1.开篇
最近几个月因为项目的原因,接手了半监督学习在文本分类中应用的课题,所以很认真地学习了相关的内容,包括半监督学习、文本分析、传统分类方法、深度学习分类等等。
为了更好的巩固自己所学,所以尝试把看到的比较易懂的内容拿过来和大家分享,也算是自己的一次梳理汇总和学习。本篇介绍传统的分类方法和半监督学习算法之生成式方法,使用naive bayes模型的生成式半监督学习方法对分本进行分类,来自:附录1。
2.缩写介绍
NB——Naive Bayes
SSL——Semi-Supervised Learning
TC——Text Classification
EM——Expectation Maximization
SVM——Support Vector Machine
3.问题定义
1)随着训练文本数量的增加,文本分类的准确率也在上升,但传统分类器是使用有标记的样本进行训练的
2)然而对样本进行标注是困难、耗时、昂贵的,因为这项任务一般需要由专门的、有经验的人工标注员来完成
3)未标注样本相对容易收集,因此可以考虑使用半监督学习,充分利用未标注和已标注的样本训练分类器,因此当有标注样本数量少时研究半监督学习是非常有意义的
半监督学习介于有监督学习和无监督学习之间,对它的研究目前也非常多,常见于图像、文本、生物信息学等拥有大量未标注数据的应用领域。
由下图可见,使用和不使用未标记样本,得到的分类器是不一样的。
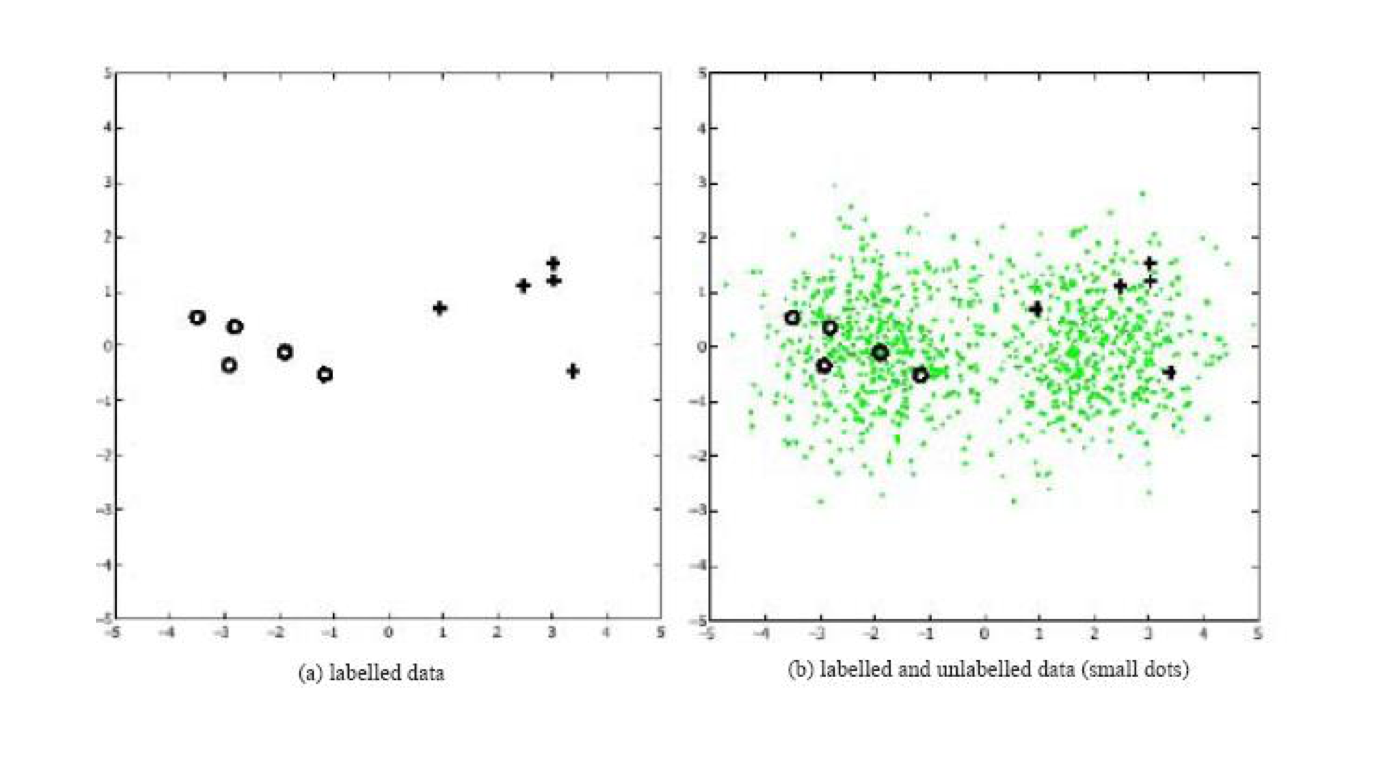
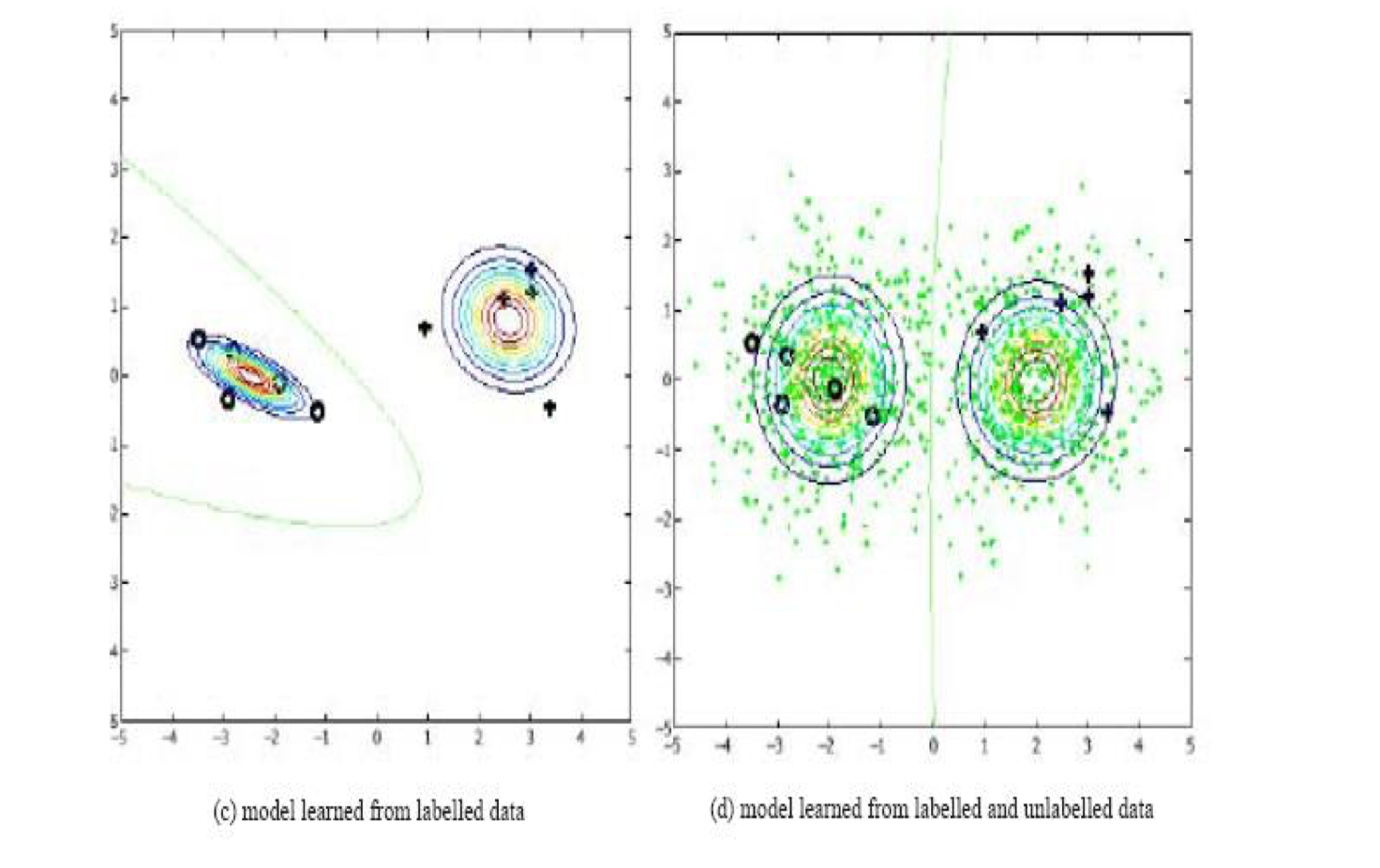
4.文本分类的流程
有监督分类流程:
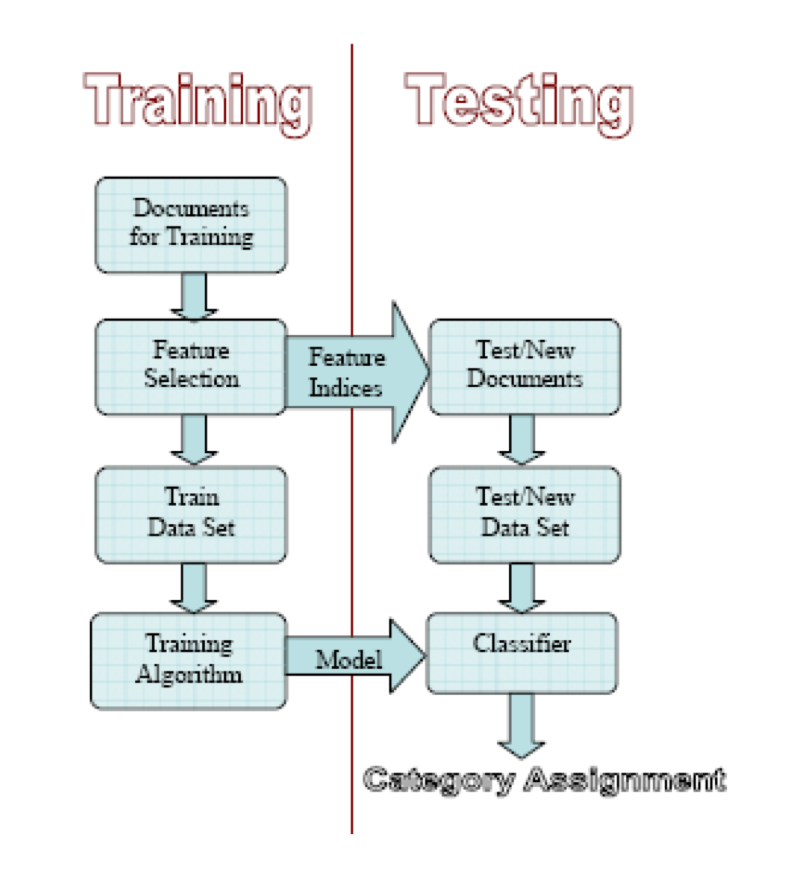
文本预处理流程:
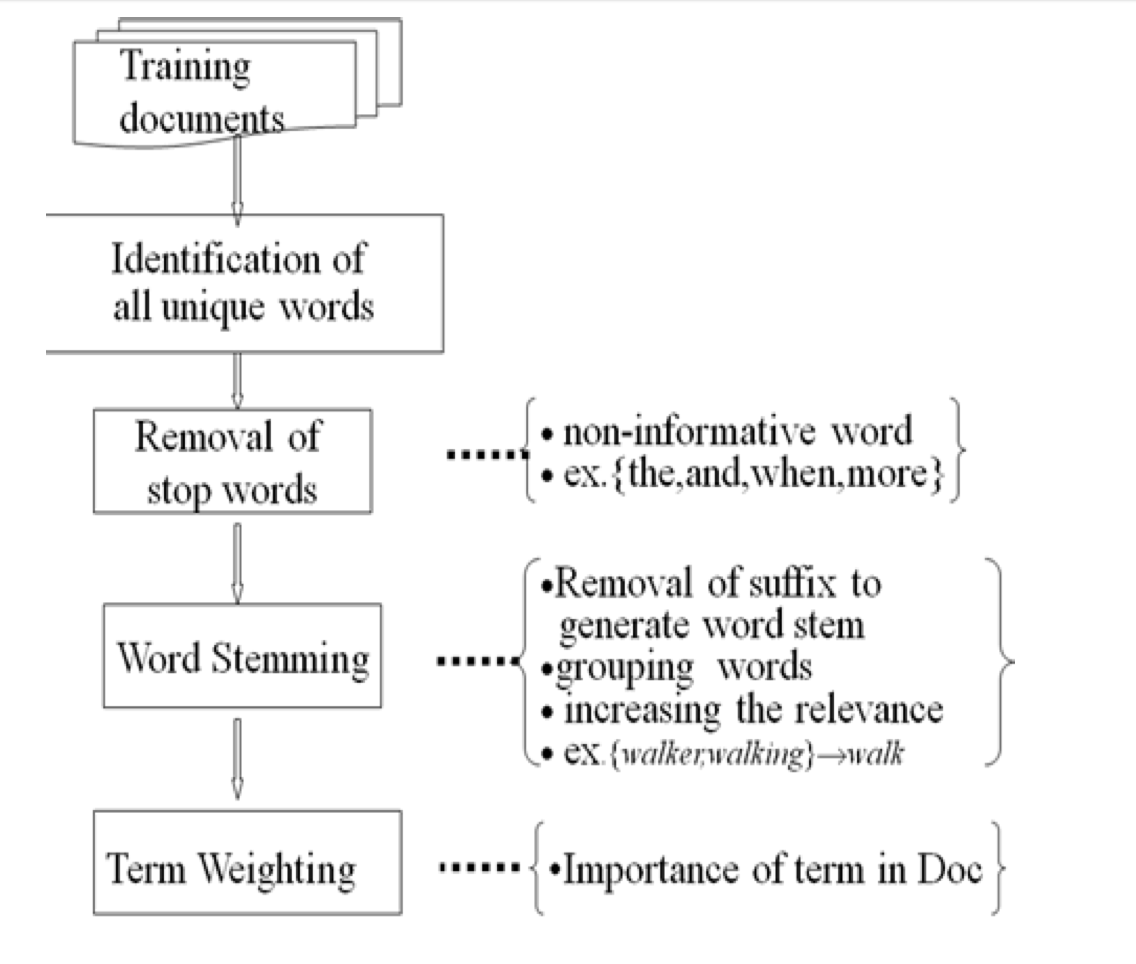
词频和文本频率计算:

使用朴素贝叶斯的例子简介:

5.半监督学习方法简介
半监督学习方法主要分为以下四类:
1)半监督SVM
2)基于图的半监督学习
3)生成式方法
4)基于分歧的方法(co-training,multi-view...)
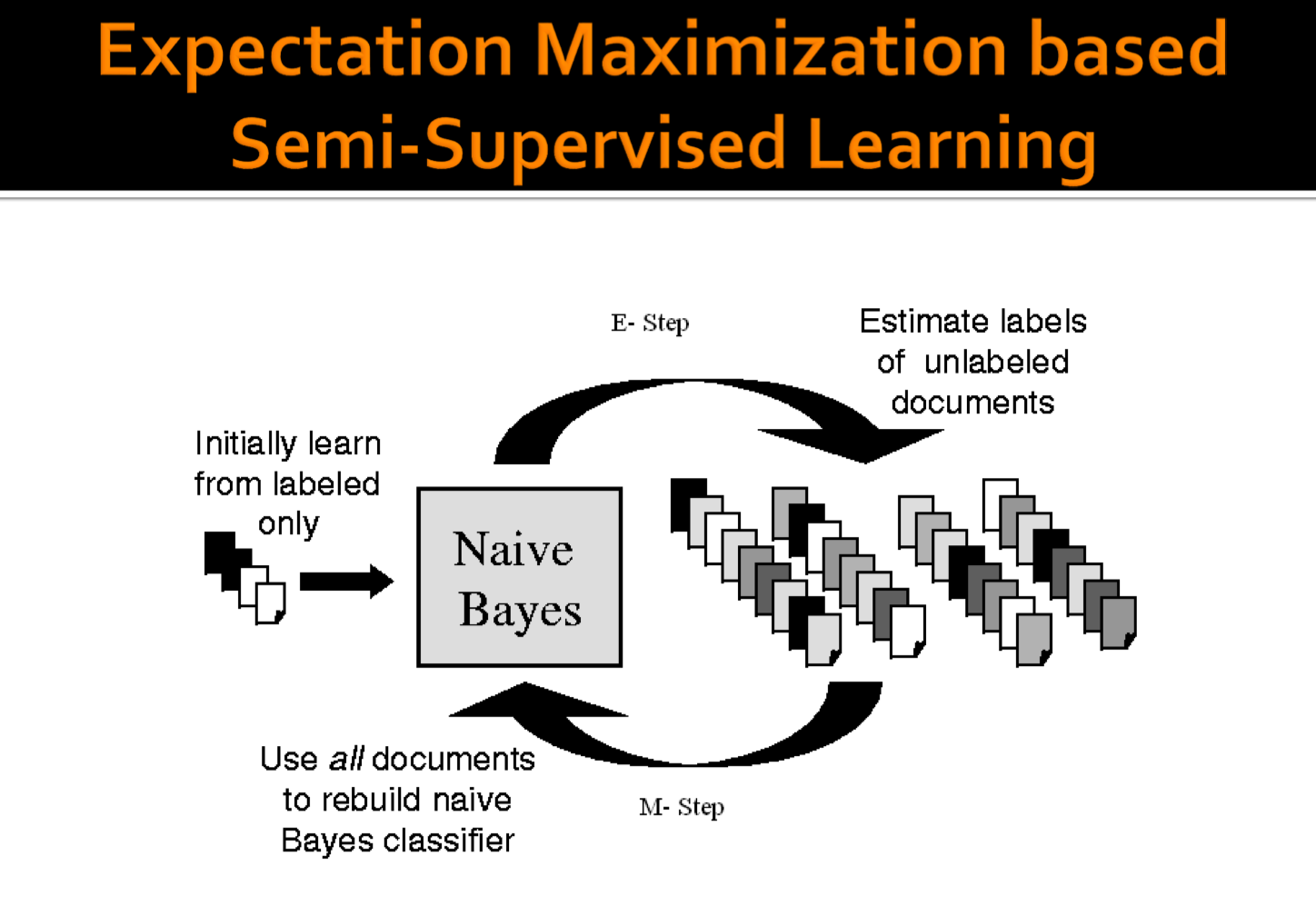
6.基于朴素贝叶斯模型的生成式半监督方法
基于EM算法的半监督学习,使用朴素贝叶斯模型作分类器:

7.改进
可以考虑同时使用朴素贝叶斯(Bayes)和支持向量机(Support Vector Machine,SVM)模型,然后进行投票,并且在下一次迭代中只考虑NB和SVM预测相同标签的那些无标签文档,并丢弃其余的未标签文档。详细做法参见链接中参考论文。
8.参考
附录1:Semi-Supervised Text Classification: A New Extension for RapidMiner