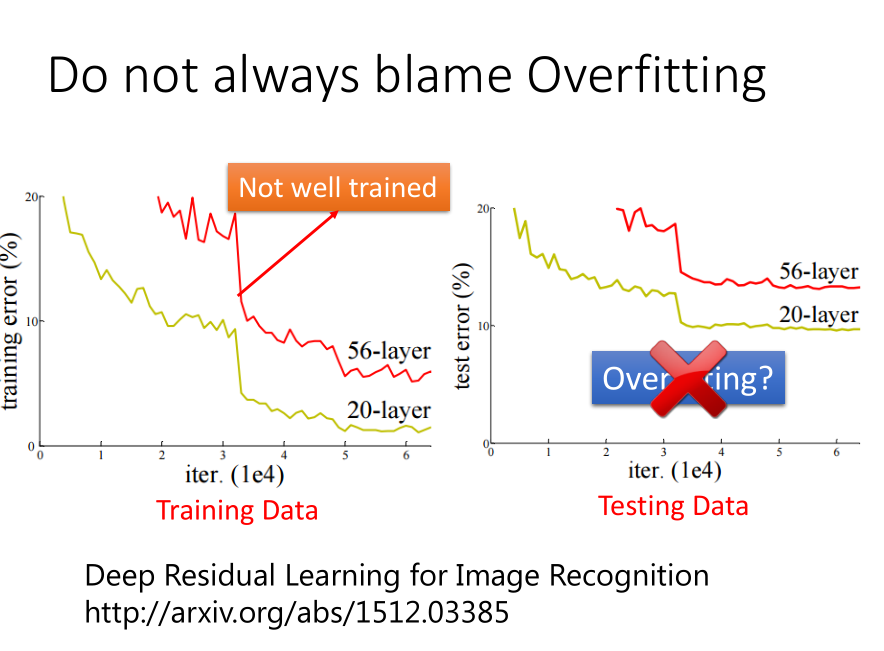
神经网络的表现
在Training Set上表现不好 ----> 可能陷入局部最优
在Testing Set上表现不好 -----> Overfitting 过拟合
虽然在机器学习中,很容易通过SVM等方法在Training Set上得出好的结果,但DL不是,所以得先看Training Set上的表现。
要注意方法适用的阶段:
比如:dropout方法只适合于:在Training Data上表现好,在Testing Data上表现不好的。
如果在Training Data上就表现不好了,那么这个方法不适用。
神经网络的改进

1. New Activation Function
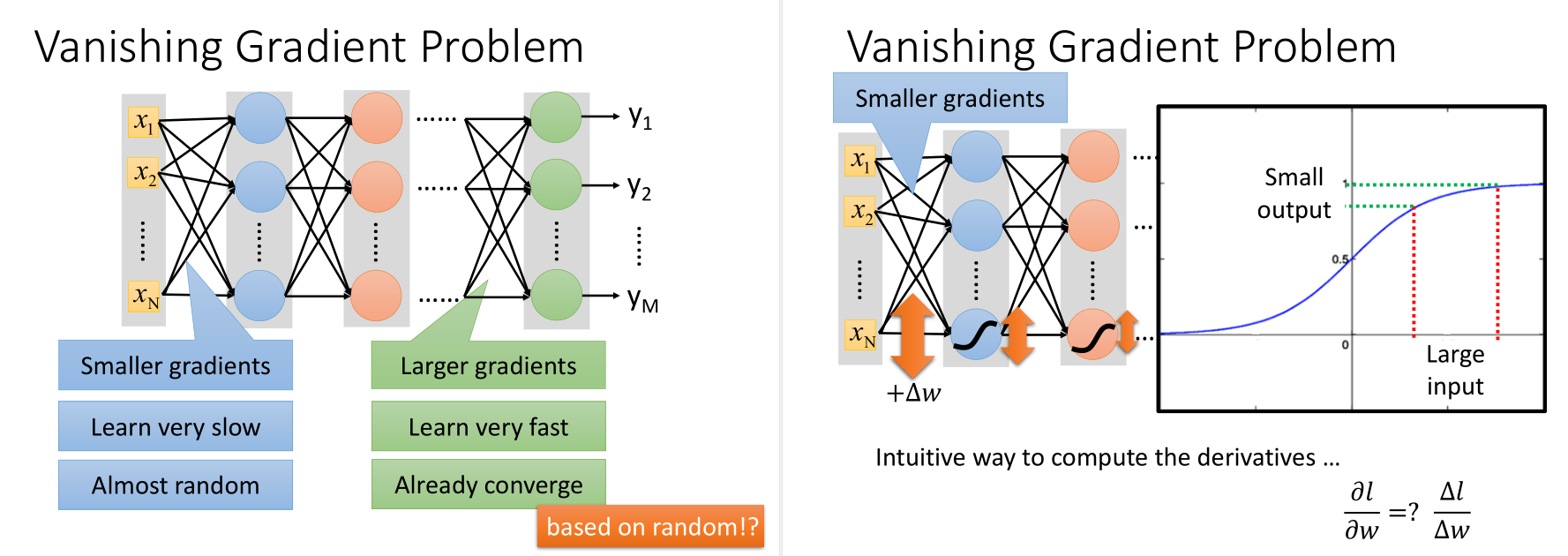
梯度消失:在输入层附近梯度小,在输出层梯度大,当参数还没有更新多少时,在输出层已经收敛了,这是激活函数(sigmoid)对值压缩的问题。
也就是一个比较大的input进去,出来的output比较小,所以最后对total loss的影响比较小,趋于收敛。
1.1 ReLU
如何解决梯度消失?
修改activation function为ReLU(Rectified Linear Unit),
ReLU input 大于0时,input 等于 output,input小于0时,output等于0。

其中,output为0的neural可以去掉,得到一个thinner linear network。
虽然局部是线性的,但这个network从总体上来说还是非线性的。

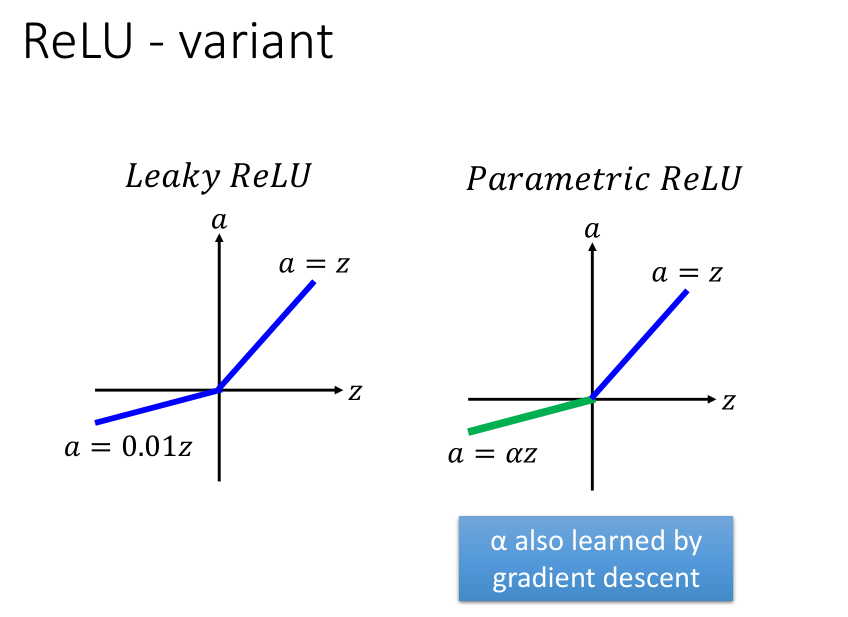
input小于0的部分,微分为0,这样就没法很好地更新参数了,所以有以下两种方法改进。
leaky ReLU,Parametric ReLU。
1.2 Maxout
此外,还可以通过Maxout自动学习activation function。ReLU是一种特殊的Maxout。
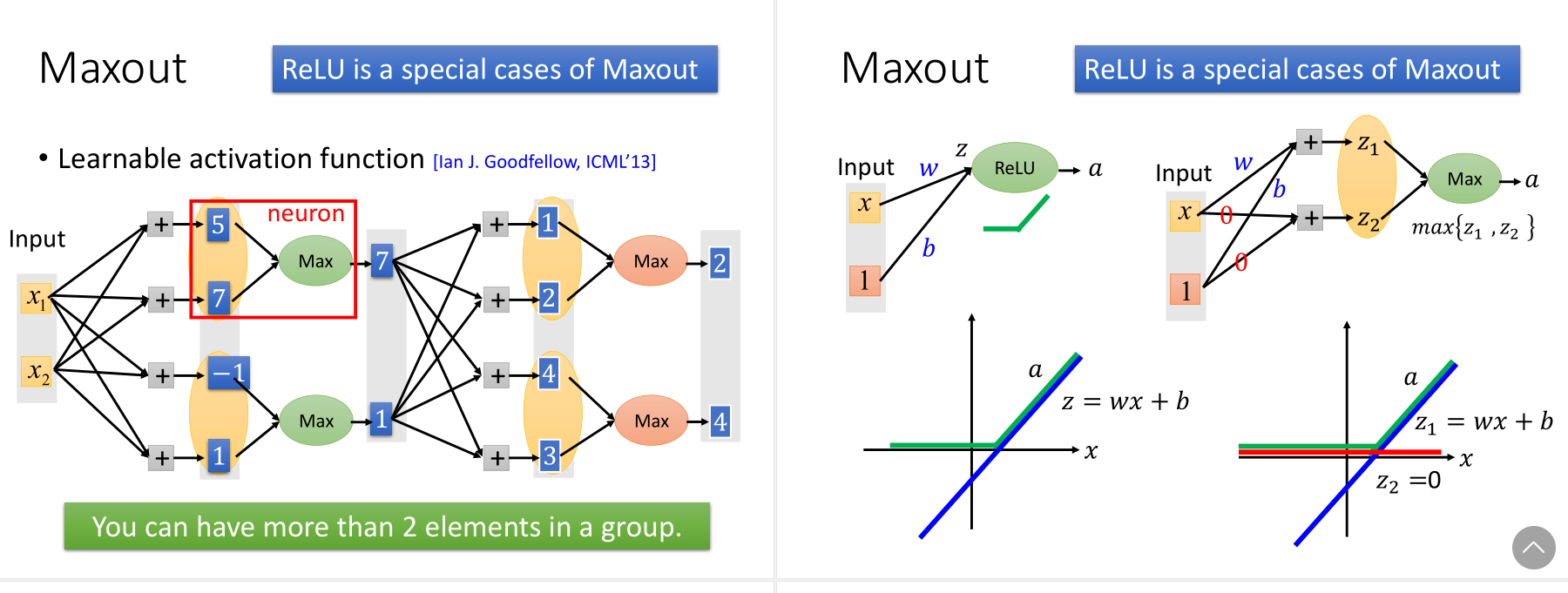
此外maxout可以与ReLU不同,如下图所示,可以有更灵活的形状,更多的piece(即更多的element)。

因为不是max的部分可以先去掉,所以可以不用train那些w,先train线性的局部。
当然,因为训练数据很多,最后都会被train到。

2. Adaptive Learning Rate
在Adagrad的基础上,Hinton提出了RMSProp方法。

对于local minimum的问题,因为每一个dimension都在谷底的情况很少,所以local minimum并没有那么多。
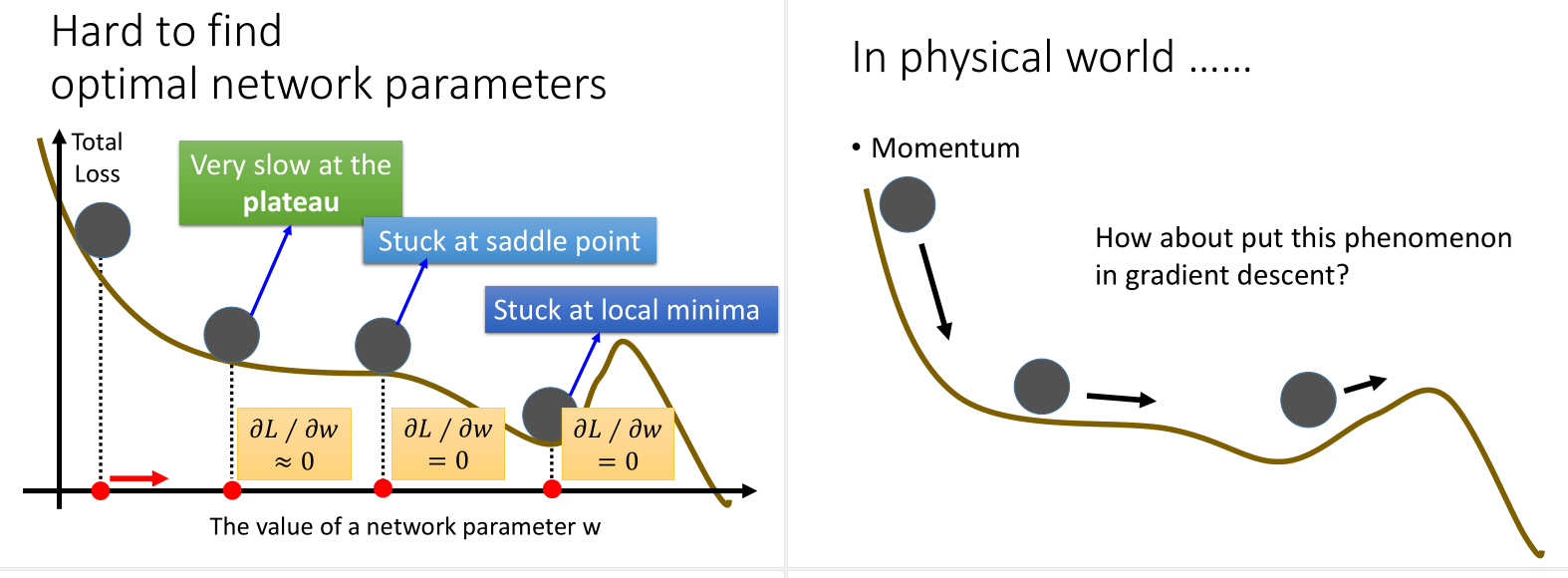
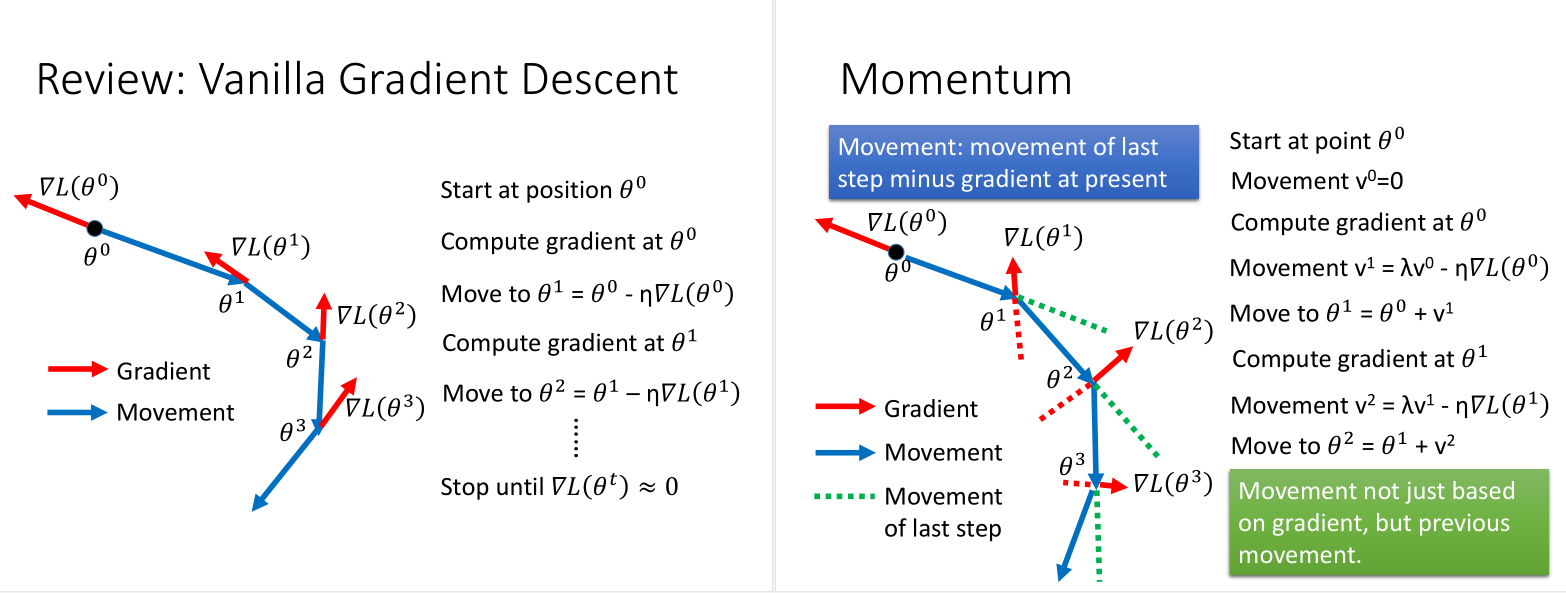
当然解决这个问题,有个Momentum的方法,模拟滚动的物理现象,加上惯性。
Adam方法,RMSProp + Momentum。

如果说在Testing Data上表现不好,可以用以下三种方法。
3. Early Stopping
用验证集去模拟测试集,在Testing Set表现开始变得不好的时候,停止Training。

4. Regularization
打个比方:小孩从出生到六岁,神经网络越来越多,但六岁以后开始变少。

在原来的Loss Function(minimize square error, cross entropy)的基础上加Regularization这一项(L2),不会加bias这一项,加Regularization的目的是让曲线更加平滑。
L2 Regularization 也叫 Weight Decay,这样每次都会让weight小一点。最后会慢慢变小趋近于0,但是会与后一项梯度的值达到平衡,使得最后的值不等于0。

用L1 Regularization也是可以的。
L2下降的很快,很快就会变得很小,在接近0时,下降的很慢,会保留一些接近01的值;
L1的话,减去一个固定的值(比较小的值),所以下降的很慢。
所以,通过L1-Norm training 出来的model,参数会有很大的值。

5. Dropout
对network里面的每个neural(包括input),做sampling(抽样)。 每个neural会有p%会被丢掉,跟着的weight也会被丢掉。
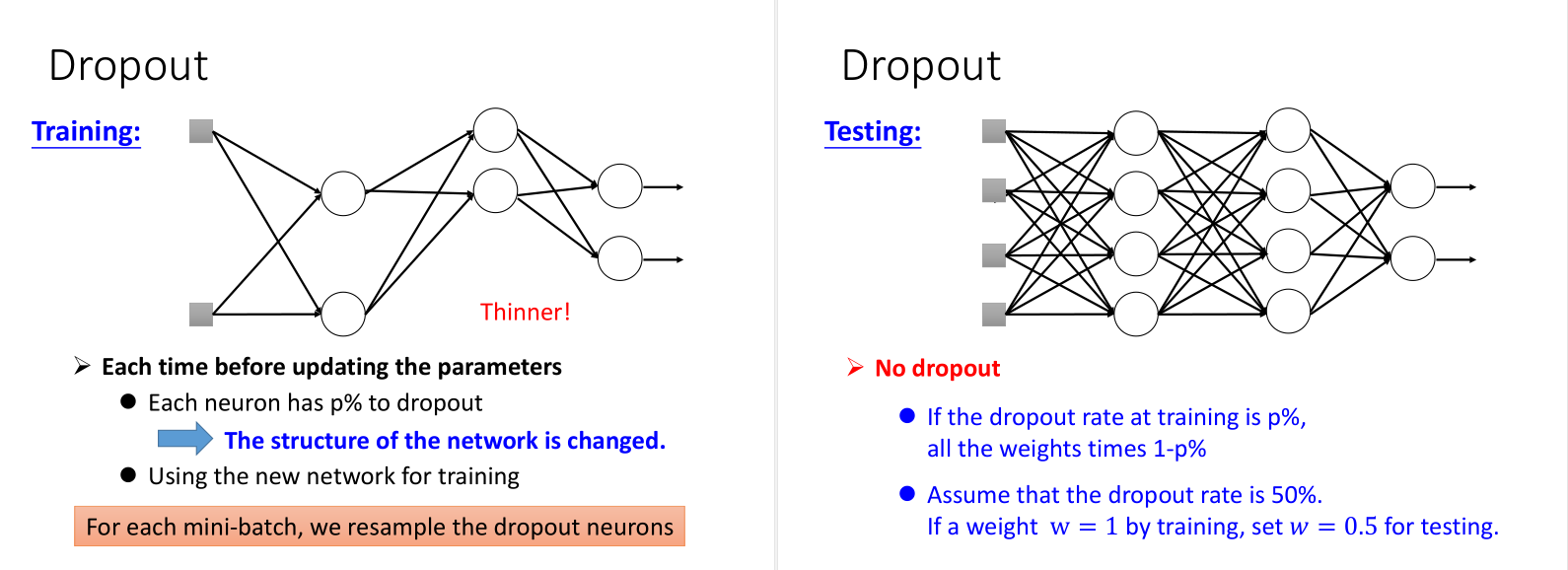
形象理解:(练武功&团队合作)

Dropout就是一种终极的集成学习 Ensemble。
可以理解为,因为有很多的model,Structure都不一样,
虽然每个model可能variance很大,但是如果它们都是很复杂的model时,平均起来时bias就很小,所以就比较准了。

如果直接将weight乘以 (1-p%),结果之前做average的结果跟output y是approximated。
