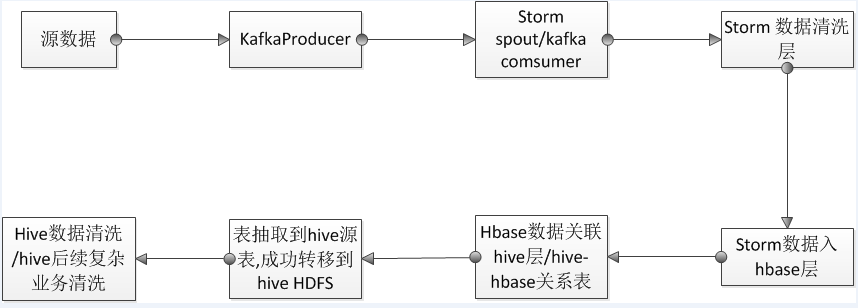
今年做过两个公司需求都遇到了实时流入hive的需求,storm入hive有几种可行性方案。
1.storm直接写入hive,storm下面有个stormhive的工具包,可以进行数据写入hive。但是本人研究半天感觉并不是很好用,并且利用工具类也会在开发上灵活性被限制。
2.storm直接写入hdfs,利用hive映射到hdfs数据块上,此种方案可以分为利用storm hdfs工具类,但是用了一段时间发现此工具类也是限制性挺大,比如数据残留,数据轮转模式只有时间和大小,数据压缩格式等限制。想改良这些只能自己去改良源码,非常麻烦。当然也可以直接自己写hdfs的工具类,工作量也是异常庞大,也见过类似项目,需要一直开启文件读取流,记录文件状态,开发难度比较高。而且很容易造成数据延迟,因为storm写入hdfs并不是特别快。只能开启高并发去解决此问题。会占据大量的节点端口。
3.最后公司采用一种新的方案是,根据ETL分区,建立不同的hbase表,而storm写入hbase是比较简单的而且速度上可以收集批次进行写入,速度上会高速很多。然后每次hbase表完成后再建立hive-hbase表到hive中,如果涉及复查的查询,需要把这种表进行select * 到一个纯hive的表中进行操作。今天测试了30G 3E的数据量抽取大概需要半小时。想缩短时间可以利用spark和MR进行操作。因为抽取过程会产生大量的0KB文件在HDFS下。所以猜测还是MR数据倾斜造成。自己写MRspark抽取应该会速度上快很多。