GIL锁
-
GIL锁
-
定义:全局解释锁,就是一把互斥锁,将并发变成串行,同一时刻只能有一个线程使用解释器资源,牺牲效率,保证解释器的数据安全。
-
py文件在内存中的执行过程:
- 当执行py文件时,会在内存中开启一个进程
- 进程中不光包括py文件还有python解释器,py文件中的线程会将代码交给解释器,
- 解释器将python代码转化为C语言能识别的字节码,然后再交给解释器中的虚拟机将字节码转化为二进制码最后交给CPU执行
如下图:
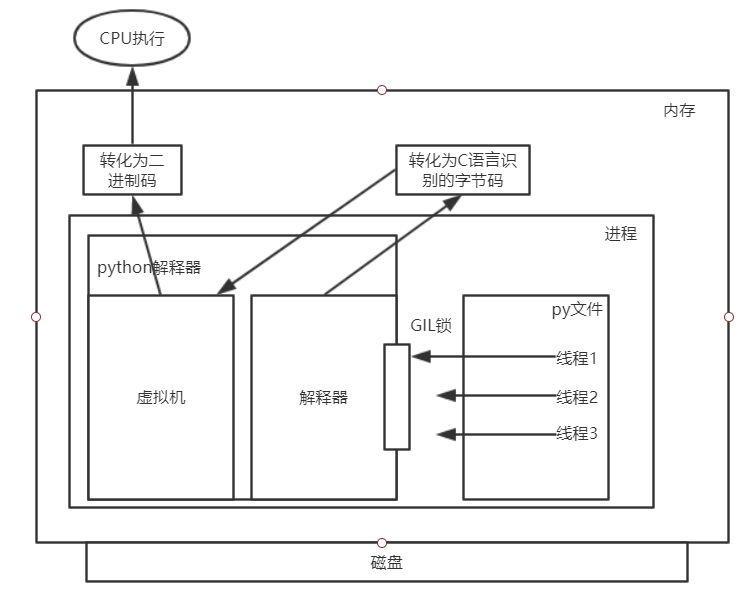
当线程1先拿到GIL锁时线程2、线程3就只能等待,当线程1在CPU执行遇到阻塞或执行一段时间后,线程1会被挂起,同时GIL锁会被释放,此时线程2或线程3就会拿到锁进入解释器,同样,当在CPU执行遇到阻塞或执行一段时间后被挂起,同时GIL锁会被释放,此时最后一个线程就会进入解释器。
从上面可以看出,当遇到单个进程中含有多个线程时,由于GIL锁的存在,Cpython并不能利用多核进行并行处理,但可以在单核实现并发。
但多进程的多线程是可以利用多核的。
-
作用:1.保证解释器里面的数据的安全;2.强行加锁,减轻开发负担
-
问题:单进程的多线程不能利用多核
-
如何判断什么情况使用多线程并发与多进程并发
对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用
当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以应该相对的去看一个程序到底是计算密集型还是I/O密集型,如下:
#分析: 我们有四个任务需要处理,处理方式肯定是要达到并发的效果,解决方案可以是: 方案一:开启四个进程 方案二:一个进程下,开启四个线程 #单核情况下,分析结果: 如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜 如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜 #多核情况下,分析结果: 如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行,可以利用多核,方案一胜 如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜 #结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。 总结:多核前提下,如果任务IO密集型,使用多线程并发;如果任务计算密集型,使用多进程并发。
-
-
验证Cpython的并发效率
-
任务属于计算密集型
from multiprocessing import Process from threading import Thread import os,time def work(): res=0 for i in range(100000000): res*=i if __name__ == '__main__': l=[] print(os.cpu_count()) #本机为8核 start=time.time() for i in range(8): p=Process(target=work) #耗时7s多 # p=Thread(target=work) #耗时15s多 l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))可以看出当任务是计算密集型时,多进程并发效率高于多线程并发
-
任务属于IO密集型
from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) print('===>') if __name__ == '__main__': l=[] print(os.cpu_count()) #本机为4核 start=time.time() for i in range(40): # p=Process(target=work) #耗时5s多,大部分时间耗费在创建进程上 p=Thread(target=work) #耗时2s多 l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))可以看出当任务是IO密集型时,多线程并发效率高于多进程并发。
-
-
GIL锁与互斥锁的关系
- GIL锁保护的是解释器的数据安全;互斥锁保护的是文件中数据的安全。
- GIL锁自动上锁,文件中的互斥锁Lock需要手动上锁和解锁。
线程全部是计算密集型:当程序执行,开启100个线程时,第一个线程先要拿到GIL锁,然后拿到lock锁,释放lock锁,最后释放GIL锁。
线称全部是IO密集型:当程序执行,开启100个线程时,第一个线程先要拿到GIL锁,然后拿到lock锁,当遇到IO,CPU切走,同时GIL锁释放,第二个进程拿到GIL锁进入,由于Lock锁还未释放,便会阻塞挂起,同理,第三个....
总结:自己加互斥锁,一定要加在处理共享数据的地方,加的范围不要扩大。
-
进程池与线程池
进程池:放置进程的一个容器。
线程池:放置线程的一个容器。
例,运用多线程完成socket通信:
import socket from threading import Thread def communication(conn): while 1: try: from_client_data = conn.recv(1024) # 阻塞 print(from_client_data.decode('utf-8')) to_client_data = input('>>>').strip() conn.send(to_client_data.encode('utf-8')) except Exception: break conn.close() def customer_service(): server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen() while 1: conn,addr = server.accept() # 阻塞 print(f'{addr}客户:') t = Thread(target=communication,args=(conn,)) t.start() server.close() if __name__ == '__main__': customer_service()虽然使用多线程实现了与多个客户端的通信,但实际上不可以无限开线程,因此应该对线程(或进程)做数量限制,在计算机能满足的情况下开启更多的线程(或进程)。此时就要用到线程池(或进程池)。如下:
import socket from concurrent.futures import ThreadPoolExecutor def communication(conn): while 1: try: from_client_data = conn.recv(1024) # 阻塞 print(from_client_data.decode('utf-8')) to_client_data = input('>>>').strip() conn.send(to_client_data.encode('utf-8')) except Exception: break conn.close() def customer_service(t): server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen() while 1: conn,addr = server.accept() # 阻塞 print(f'{addr}客户:') t.submit(communication,conn) server.close() if __name__ == '__main__': t = ThreadPoolExecutor(2) customer_service(t)线程池与信号量有什么不同?
线程池用来控制实际工作的线程数量,通过线程复用的方式来减小内存开销。线程池可同时工作的线程数量是一定的,超过该数量的线程需进入线程队列等待,直到有可用的工作线程来执行任务。
使用Seamphore,你创建了多少线程,实际就会有多少线程进行执行,只是可同时执行的线程数量会受到限制。但使用线程池,你创建的线程只是作为任务提交给线程池执行,实际工作的线程由线程池创建,并且实际工作的线程数量由线程池自己管理。