一、常用模块
1 xml模块
xml指可扩展标记语言(eXtensible Markup Language),标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言
xm通过<>节点来区别数据结构,格式如下:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
常用操作:
import xml.etree.ElementTree as ET tree = ET.parse('test.xml') #打开想xml文档 root = tree.getroot() #获得根节点 #每个element对象都具有以下属性: # 1. tag:string对象,表示数据代表的种类。 # 2. attrib:dictionary对象,表示附有的属性。 # 3. text:string对象,表示element的内容。 # 4. tail:string对象,表示element闭合之后的尾 #1、遍历xml文档 for child in root: print('========>', child.tag, child.attrib, child.attrib['name']) for i in child: print(i.tag, i.attrib, i.text) #2、查找element元素的三种方式之iter years = root.iter('year') #从根节点下开始扫描所有树形结构 for i in years: print(i) print(i.text) #查找element元素的三种方式之find res = root.find('country') #从根下一层开始查找,返回一个与之匹配的元素 print(res) #查找element元素的三种方式之findall res = root.findall('country') #从根下一层开始查找,返回所有与之匹配的元素 print(res) #3、修改 for node in root.iter('year'): new_year = int(node.text)+1 #拿出year里面的内容,转成整型再进行加1操作 node.text = str(new_year) #转成字符串类型,才能写入文件 node.set('updated','yes') #添加属性 node.set('version','1.0') #添加属性 tree.write('test.xml') #删除 for country in root.findall('country'): rank = country.find('rank') if int(rank.text) > 50: country.remove(rank) tree.write('test.xml') #添加 for country in root.findall('country'): y = ET.Element('Yim') y.attrib = {'age':'25'} y.text = 'hello' country.append(y) tree.write('test.xml')
2 shutil模块
高级的文件、文件夹、压缩包处理模块
import shutil #1、将文件内容拷贝到另一个文件中,shutil.copyfileobj(fsrc, fdst[, length]) shutil.copyfileobj(open('a.txt','r'),open('b.txt','w')) #2、拷贝文件,shutil.copyfile(src, dst) shutil.copyfile('b.txt','c.txt') #目标文件无须存在 #3、仅拷贝权限。内容、组、用户均不变,shutil.copymode(src, dst) shutil.copymode('c.txt','d.txt') #目标文件须存在 #4、仅拷贝状态的信息(包括:mode bits, atime, mtime, flags),shutil.copystat(src, dst) shutil.copystat('d.txt','e.txt') #目标文件须存在 #5、拷贝文件和权限,shutil.copy(src, dst) shutil.copy('a.txt','f.txt') #目标文件无须存在 #6、拷贝文件和状态信息,shutil.copy2(src, dst) shutil.copy2('f.txt','g.txt') #7、递归拷贝文件夹,shutil.copytree(src, dst, symlinks=False, ignore=None) shutil.copytree('dir1', 'dir2',ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) # 目标目录不能是已存在,注意对dir2目录父级目录要有可写权限,ignore的意思是排除 #8、递归删除目录,shutil.rmtree(path[, ignore_errors[, onerror]]) shutil.rmtree('dir1') #9、递归移动文件,类似于mv命令,其实就是重命名 shutil.move('g.txt','g.mv.txt') #10、打包压缩,shutil.make_archive(base_name, format,...) #创建压缩包并返回文件路径,例如:zip、tar # base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径, # 如 data_bak =>保存至当前路径 # 如:/tmp/data_bak =>保存至/tmp/ # format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar” # root_dir: 要压缩的文件夹路径(默认当前目录) # owner: 用户,默认当前用户 # group: 组,默认当前组 # logger: 用于记录日志,通常是logging.Logger对象 ################################################ # 将 /data 下的文件打包放置当前程序目录 ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data') # 将 /data下的文件打包放置 /tmp/目录 ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data') #zip压缩 import zipfile z = zipfile.ZipFile('test.zip','w') z.write('a.txt') z.write('b.txt') z.close() #zip解压 import zipfile z = zipfile.ZipFile('test.zip','r') z.extractall(path='/tmp') z.close() #tar压缩 import tarfile t = tarfile.open('test.tar','w') t.add('a.txt',arcname='a.bak') t.add('b.txt',arcname='b.bak') t.close() #tar解压 import tarfile t = tarfile.open('test.tar','r') t.extractall('/tmp') t.close()
3 configparser模块
configparser是用来读取配置文件的包。
配置文件的格式如下:中括号“[ ]”内包含的为section。section 下面为类似于key-value 的配置内容
[db] db_host = 127.0.0.1 db_port = 22 db_user = root db_pass = rootroot [concurrent] thread = 10 processor = 20
初始化:
#使用ConfigParser 首先需要初始化实例,并读取配置文件 import configparser cf = configparser.ConfigParser() cf.read('a.ini')
读取:
#1、获取所有section print(cf.sections()) #2、获取指定section的options print(cf.options('db')) # print(cf.options(cf.sections()[0])) #等同 #3、获取指定section的配置信息 print(cf.items('db')) #4、按照类型读取指定section的option信息(get、getint、getboolean、getfloat) print(cf.get('db','db_host')) #字符串类型 print(cf.getint('db','db_port')) #整型 # print(cf.getboolean()) #布尔型 #print(cf.getfloat()) #浮点型
修改:
#1、设置某个option的值 cf.set('db','db_pass','root123456') cf.write(open('a.ini','w')) #2、添加一个section cf.add_section('test') cf.set('test','bar','python') cf.write(open('a.ini','w')) #3、删除一个section或option cf.remove_option('test','bar') cf.remove_section('test') cf.write(open('a.ini','w'))
判断:
#1、判断某个section是否存在 print(cf.has_section('db')) #2、盘点某个标题下的某个option是否存在 print(cf.has_option('db','db_host'))
4 hashlib模块
hashlib提供了常见的摘要算法,如:SHA1, SHA224, SHA256, SHA384, SHA512,MD5
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)
三个特征:
- 内容相同则hash运算结果相同,内容稍微改变则hash值改变
- 不可逆推
- 相同算法:无论校验多长的数据,得到的hash值长度固定
应用:
import hashlib #1、md5加密 hash = hashlib.md5() hash.update('hello'.encode('utf-8')) hash.update('Yim'.encode('utf-8')) #这两条加起来等同于'hello Yim' print(hash.hexdigest()) #2、sha1加密 hash = hashlib.sha1() hash.update('hello Yim'.encode('utf-8')) print(hash.hexdigest()) #3、添加自定义key进行加密 hash = hashlib.sha1('python'.encode('utf-8')) hash.update('hello Yim'.encode('utf-8')) print(hash.hexdigest()) #4、hmac加密 #hmac内部对我们创建的key和内容进行处理后再加密 import hmac h = hmac.new('python'.encode('utf-8')) h.update('hello Yim'.encode('utf-8')) print(h.hexdigest()) #5、获取大文件的md5 hash = hashlib.md5() with open('a.txt','rb') as f: for line in f: hash.update(line) print(hash.hexdigest()) #6、模拟撞库破解密码 import hashlib passwds = [ 'hello', 'hello word', 'hello yim', 'hello Yim', ] def make_passwd_dict(passwds): dict = {} for i in passwds: hash = hashlib.sha1() hash.update(i.encode('utf-8')) dict[i] = hash.hexdigest() return dict def break_code(cryptograph,passwd_dic): for k,v in passwd_dic.items(): if v == cryptograph: print('密码是:%s'%k) cryptograph = '9c68ef3cca853cd2c1c286bde3534693c9c11ed1' break_code(cryptograph,make_passwd_dict(passwds))
5 subprocess模块
subprocess模块用来生成子进程,并且可以通过管道连接它们的输入、输出、错误,以及获得它们的返回值
subprocess包主要功能是执行外部的命令和程序,与shell类似
import subprocess #执行系统命令 subprocess.Popen(r'dir C:Users',shell=True) #管道,标准输出 res = subprocess.Popen(r'dir C:Users',shell=True,stdout=subprocess.PIPE) print(res.stdout.read().decode('gbk')) #管道,错误输出 res = subprocess.Popen(r'ls C:Users',shell=True,stderr=subprocess.PIPE) print(res.stderr.read().decode('gbk')) #管道,标准输入 res1 = subprocess.Popen(r'dir F:PythonCode est',shell=True,stdout=subprocess.PIPE) res2 = subprocess.Popen(r'findstr xml',shell=True,stdin=res1.stdout,stdout=subprocess.PIPE) print(res2.stdout.read().decode('gbk'))
6 logging模块
Python的logging模块提供了通用的日志系统,可以方便第三方模块或者是应用使用。这个模块提供不同的日志级别,并可以采用不同的方式记录日志,比如文件,HTTP GET/POST,SMTP,Socket等,甚至可以自己实现具体的日志记录方式。
logging模块与log4j的机制是一样的,只是具体的实现细节不同。模块提供logger,handler,filter,formatter。
6.1 简单应用
import logging logging.debug('debug message') logging.info('info message') logging.warning('warn message') logging.error('error message') logging.critical('critical message') #输出: WARNING:root:warn message ERROR:root:error message CRITICAL:root:critical message
默认情况下,logging模块将日志打印到屏幕上(stdout),日志级别为WARNING(即只有级别高于WARNING的日志信息才会输出),日志格式如下:

问题:日志级别等级及设置是怎样的?怎样设置日志的输出方式?比如输出到日志文件中?
6.2 日志级别
|
级别 |
代号 |
使用场景 |
|
CRITICAL |
50 |
严重错误,表明软件已不能继续运行了 |
|
ERROR |
40 |
由于更严重的问题,软件已不能执行一些功能了 |
|
WARNING |
30 |
发生了一些意外,或者不久的将来会发生问题(如磁盘满了)。软件还是在正常工作 |
|
INFO |
20 |
证明事情按预期工作 |
|
DEBUG |
10 |
详细信息,典型地调试问题时会感兴趣 |
|
NOTSET |
0 |
不设置 |
6.3 简单配置
为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
使用:
import logging #通过下面的方式进行简单配置输出方式与日志级别 logging.basicConfig(filename='access.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=logging.INFO) logging.debug('debug message') logging.info('info message') logging.warning('warn message') logging.error('error message') logging.critical('critical message') #access.log内容: 2017-10-26 19:47:38 PM - root - INFO -1 logging模块: info message 2017-10-26 19:47:38 PM - root - WARNING -1 logging模块: warn message 2017-10-26 19:47:38 PM - root - ERROR -1 logging模块: error message 2017-10-26 19:47:38 PM - root - CRITICAL -1 logging模块: critical message
6.4 logging模块对象
Logger:产生日志的对象
Filter:过滤日志的对象
Handler:接收日志然后控制打印到不同的地方(FileHandler用来打印到文件中,StreamHandler用来打印到终端)
Formatter:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
import logging # 1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出 logger = logging.getLogger(__file__) # 2、Filter对象:不常用,略 # 3、Handler对象:接收logger传来的日志,然后控制输出 h1 = logging.FileHandler('t1.log') h2 = logging.FileHandler('t2.log') h3=logging.StreamHandler() #打印到终端 # 4、Formatter对象:日志格式 formmater1=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',datefmt='%Y-%m-%d %H:%M:%S %p',) formmater2=logging.Formatter('%(asctime)s : %(message)s',datefmt='%Y-%m-%d %H:%M:%S %p',) formmater3=logging.Formatter('%(name)s %(message)s',) # 5、为Handler对象绑定格式 h1.setFormatter(formmater1) h2.setFormatter(formmater2) h3.setFormatter(formmater3) # 6、将Handler添加给logger并设置日志级别 logger.addHandler(h1) logger.addHandler(h2) logger.addHandler(h3) logger.setLevel(10) # 7、测试 logger.debug('debug message') logger.info('info message') logger.warning('warn message') logger.error('error message') logger.critical('critical message') #t1.log 2017-10-26 20:12:09 PM - F:/Python/Code/1 logging模块.py - DEBUG -1 logging模块: debug message 2017-10-26 20:12:09 PM - F:/Python/Code/1 logging模块.py - INFO -1 logging模块: info message 2017-10-26 20:12:09 PM - F:/Python/Code/1 logging模块.py - WARNING -1 logging模块: warn message 2017-10-26 20:12:09 PM - F:/Python /Code/1 logging模块.py - ERROR -1 logging模块: error message 2017-10-26 20:12:09 PM - F:/Python/Code/1 logging模块.py - CRITICAL -1 logging模块: critical message #t2.log 2017-10-26 20:12:09 PM : debug message 2017-10-26 20:12:09 PM : info message 2017-10-26 20:12:09 PM : warn message 2017-10-26 20:12:09 PM : error message 2017-10-26 20:12:09 PM : critical message #终端 F:/Python/Code/1 logging模块.py debug message F:/Python/Code/1 logging模块.py info message F:/Python/Code/1 logging模块.py warn message F:/Python/Code/1 logging模块.py error message F:/Python/Code/1 logging模块.py critical message
6.5 Logger与Handler的级别
logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level,但是需要注意的是:
Logger is also the first to filter the message based on a level — if you set the logger to INFO, and all handlers to DEBUG, you still won't receive DEBUG messages on handlers — they'll be rejected by the logger itself. If you set logger to DEBUG, but all handlers to INFO, you won't receive any DEBUG messages either — because while the logger says "ok, process this", the handlers reject it (DEBUG < INFO).
import logging form=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p',) ch=logging.StreamHandler() ch.setFormatter(form) # ch.setLevel(10) ch.setLevel(20) #debug被过滤掉了 l1=logging.getLogger('root') # l1.setLevel(20) l1.setLevel(10) l1.addHandler(ch) l1.debug('l1 debug')
6.6 Logger的继承
import logging # 3、Formatter对象:日志格式 formatter=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',datefmt='%Y-%m-%d %H:%M:%S %p',) # 2、Handler对象:接收logger传来的日志,然后控制输出 ch=logging.StreamHandler() # 4、为Handler对象绑定格式 ch.setFormatter(formatter) #1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出 logger1=logging.getLogger('root') logger2=logging.getLogger('root.child1') logger3=logging.getLogger('root.child1.child2') # 5、将Handler添加给logger并设置日志级别 logger1.addHandler(ch) logger2.addHandler(ch) logger3.addHandler(ch) logger1.setLevel(10) logger2.setLevel(10) logger3.setLevel(10) # 6、测试 logger1.debug('log1 debug') logger2.debug('log2 debug') logger3.debug('log3 debug') #终端 2017-10-26 20:41:00 PM - root - DEBUG -1 logging模块: log1 debug 2017-10-26 20:41:00 PM - root.child1 - DEBUG -1 logging模块: log2 debug 2017-10-26 20:41:00 PM - root.child1 - DEBUG -1 logging模块: log2 debug 2017-10-26 20:41:00 PM - root.child1.child2 - DEBUG -1 logging模块: log3 debug 2017-10-26 20:41:00 PM - root.child1.child2 - DEBUG -1 logging模块: log3 debug 2017-10-26 20:41:00 PM - root.child1.child2 - DEBUG -1 logging模块: log3 debug
6.7 应用
""" logging配置 """ import os import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } def load_my_logging_cfg(): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例 logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__': load_my_logging_cfg()
6.8 logger流示意图

6.9 Django的配置
#logging_config.py LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s][%(message)s]' }, 'simple': { 'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' }, 'collect': { 'format': '%(message)s' } }, 'filters': { 'require_debug_true': { '()': 'django.utils.log.RequireDebugTrue', }, }, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'filters': ['require_debug_true'], 'class': 'logging.StreamHandler', 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'INFO', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切 'filename': os.path.join(BASE_LOG_DIR, "xxx_info.log"), # 日志文件 'maxBytes': 1024 * 1024 * 5, # 日志大小 5M 'backupCount': 3, 'formatter': 'standard', 'encoding': 'utf-8', }, #打印到文件的日志:收集错误及以上的日志 'error': { 'level': 'ERROR', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切 'filename': os.path.join(BASE_LOG_DIR, "xxx_err.log"), # 日志文件 'maxBytes': 1024 * 1024 * 5, # 日志大小 5M 'backupCount': 5, 'formatter': 'standard', 'encoding': 'utf-8', }, #打印到文件的日志 'collect': { 'level': 'INFO', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切 'filename': os.path.join(BASE_LOG_DIR, "xxx_collect.log"), 'maxBytes': 1024 * 1024 * 5, # 日志大小 5M 'backupCount': 5, 'formatter': 'collect', 'encoding': "utf-8" } }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console', 'error'], 'level': 'DEBUG', 'propagate': True, }, #logging.getLogger('collect')拿到的logger配置 'collect': { 'handlers': ['console', 'collect'], 'level': 'INFO', } }, } # ----------- # 用法:拿到俩个logger logger = logging.getLogger(__name__) #线上正常的日志 collect_logger = logging.getLogger("collect") #领导说,需要为领导们单独定制领导们看的日志
二、面向对象
面向过程与面向对象编程的区别:
- 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了
- 面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为
面向过程与面向对象的优缺点:
面向过程:
- 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源
- 缺点:没有面向对象易维护、易复用、易扩展
面向对象:
- 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
- 缺点:性能比面向过程低
1 类与对象
类(class):用来描述具有相同属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法
1.1 类定义
语法:
class ClassName: <statement-1> . . . <statement-N>
实例:
class Student: #会产生一个类的名称空间,用来存放类内部的变量及函数 school = '哈尔滨佛学院' #类的数据属性 def learn(self): #类的函数属性 print('is learning') print(Student.__dict__) #查看类的名称空间 print(Student.school) #实际上,创建一个类之后,可以通过类名访问其属性 #执行结果: {'__module__': '__main__', 'school': '哈尔滨佛学院', 'learn': <function Student.learn at 0x000000000259B8C8>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None} 哈尔滨佛学院
操作类的属性(属性引用):
class Student: school = '哈尔滨佛学院' def learn(self): print('is learning') Student.x = 123456 #增加,实际等同Student.__dict__['x'] = 123456,但Python3不支持这种操作 Student.y = 654321 Student.school = '哈佛' #修改 del Student.y #删除 print(Student.__dict__) #执行结果: {'__module__': '__main__', 'school': '哈佛', 'learn': <function Student.learn at 0x000000000271B8C8>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None, 'x': 123456}
1.2 类对象
实例化:
class Student: school = '哈尔滨佛学院' def learn(self): print('is learning') obj1 = Student() #类名加括号,会产生一个该类的实际存在的对象,该过程称为实例化,其结果obj1也可被称为实例 print(obj1) #obj1是一个空对象 #执行结果: <__main__.Student object at 0x00000000028D97F0>
很多类都倾向于将对象创建为有初始状态的。因此类可能会定义一个名为 __init__() 的特殊方法,像下面这样:
def __init__(self): #类定义了 __init__() 方法的话,类的实例化操作会自动调用 __init__() 方法 self.data = []
__init__() 方法可以有参数,参数通过 __init__() 传递到类的实例化操作上。例如:
class Student: school = '哈尔滨佛学院' def __init__(self,name,age,sex): #在实例化时,产生对象之后执行 self.name = name self.age = age self.sex = sex def learn(self): print('is learning') obj1 = Student('Yim',25,'male') #1、先产生一个空对象obj1 2、Student.__init__(obj1,'Yim',25,'male') print(obj1.__dict__) #查看对象的名称空间 obj1.id = '1' #同样,对象属性也能被引用,等同obj1.__dict__['id'] = '1',Python3是支持的 print(obj1.name,obj1.age,obj1.sex,obj1.id) #执行结果: {'name': 'Yim', 'age': 25, 'sex': 'male'} Yim 25 male 1
1.3 属性查找
class Student: school = '哈尔滨佛学院' def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex def learn(self): print('%s is learning'%self.name) obj1 = Student('Yim',25,'male') obj2 = Student('Jim',18,'male') print(obj1.school) # obj1和obj2都能访问类里面的数据属性 print(obj2.school) print(id(obj1.school)) #属性id也一致,类的数据属性是共享给所有对象的 print(id(obj2.school)) print(obj1.learn) #类的函数属性是绑定给所有对象的(绑定方法),内存地址也不一样 print(obj2.learn) obj1.learn() #绑定给谁,就由谁来调用,谁来调用就把谁本身当做第一个参数传入(自动传值) #执行结果: 哈尔滨佛学院 哈尔滨佛学院 40210192 40210192 <bound method Student.learn of <__main__.Student object at 0x00000000026F9128>> <bound method Student.learn of <__main__.Student object at 0x00000000026F9160>> Yim is learning
class Student: school = '哈尔滨佛学院' def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex def learn(self): print('%s is learning'%self.name) obj1 = Student('Yim',25,'male') obj2 = Student('Jim',18,'male') obj1.school = '哈佛' #修改obj1属性 print(obj1.school) #查找顺序:对象-->类 print(obj2.school) #obj2不受影响 #执行结果: 哈佛 哈尔滨佛学院
给类加一个计数器功能,每实例化一次就加1
class Student: count = 0 school = '哈尔滨佛学院' def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex Student.count += 1 def learn(self): print('%s is learning'%self.name) obj1 = Student('Yim',25,'male') obj2 = Student('Jim',18,'male') print(Student.count) print(obj1.count) #执行结果: 2 2
2 继承
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待
继承的功能之一就是用来解决代码重用的问题
语法:
class DerivedClassName(BaseClassName1): <statement-1> . . . <statement-N>
实例:
class ParentClass1: #定义父类(基类) pass class ParentClass2: #定义父类(基类) pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类(子类)是SubClass1 pass class SubClass2(ParentClass1,ParentClass2): #多继承,用逗号分隔 pass #查看继承 print(SubClass1.__bases__) #查看所有继承的父类 print(SubClass2.__bases__) #执行结果: (<class '__main__.ParentClass1'>,) (<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
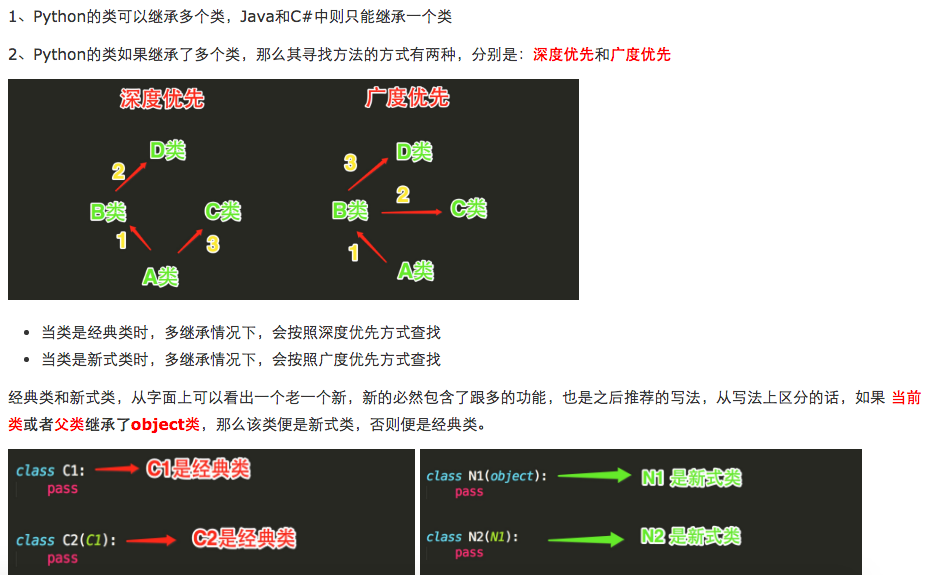
经典类与新式类:
1.只有在python2中才分新式类和经典类,python3中统一都是新式类
2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类
3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类
4.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类
#python2 >>> class Foo:pass ... >>> Foo.__bases__ () #python3 >>> class Foo:pass ... >>> Foo.__bases__ (<class 'object'>,) #如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现
解决代码重用实例:
class People: school = '哈佛' def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex def eat(self): print('%s is eating' %self.name) class Student(People): def learn(self): print('%s is learning' %self.name) class Teacher(People): def teach(self): print('%s is teachning' % self.name) S_obj1 = Student('Yim',25,'male') T_obj1 = Teacher('Jim',18,'male') print(S_obj1.name,S_obj1.age,S_obj1.sex) S_obj1.learn() T_obj1.teach() #执行结果: Yim 25 male Yim is learning Jim is teachning
重用父类的方法:
class Animal: def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex def eat(self): print('%s eat' %self.name) def talk(self): print('%s say' %self.name) class People(Animal): def __init__(self,name,age,sex,education): Animal.__init__(self,name,age,sex) #调用父类方法,也可以不依赖于继承 self.education=education def talk(self): Animal.talk(self) #调用父类方法,也可以不依赖于继承 print('这是人在说话') peo1=People('Yim',25,'male','幼儿园毕业') print(peo1.__dict__) peo1.talk() #执行结果: {'name': 'Yim', 'age': 25, 'sex': 'male', 'education': '幼儿园毕业'} Yim say 这是人在说话
3 方法重写
如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
class Parent: # 定义父类 def myMethod(self): print ('调用父类方法') class Child(Parent): # 定义子类 def myMethod(self): print ('调用子类方法') c = Child() # 子类实例 c.myMethod() # 子类调用重写方法 #执行结果: 调用子类方法
4 组合
组合指的是:在一个类中以另外一个类的对象作为数据属性,称为类的组合
实例:
class People: school = '哈佛' def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex class Student(People): def __init__(self,name,age,sex): People.__init__(self,name,age,sex) self.course = [] #学生可以学习多名课程 def tell_info(self): print('<name:%s age:%s sex:%s>' %(self.name,self.age,self.sex)) class Teacher(People): def __init__(self,name,age,sex): People.__init__(self,name,age,sex) self.course = [] #老师可以教多名课程 self.students = [] #老师可以教多个学生 class Course: #单独定义一个course类 def __init__(self,course_name,course_period,course_price): self.course_name=course_name self.course_period=course_period self.course_price=course_price def tell_info(self): print('<课程名:%s 周期:%s 价格:%s>' %(self.course_name,self.course_period,self.course_price)) S_obj1 = Student('Yim',25,'male') S_obj2 = Student('Lin',22,'male') T_obj1 = Teacher('Jim',18,'male') python = Course('Python','6mons',100) java = Course('Java','10mons',200) T_obj1.course.append(python) #把课程加进去 T_obj1.course.append(java) T_obj1.students.append(S_obj1) #把学生加进去 T_obj1.students.append(S_obj2) S_obj1.course.append(python) for i in T_obj1.course: #查看老师教的课程 i.tell_info() #Course('Python','6mons',100).tell_info() Course('Java','10mons',200).tell_info() for i in T_obj1.students: #查看老师有多少名学生 i.tell_info() for i in S_obj1.course: #查看学生学习的课程 i.tell_info() #执行结果: <课程名:Python 周期:6mons 价格:100> <课程名:Java 周期:10mons 价格:200> <name:Yim age:25 sex:male> <name:Lin age:22 sex:male> <课程名:Python 周期:6mons 价格:100>
5 继承实现原理
继承顺序:
实例:
class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类
6 子类中调父类的方法
方法一:父类名.父类方法()
class Animal: def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex def eat(self): print('%s eat' %self.name) def talk(self): print('%s say' %self.name) class People(Animal): def __init__(self,name,age,sex,education): Animal.__init__(self,name,age,sex) #调用父类方法,也可以不依赖于继承 self.education=education def talk(self): Animal.talk(self) #调用父类方法,也可以不依赖于继承 print('这是人在说话') peo1=People('Yim',25,'male','幼儿园毕业') print(peo1.__dict__)
方法二:super(),这种方法依赖于继承,从MRO列表当前的位置往后找
class Animal: def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex def eat(self): print('%s eat' %self.name) def talk(self): print('%s say' %self.name) class People(Animal): def __init__(self,name,age,sex,education): super().__init__(name,age,sex) #python2:super(People.self).__init__() self.education=education def talk(self): super().__init__(self) print('这是人在说话') peo1=People('Yim',25,'male','幼儿园毕业') print(peo1.__dict__)
7 绑定方法与非绑定方法
1、绑定方法:绑定给谁,就由谁来调用,谁来调用就把谁本身当做第一个参数传入(自动传值)
绑定到类的方法:用classmethod装饰器装饰的方法
- 为类量身定制
- 类.bound_method(),自动将类当做第一个参数传入
- 其实对象也可调用,但仍将类当作第一个参数传入
绑定到对象的方法:没有被任何装饰器装饰的方法
- 为对象量身定制
- 对象.bound_method(),自动将对象作为第一个参数传入
- 属于类的函数,类可以调用,但是必须按照函数的规则来,没有自动传值那么一说
实例:
#配置文件settings.py HOST='127.0.0.1' PORT=3306
import settings class Mysql: def __init__(self,host,port): self.host = host self.port = port @classmethod def from_conf(cls): #绑定给类 return cls(settings.HOST,settings.PORT) def fun1(self): #绑定给对象 pass conn = Mysql.from_conf() print(conn.host,conn.port) #执行结果: 127.0.0.1 3306
2、非绑定方法:在类内部用staticmethod装饰器装饰的函数即非绑定方法,就是普通函数。statimethod不与类或对象绑定(应用场景),谁都可以调用,没有自动传值效果
import uuid class Mysql: def __init__(self,host,port): self.host = host self.port = port self.id = self.create_uuid() #调用create_uuid函数 @staticmethod def create_uuid(): #普通函数,没有自动传值效果 return str(uuid.uuid1()) conn = Mysql('127.0.0.1',3306) print(conn.id) #执行结果: ea5637e8-8199-11e7-962a-34de1a770c8f
8 接口与归一化设计
接口提取了一群类共同的函数,可以把接口当做一个函数的集合。让子类去实现接口中的函数
在Python中没有一个叫做interface的关键字,如果模仿接口的概念,可以借助第三方模块:http://pypi.python.org/pypi/zope.interface,也可以使用继承
实例:
class Interface:#定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字来定义一个接口。 def read(self): #定接口函数read pass def write(self): #定义接口函数write pass class Txt(Interface): #文本,具体实现read和write def read(self): print('文本数据的读取方法') def write(self): print('文本数据的写方法') class Sata(Interface): #磁盘,具体实现read和write def read(self): print('硬盘数据的读取方法') def write(self): print('硬盘数据的写方法') class Process(Interface): def read(self): print('进程数据的读取方法') def write(self): print('进程数据的写方法')
9 抽象类
抽象类是一个特殊的类,只能被继承不能被实例化,在Python中需要借助模块实现。以下是一个实例:
import abc class Interface(metaclass=abc.ABCMeta): @abc.abstractmethod def read(self): pass @abc.abstractmethod def write(self): pass class Txt(Interface): def read(self): #必须要有read print('文本数据的读取方法') def write(self): #必须要有write print('文本数据的写方法')
10 多态
是允许将父对象设置成为和一个或多个它的子对象相等的技术,比如Parent:=Child; 多态性使得能够利用同一类(基类)类型的指针来引用不同类的对象,以及根据所引用对象的不同,以不同的方式执行相同的操作
Python不直接支持多态,但可以间接实现
实例:
import abc class Animal(metaclass=abc.ABCMeta): #同一类事物:动物 @abc.abstractmethod def talk(self): pass class People(Animal): #动物的形态之一:人 def talk(self): print('say hello') class Dog(Animal): #动物的形态之二:狗 def talk(self): print('say wangwang') def func(animal): animal.talk() p = People() d = Dog() func(p) func(d) #执行结果: say hello say wangwang
11 封装
“封装”就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体(即类);封装的目的是增强安全性和简化编程,使用者不必了解具体的实现细节,而只是要通过外部接口,一特定的访问权限来使用类的成员
实例:
#这种隐藏不是真正意义上的隐藏,其实这仅仅是一种变形操作,只在类定义阶段发生的 #类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式 #在子类定义的__x不会覆盖在父类定义的__x class Foo: __N = 123456 #变形为_Foo__N def __init__(self,name): self.name = name def __f1(self): #变形为_Foo__f1 print('f1') def bar(self): self.__f1() #只有在类内部才可以通过__f1的形式访问到 f = Foo('Yim') print(Foo.__dict__) #print(Foo.__N) #外部无法直接访问 f.bar() #执行结果: {'__module__': '__main__', '_Foo__N': 123456, '__init__': <function Foo.__init__ at 0x00000000025FB8C8>, '_Foo__f1': <function Foo.__f1 at 0x00000000025FB950>, 'bar': <function Foo.bar at 0x00000000025FB9D8>, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__doc__': None} f1
class People: def __init__(self,name,age,sex): self.__name = name self.__age = age self.__sex = sex def tell_info(self): print('<名字:%s 年龄:%s 性别:%s>' %(self.__name,self.__age,self.__sex)) def set_info(self,x,y,z): #可以定制一些控制逻辑来控制使用者对数据的操作 if not isinstance(x,str): raise TypeError if not isinstance(y,int): raise TypeError if not isinstance(z,str): raise TypeError self.__name = x self.__age = y self.__sex = z p = People('Yim',25,'male') p.set_info('Zim',18,'male') p.tell_info()
#取款是功能,而这个功能有很多功能组成:插卡、密码认证、输入金额、打印账单、取钱 #对使用者来说,只需要知道取款这个功能即可,其余功能我们都可以隐藏起来,很明显这么做 #隔离了复杂度,同时也提升了安全性 class ATM: def __card(self): print('插卡') def __auth(self): print('用户认证') def __input(self): print('输入取款金额') def __print_bill(self): print('打印账单') def __take_money(self): print('取款') def withdraw(self): #隔离复杂度 self.__card() self.__auth() self.__input() self.__print_bill() self.__take_money() a=ATM() a.withdraw()
静态属性property:property是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值
#计算体质指数(BMI) #体质指数(BMI)=体重(kg)÷身高^2(m) class People: def __init__(self,name,weight,height): self.name = name self.weight = weight self.height = height @property def bmi(self): return self.weight / (self.height ** 2) p = People('Yim',70,1.80) # print(p.bmi()) print(p.bmi)
三 面向对象进阶
1 isinstance和issubclass
class Foo(): pass obj = Foo() print(isinstance(obj,Foo)) #检查obj是否是类cls的对象,返回BOOL值
class Foo(): pass class Bar(Foo): pass print(issubclass(Bar,Foo)) #检查sub类是否是super类的派生类,返回BOOL值
2 反射
通过字符串的形式操作对象相关的属性
class Foo: x = 1 def __init__(self,name): self.name = name def f1(self): print('from f1') f = Foo('Yim') # print(f.name) print(hasattr(f,'name')) #hasattr(object, name),判断一个对象里面是否有name属性或者name方法,返回BOOL值 print(getattr(f,'name')) #getattr(object, name[,default]),获取对象object的属性或者方法,如果存在打印出来,如果不存在,打印出默认值,默认值可选 setattr(f,'name','Jim') #setattr(object, name, values),给对象的属性赋值,若属性不存在,先创建再赋值 delattr(f,'name') #delattr(object, name),删除指定对象的指定名称的属性,和setattr函数作用相反
3 item系列
class testsetandget: kk = {}; def __getitem__(self, key): return self.kk[key]; def __setitem__(self, key, value): self.kk[key] = value; a = testsetandget() a['first'] = 1 print(a['first']) #执行结果: 1
4 打印对象信息__str__
class People: def __init__(self,name,age,sex): self.name = name self.age = age self.sex =sex def __str__(self): #在对象被打印时触发执行 return '<name:%s age:%s sex:%s>' %(self.name,self.age,self.sex) p = People('Yim',25,'male') print(p) #执行结果: <name:Yim age:25 sex:male>
5 析构方法__del__
典型的应用场景:
创建数据库类,用该类实例化出数据库链接对象,对象本身是存放于用户空间内存中,而链接则是由操作系统管理的,存放于内核空间内存中
当程序结束时,python只会回收自己的内存空间,即用户态内存,而操作系统的资源则没有被回收,这就需要我们定制__del__,在对象被删除前向操作系统发起关闭数据库链接的系统调用,回收资源
class Foo: def __init__(self,x): self.x = x def __del__(self): #在对象资源被释放时触发 print('del...........') f = Foo(11111) #执行结果: del...........