一、概述
本实验做的是一个很常见的数据挖掘任务:新闻文本分类。
语料库来自于搜狗实验室2008年和2012年的搜狐新闻数据,
下载地址:https://www.sogou.com/labs/resource/cs.php
实验工作主要包括以下几步:
1)语料库的数据预处理;
2)文本建模;
3)训练分类器;
4)对测试集文本分类;
5)结果评估。
二、实验环境搭建
本实验在Google Drive平台进行,利用平台免费的运算资源以及存储空间,使用Colaboratory实验环境完成。
不过Colab分配的环境是临时环境,文件不会一直保存,所以实验的第一步是连接Google Drive, 将相关文件保存在Drive里,便于访问和保存。
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
!mkdir -p drive
!google-drive-ocamlfuse drive
import os
os.chdir("drive")
!ls
三、语料库的构建
本实验所采用的语料库是来自于搜狗实验室的搜狐新闻数据,包括2008年和2012年的新闻数据,我并从中选取了11种新闻分类的数据作为实验所需的训练和测试数据。
2012年新闻数据的文件格式是dat,编码格式为gb2312,数据组织形式为xml。
2008年的新闻数据解压后则是若干个txt文件,不过编码格式也是gb2312,数据组织形式也是xml,格式一致。
从精简版的示例数据,下图可以看到数据的格式。

处理步骤如下:
1)将文件编码格式转为utf-8;
2)用正则表达式匹配出其中的url和content部分;
3)从url中抽取出二级域名字段作为该文本的类别标签(content为文本内容);
4)忽略过长或过短的文本,统计阈值[30, 3000]内各类别下的文本数量,并排序展示;
5)从中选取适合做分类任务的11种分类:科技,汽车,股票,娱乐,体育,财经,健康,教育,女性,旅游,房地产,共计137万篇文本数据;
6)最后将所需要的数据保存为pkl文件。
# 以下实验所需要的包
import os
import re
import math
import operator
import chardet
import pickle
import jieba
import random
import datetime
from collections import defaultdict
from chardet import detect
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score
1. 2012年新闻数据的处理
#转换2012年新闻数据的文件格式及编码格式
!cat news_sohusite_xml.dat | iconv -f gbk -t utf-8 -c > corpus.txt
#各类别文章统计
def cate_statistics(path):
classfiy = {} #各类别下的文章数
total = 0 #文章总数
cnt_gt = 0 #大于阈值长度的文章数
cnt_lt = 0 #小于阈值长度的文章数
f = open(path)
articles = f.readlines()
f.close()
for i in range(len(articles)//6):
line = articles[i*6+1]
content = articles[i*6+4]
line = re.sub('<url>|</url>','',line)
content = re.sub('<content>|</content>', '', content)
url_split = line.replace('http://', '').split('.')
sohu_index = url_split.index('sohu')
if len(content) > 30 and len(content) < 3000:
if url_split[sohu_index-1] not in classfiy.keys():
classfiy[url_split[sohu_index-1]] = 1
else:
classfiy[url_split[sohu_index-1]] += 1
total += 1
elif (len(content) <= 30):
cnt_lt += 1
elif (len(content) >= 3000):
cnt_gt += 1
sorted_classfiy = sorted(classfiy.items(), key=operator.itemgetter(1), reverse=True) #排序
print("文件名:", path)
print("文件格式示例:")
for i in range(6):
print(articles[i])
print("总共{}篇大小在(30, 3000)内的文章".format(total))
print("小于30字符的文章数:", cnt_lt)
print("大于3000字符的文章数:", cnt_gt)
print("各类别文章统计如下:(>=1000)")
for c in sorted_classfiy:
if c[1] >= 1000:
print(c[0], c[1])
#类别统计
cate_statistics("corpus.txt")
2. 2008年新闻数据的处理
#2008年数据文件格式修改以及txt文件合并
#获取原始语料文件夹下文件列表
def listdir_get(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir_get(file_path, list_name)
else:
list_name.append(file_path)
#修改文件编码为utf-8
def code_transfer(list_name):
for fn in list_name:
with open(fn, 'rb+') as fp:
content = fp.read()
print(fn, ":现在修改")
codeType = detect(content)['encoding']
content = content.decode(codeType, "ignore").encode("utf8")
fp.seek(0)
fp.write(content)
print(fn, ":已修改为utf8编码")
fp.close()
#合并各txt文件
def combine_txt(data_original_path, list_name, out_path):
cnt = 0 #未正确读取的文件数
for name in list_name:
try:
file = open(name, 'rb')
fp = file.read().decode("utf8")
except UnicodeDecodeError:
cnt += 1
print("Error:", name)
file.close()
continue
print(name)
corpus_old = open(out_path, "a+", encoding="utf8")
corpus_old.write(fp)
corpus_old.close()
file.close()
print("共:", cnt, "文件未正确读取")
#2008年数据文件格式修改以及txt文件合并
#原始语料路径
data_original_path = "./SogouCS/"
out_path = "./corpus_old.txt"
#获取文件路径
list_name = []
listdir_get(data_original_path, list_name)
#修改编码
code_transfer(list_name)
#合并各txt文件
combine_txt(data_original_path, list_name, out_path)
#类别统计
cate_statistics("corpus_old.txt")
3. 数据选取:选用部分类别数据
#读取原始文件
f = open("corpus.txt")
article_list1 = f.readlines()
f.close()
f = open("corpus_old.txt")
article_list2 = f.readlines()
f.close()
article_list1.extend(article_list2)
labels = [] #文章标签
texts = [] #文章内容
#选取[科技,汽车,股票,娱乐,体育,财经,健康,教育,女性,旅游,房地产]这11种类别数据
classes = ['it', 'auto', 'stock', 'yule', 'sports', 'business', 'health', 'learning', 'women', 'travel', 'house']
for i in range(len(article_list1)//6):
line = article_list1[i*6+1]
content = article_list1[i*6+4]
line = re.sub('<url>|</url>','',line)
content = re.sub('<content>|</content>', '', content)
url_split = line.replace('http://', '').split('.')
sohu_index = url_split.index('sohu')
if len(content) > 30 and len(content) < 3000:
if url_split[sohu_index-1] in classes:
labels.append(url_split[sohu_index-1])
texts.append(content)
cnt_class = list(np.zeros(11))
for label in labels:
for i in range(len(classes)):
if (classes[i] == label):
cnt_class[i] += 1
print("总共{}篇文章".format(len(labels)))
for i in range(len(classes)):
print("类别", classes[i], "数量为:", cnt_class[i])
#保存数据
with open("raw_data.pkl", 'wb') as f:
pickle.dump(labels, f)
pickle.dump(texts, f)
总共1370223篇文章
类别 it 数量为: 203316.0
类别 auto 数量为: 125100.0
类别 stock 数量为: 44424.0
类别 yule 数量为: 171270.0
类别 sports 数量为: 316819.0
类别 business 数量为: 233553.0
类别 health 数量为: 42240.0
类别 learning 数量为: 27478.0
类别 women 数量为: 54506.0
类别 travel 数量为: 28195.0
类别 house 数量为: 123322.0
四、数据预处理
数据预处理共以下几步:
1)去除停用词,通过停用词表过滤掉一些在分类中不需要用到的字符;
2)中文分词:使用Jieba分词(精确模式);
3)数据测试集,训练集:将原始数据按1:1分为测试集和训练集;
4)提取特征词:计算文档中的词项t与文档类别c的互信息MI,MI度量的是词的存在与否给类别c带来的信息量。将每个类别下互信息排名前1000的单词保留加入特征词集合;
5)保存中间结果文件。
1. Jieba分词以及去停用词
#读取停用词表
def get_stopwords():
#加载停用词表
stopword_set = set()
with open("./stop_words_ch.txt", 'r', encoding="utf-8") as stopwords:
for stopword in stopwords:
stopword_set.add(stopword.strip("
"))
return stopword_set
for i in range(len(texts)):
line = texts[i]
result_content = "" #单行分词结果
stopwords = get_stopwords()
words = jieba.cut(line, cut_all=False)
for word in words:
if word not in stopwords:
result_content += word + " "
texts[i] = result_content
if i % 10000 == 0:
print("已对{}万篇文章分词".format(i/10000))
#保存数据
with open("split_data.pkl", 'wb') as f:
pickle.dump(labels, f)
pickle.dump(texts, f)
2. 计算互信息,抽取特征词,统计数量
#读取上一步保存的数据
with open("./split_data.pkl", "rb") as f:
labels = pickle.load(f)
texts = pickle.load(f)
#划分训练集和测试集,大小各一半
trainText = []
for i in range(len(labels)):
trainText.append(labels[i] + ' ' + texts[i])
#数据随机
random.shuffle(trainText)
num = len(trainText)
testText = trainText[num//2:]
trainText = trainText[:num//2]
print("训练集大小:", len(trainText)) # 685111
print("测试集大小:", len(testText)) # 685112
#文章类别列表
classes = ['it', 'auto', 'stock', 'yule', 'sports', 'business', 'health', 'learning', 'women', 'travel', 'house']
#获取对应类别的索引下标值
def lable2id(label):
for i in range(len(classes)):
if label == classes[i]:
return i
raise Exception('Error label %s' % (label))
#构造和类别数等长的0向量
def doc_dict():
return [0]*len(classes)
#计算互信息,这里log的底取为2
def mutual_info(N, Nij, Ni_, N_j):
return 1.0*Nij/N * math.log(N*1.0*(Nij+1)/(Ni_*N_j)) / math.log(2)
#统计每个词在每个类别出现的次数,和每类的文档数,计算互信息,提取特征词
def count_for_cates(trainText, featureFile):
docCount = [0] * len(classes) #各类别单词计数
wordCount = defaultdict(doc_dict) #每个单词在每个类别中的计数
#扫描文件和计数
for line in trainText:
lable, text = line.strip().split(' ',1)
index = lable2id(lable) #类别索引
words = text.split(' ')
for word in words:
if word in [' ', '', '
']:
continue
wordCount[word][index] += 1
docCount[index] += 1
#计算互信息值
print("计算互信息,提取特征词中,请稍后...")
miDict = defaultdict(doc_dict)
N = sum(docCount)
#遍历每个分类,计算词项k与文档类别i的互信息MI
for k,vs in wordCount.items():
for i in range(len(vs)):
N11 = vs[i] #类别i下单词k的数量
N10 = sum(vs) - N11 #非类别i下单词k的数量
N01 = docCount[i] - N11 #类别i下其他单词数量
N00 = N - N11 - N10 - N01 #其他类别中非k单词数目
mi = mutual_info(N,N11,N10+N11,N01+N11) + mutual_info(N,N10,N10+N11,N00+N10) + mutual_info(N,N01,N01+N11,N01+N00) + mutual_info(N,N00,N00+N10,N00+N01)
miDict[k][i] = mi
fWords = set()
#遍历每个单词
for i in range(len(docCount)):
keyf = lambda x:x[1][i]
sortedDict = sorted(miDict.items(), key=keyf, reverse=True)
# 打印每个类别中排名前20的特征词
t=','.join([w[0] for w in sortedDict[:20]])
print(classes[i], ':', t)
for j in range(1000):
fWords.add(sortedDict[j][0])
out = open(featureFile, 'w', encoding='utf-8')
#输出各个类的文档数目
out.write(str(docCount)+"
")
#输出互信息最高的词作为特征词
for fword in fWords:
out.write(fword+"
")
print("特征词写入完毕!")
out.close()
count_for_cates(trainText, 'featureFile')
计算互信息,提取特征词中,请稍后...
it : G,M,系列,U,P,I,e,华硕,n,英寸,o,尺寸,屏幕,主频,C,硬盘容量,内存容量,芯片,显卡,z
auto : m,座椅,/,调节,发动机,汽车,电动,车型,后排,方向盘,车,系统,车身,元,大灯,变速箱,天窗,悬挂,自动,杂费
stock : 万股,-,.,公司,公告,股,流通,股票走势,股份,经济,U,投资,ㄔ,鹑,嗉,基金,e,伪,M,比赛
yule : 电影,娱乐,导演,.,观众,演员,拍摄,讯,影片,/,主演,G,市场,电视剧,饰演,明星,演出,歌手,-,周笔畅
sports : 比赛,球队,球员,分,体育,赛季,体育讯,主场,联赛,对手,火箭,M,市场,冠军,球迷,公司,-,决赛,e,中国队
business : 证券,资讯,投资者,公司,合作,市场,风险,机构,自担,本频道,转引,基金,据此,e,入市,谨慎,-,判断,观点,立场
health : 患者,治疗,医院,本品,【,】,疾病,主任医师,医生,药品,处方,病人,看病,服用,症状,票下夜,感染,药物,剂量,大夫
learning : 考生,学生,高考,专业,招生,教育,学校,录取,考试,类,志愿,大学,高校,第二批,老师,家长,孩子,经济学,笱,院校
women : 女人,男人,肌肤,.,皮肤,a,时尚,减肥,女性,徐勇,搭配,-,市场,比赛,头发,傅羿,公司,美容,肤质,护肤
travel : 旅游,游客,酒店,旅行社,旅客,景区,航空,航班,游,航空公司,机场,线路,民航,飞机,.,东航,景点,G,出游,李妍
house : O,恪,小区,编号,煌,面积,散布,/,鳌,建筑面积,装修,民族,J,卫,乔与,行期,ゲ,厅,层,〕
特征词写入完毕!
五、模型训练
训练朴素贝叶斯模型,计算每个类中特征词的出现次数,也即类别i下单词k的出现概率,并使用拉普拉斯平滑(加一平滑)。得到模型后对测试数据进行分类。
#从特征文件导入特征词
def load_feature_words(featureFile):
f = open(featureFile, encoding='utf-8')
#各个类的文档数目
docCounts = eval(f.readline())
features = set()
#读取特征词
for line in f:
features.add(line.strip())
f.close()
return docCounts, features
# 训练贝叶斯模型,实际上计算每个类中特征词的出现次数
def train_bayes(featureFile, textFile, modelFile):
print("使用朴素贝叶斯训练中...")
start = datetime.datetime.now()
docCounts, features = load_feature_words(featureFile) #读取词频统计和特征词
wordCount = defaultdict(doc_dict)
#每类文档特征词出现的次数
tCount = [0]*len(docCounts)
#遍历每个文档
for line in textFile:
lable, text = line.strip().split(' ',1)
index = lable2id(lable)
words = text.strip().split(' ')
for word in words:
if word in features and word not in [' ', '', '
']:
tCount[index] += 1 #类别index中单词总数计数
wordCount[word][index] += 1 #类别index中单词word的计数
end = datetime.datetime.now()
print("训练完毕,写入模型...")
print("程序运行时间:"+str((end-start).seconds)+"秒")
#拉普拉斯平滑
outModel = open(modelFile, 'w', encoding='utf-8')
#遍历每个单词
for k,v in wordCount.items():
#遍历每个类别i,计算该类别下单词的出现概率(频率)
scores = [(v[i]+1) * 1.0 / (tCount[i]+len(wordCount)) for i in range(len(v))]
outModel.write(k+" "+str(scores)+"
") #保存模型,记录类别i下单词k的出现概率(频率)
outModel.close()
train_bayes('./featureFile', trainText, './modelFile')
使用朴素贝叶斯训练中...
训练完毕,写入模型...
程序运行时间:45秒
六、预测分类
#从模型文件中导入计算好的贝叶斯模型
def load_model(modelFile):
print("加载模型中...")
f = open(modelFile, encoding='utf-8')
scores = {}
for line in f:
word,counts = line.strip().rsplit(' ',1)
scores[word] = eval(counts)
f.close()
return scores
#预测文档分类,标准输入每一行为一个文档
def predict(featureFile, modelFile, testText):
docCounts, features = load_feature_words(featureFile) #读取词频统计和特征词
docScores = [math.log(count * 1.0 /sum(docCounts)) for count in docCounts] #每个类别出现的概率
scores = load_model(modelFile) #加载模型,每个单词在类别中出现的概率
indexList = []
pIndexList = []
start = datetime.datetime.now()
print("正在使用测试数据验证模型效果...")
for line in testText:
lable, text = line.strip().split(' ', 1)
index = lable2id(lable)
words = text.split(' ')
preValues = list(docScores)
for word in words:
if word in features and word not in [' ', '', '
']:
for i in range(len(preValues)):
#利用贝叶斯公式计算对数概率,后半部分为每个类别中单词word的出现概率
preValues[i] += math.log(scores[word][i])
m = max(preValues) #取出最大值
pIndex = preValues.index(m) #取出最大值类别的索引
indexList.append(index)
pIndexList.append(pIndex)
end = datetime.datetime.now()
print("程序运行时间:"+str((end-start).seconds)+"秒")
return indexList, pIndexList
indexList, pIndexList = predict('./featureFile', './modelFile', testText)
加载模型中...
正在使用测试数据验证模型效果...
程序运行时间:287秒
七、结果评估
对分类得到结果打印混淆矩阵,并计算各类的精确率,召回率,F1值。
精确率p= TP/(TP+FP), 召回率r= TP/(TP+FN), F1分数=2pr/(p+r)
#打印混淆矩阵
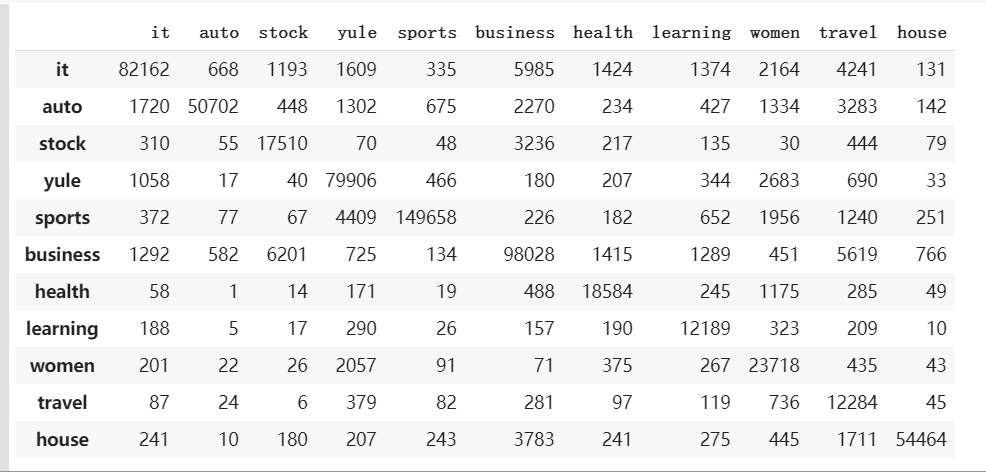
C=confusion_matrix(indexList, pIndexList)
pd.DataFrame(C, index=classes, columns=classes)
#计算各类的精确率,召回率,F1值
p = precision_score(indexList, pIndexList, average=None)
r = recall_score(indexList, pIndexList, average=None)
f1 = f1_score(indexList, pIndexList, average=None)
p_max,r_max,p_min,r_min = 0,0,1,1
for i in range(len(classes)):
print("类别{:8}".format(classes[i]), end=" ")
print("精确率为:{}, 召回率为:{}, F1值为:{}".format(p[i], r[i], f1[i]))
if (p[i] > p_max): p_max = p[i]
if (r[i] > r_max): r_max = r[i]
if (p[i] < p_min): p_min = p[i]
if (r[i] < r_min): r_min = r[i]
#计算总体的精确率,召回率,F1值
pa = precision_score(indexList, pIndexList, average="micro")
ra = recall_score(indexList, pIndexList, average="micro")
f1a = f1_score(indexList, pIndexList, average="micro")
print("总体{:8}".format("====>"), end=" ")
print("精确率为:{}, 召回率为:{}, F1值为:{}".format(pa, ra, f1a))
print("最大{:8}".format("====>"), end=" ")
print("精确率为:{}, 召回率为:{}".format(p_max, r_max))
print("最小{:8}".format("====>"), end=" ")
print("精确率为:{}, 召回率为:{}".format(p_min, r_min))
类别it 精确率为:0.9369704295863791, 召回率为:0.8111881207669371, F1值为:0.8695541738325174
类别auto 精确率为:0.9719916415850315, 召回率为:0.8107520347954011, F1值为:0.8840802092414995
类别stock 精确率为:0.6812699400824839, 召回率为:0.7910906298003072, F1值为:0.732084622460072
类别yule 精确率为:0.876883401920439, 召回率为:0.9332196580398019, F1值为:0.9041748468166722
类别sports 精确率为:0.9860387278704942, 召回率为:0.9407128040731662, F1值为:0.9628426304496779
类别business 精确率为:0.8546096508434681, 召回率为:0.8414276149765669, F1值为:0.8479674058311384
类别health 精确率为:0.8022101355434689, 召回率为:0.8812176964294182, F1值为:0.8398599028358378
类别learning 精确率为:0.703915453915454, 召回率为:0.895986474566304, F1值为:0.7884217335058215
类别women 精确率为:0.677366842781665, 召回率为:0.8686003076246979, F1值为:0.7611559506426405
类别travel 精确率为:0.4035347064813902, 召回率为:0.8687411598302688, F1值为:0.5510867858504745
类别house 精确率为:0.9723457054612322, 召回率为:0.881294498381877, F1值为:0.9245838744450952
总体> 精确率为:0.8746088230829412, 召回率为:0.8746088230829412, F1值为:0.8746088230829411
最大> 精确率为:0.9860387278704942, 召回率为:0.9407128040731662
最小====> 精确率为:0.4035347064813902, 召回率为:0.7910906298003072