背景: 前几天了解了spark了运行架构,spark代码提交给driver时候会根据rdd生成DAG,那么实际DAG在代码中是如何生成的呢?
首先了解,spark任务中的几个划分点:
1.job:job是由rdd的action来划分,每一个action操作是在spark任务执行时是一个job。(action的区分:rdd分为行动操作和转化操作,因为我们知道rdd是惰性加载的,除非遇到行动操作,前面的所有的转化操作才会执行,这也就是为什么spark任务由job来划分执行了,区分行动操作和转化操作最简单的方法就是看,rdd放回的值,如果返回的是一个rdd则是转化操作,例如map,如果返回的是一个其他的数据类型则是行动操作,例如count)
2.stage:根据rdd的宽窄依赖来划分(shuffle来区分),遇到shuffle,则将shuffle之前的窄依赖归来一个stage;
3.task:task是由最后的executor执行的最小任务,它最终落到各个executor上,实现分布式执行;
简单的归纳一下他们的关系:job -> stage -> task (job中有多个stage,stage中有多个task);
spark运行时,一个任务由client提交,再由driver划分逻辑实现图DAG,最后分配给各个executor上执行task;
思考:任务是如何分配监听的?hash分配,随机分配?
spark在任务拆分的时候,参考下图:
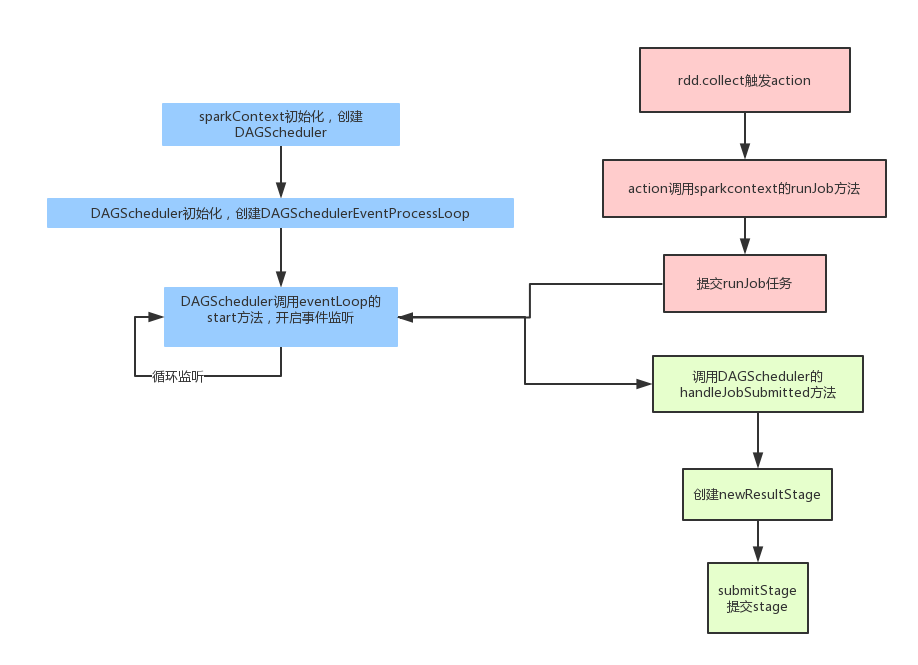
1.先由sparkcontext初始化,创建一个DAGshcheduler,启动一个监听器,监听spark任务,spark拆分的所有任务都会发给这个监听器;
2.客户端这边,当我们调用action时,则action会向sparkcontext启动一个runjob,即是将action任务(一个job)提交给DAGshcheduler的监听器;
3.接到job的DAGscheduler 会将任务交给handleJobSubmitted 来处理;
4. 每个job会生成一个resultstage,其余的都是shufflestage,shufflestage是根据rdd的宽依赖来生成的,根据广度优先遍历rdd,遇到shufflestage就创建一个新的stage;
5.形成DAG图之后,遍历执行stage列表,根据父子stage顺序执行,如果上层未执行完,下层会一直等待;
6.每个stage会拆分成多个task,交由taskshcheduler来分配,等待executor来执行完一个task后交给下一个task;
1. spark2.0中, 初始化sparksession builder 中的sparkcontext在初始化的时候会创建一个dagscheduler的变量,
sparkcontext:
_dagScheduler = new DAGScheduler(this)
DAGscheduler的构造方法中,会自己创建一个DAGschedulereventprocessloop,并自启动一个监听器
DAGscheduler:
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
……
eventProcessLoop.start()
}
DAGschedulereventprocessloop的父类 EventLoop 中有个线程类Thread 会起一个线程监听
EventLoop:
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) => {
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
其中核心就是一个线程只做onReceive操作,父类只是一个抽象类,子类实现这个方法,调用doOnReceive
/**
* The main event loop of the DAG scheduler.
*/
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
其最终单线程监听循环执行的就是:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
// 处理job提交任务
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
// 处理map提交的stage任务
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
// 处理map stage 取消的任务
case StageCancelled(stageId) =>
dagScheduler.handleStageCancellation(stageId)
// 处理job 取消的任务
case JobCancelled(jobId) =>
dagScheduler.handleJobCancellation(jobId)
// 处理job 组取消的任务
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
// 处理所有job 取消的任务
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
// 处理executort完成分配的事件
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
// 处理executor对视事件
case ExecutorLost(execId) =>
dagScheduler.handleExecutorLost(execId, fetchFailed = false)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion @ CompletionEvent(task, reason, _, _, taskInfo, taskMetrics) =>
dagScheduler.handleTaskCompletion(completion)
// 处理task丢失的事件
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
// 处理重新提交失败Stage事件
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}
假如执行一个rdd 执行action操作,即是将rdd中由sparkcontext 调用 runjob方法,sparkcontext中的初始化的DAGscheduler来调用 submitjob将这一个event事件加入到
DAGscheduler的执行队列中,等待线程顺序执行
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
........
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
至此,一个rdd的执行操作已经进入DAG监听器的队列了,下一步由监听器取按顺序取出来doOreceive 按照event的实际类型来执行相应的操作:
如果调用JobSubmitted方法,则调用相对应的handleJobSubmitted。