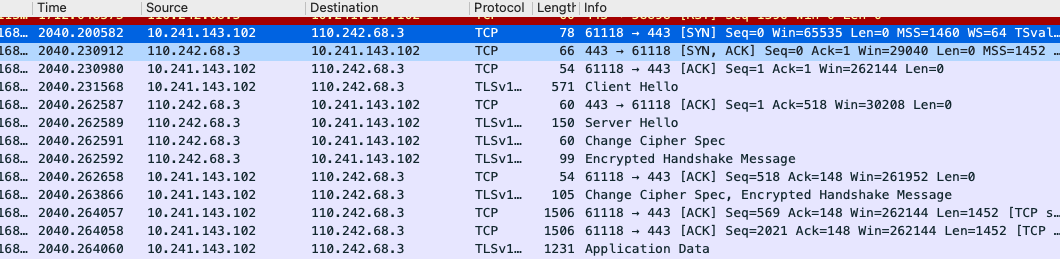
建立连接的三个步骤,三次握手:
1)A 机器发出一个数据包并将 SYN置1,表示希望建立连接。这个包中的序列号假设是x
2)B 机器收到 A发过来的数据包后,通过SYN得之这是一个建立连接的请求,于是发送一个响应包并将SYN和ACK标记都置1。假设这个包中的序列号为y,而确认序列号必须是x+1。表示服务器收到了A发过来的SYN。
3)A 收到 B的响应包后需进行确认,确认包中将ACK置1,并将确认序列号设置为 y+1,表示收到了来自服务端的SYN。
记忆技巧:SYN-SYN-ACK

为什么需要三次握手呢?
信息对等和防止超时导致脏连接
1)信息对等:只有经过三次握手后双方才能确认:自己发报能力、自己收报能力、对方收报能力、对方发报能力这4类信息是正常的
2)防止超时导致脏连接:
网络报文的生存时间TTL往往会超过TCP请求超时时间,如果两次握手就可以创建连接,会存在当第一个连接请求超时时,A机器重新发送连接请求,建立连接然后传输数据并释放连接后,第一个超时的连接请求才到达B机器,B机器会以为是A创建新连接的请求,然后确认同意创建连接。此时,因为A机器的状态不是SYN_SENT,所以直接丢弃了B的确认数据,导致B机器单方面创建连接完毕,造成脏连接。
TCP三次握手抓包:
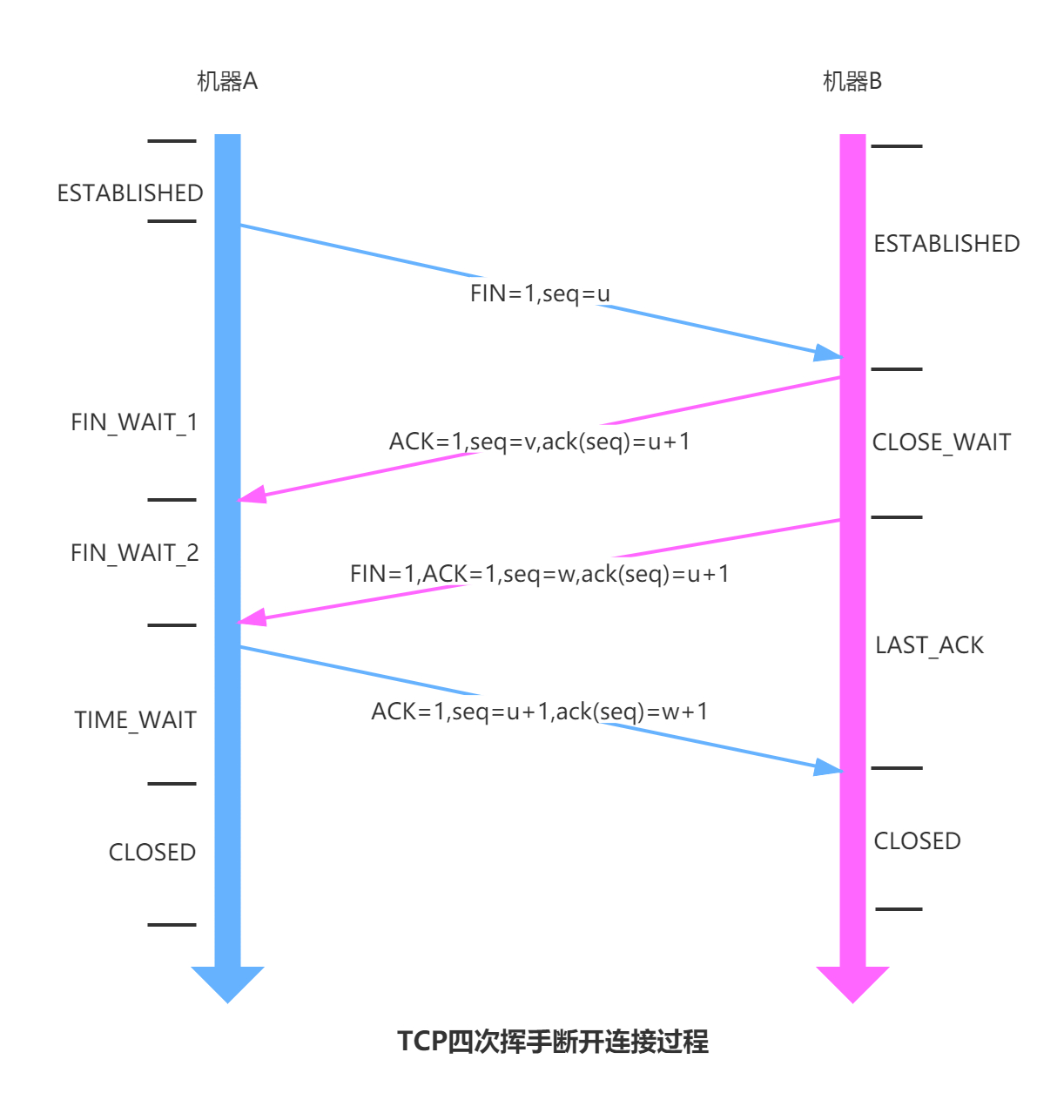
连接池
连接池:可以在高并发环境下减少频繁创建和释放连接带来的开销,负责分配、管理和释放连接,是一种以内存空间换取时间的策略。
如何合理地创建、管理和断开连接呢?
信息安全
SQL注入
SQL注入式攻击是未将代码与数据进行严格隔离,导致在读取用户数据的时候,错误地把数据作为代码的一部分执行,从而导致的一些安全问题。
典型的SQL注入例子是当对SQL语句进行字符串操作时,直接使用未转义的用户输入内容作为变量。
如何预防SQL注入?
1)过滤用户输入参数中的特殊字符,从而降低被SQL注入的风险
2)禁止通过字符串拼接的SQL语句,严格使用参数绑定传入的SQL参数
3)合理使用数据库访问框架提供的防注入机制,如MyBatis的 #{}绑定参数
XSS 跨站脚本攻击(Cross-Site Scripting)
XSS是指黑客通过技术手段,向正常用户请求的HTML页面中插入恶意脚本,从而执行任意脚本。
如何防范XSS攻击?
对用户输入数据做过滤或转义。
1)Java Jsoup框架可以对用户输入的字符串做XSS过滤,或者使用Spring提供的HtmlUtils对用户输入的字符串做HTML转义。
2)前端展示数据时使用innerText替代innerHtml
CSRF 跨站请求伪造 (Cross-Site Request Forgery)
即在用户不知情的情况下,冒充用户(盗用用户浏览器中的登录信息)发起请求,在当前已经登录的Web应用程序上执行恶意操作,如恶意发帖、修改密码、发邮件等。
如何防范CSRF攻击?
1)CSRF Token验证,利用浏览器的同源限制,在HTTP接口执行前验证页面或者Cookie中设置的Token,只有验证通过才继续执行请求
2)人机交互,比如在调用重要接口(如转账接口)时校验短信验证码
XSS和CSRF的区别?
1、XSS是在正常用户请求的HTML页面中执行了黑客提供的恶意脚本;CSRF是黑客直接盗用用户浏览器的登录信息,冒充用户去执行黑客指定的操作
2、XSS问题出在没有对用户输入数据进行过滤、转义;CSRF问题出在HTTP接口没有防范不受信任的调用。
HTTPS
HTTPS全称为 HTTP over SSL,即在HTTP传输之上增加了SSL协议的加密能力。
SSL(Secore Socket Layer),安全套接字层协议,工作于传输层与应用层之间,为应用提供数据的加密传输。
TLS(Transport Layer Security),传输层安全协议,TLS可以理解成SSL协议3.0版本的升级,TLS1.0版本也被标识为SSL 3.1版本。
对称加密算法存在密钥传输问题,非对称加密算法存在耗时长问题。因此HTTPS采用对称加密和非对称加密两者并用的混合加密机制,对称加密算法的密钥的传输使用非对称加密。
在整个HTTPS的传输过程中,主要分为两部分:
1)HTTPS的握手:建立一个HTTPS的通道,并确定连接使用的加密套件及数据传输使用的对称密钥
2)数据的传输:使用对称密钥对数据加密并传输
END.