1.4唯一索引 ①当表的某列被指定为unique约束时,这列就是一个唯一索引 create table ddd(id int primary key auto_increment , name varchar(32) unique); 这时, name 列就是一个唯一索引. unique字段可以为NULL,并可以有多NULL(insert values (1,null) ), 但是不能是’’,但是如果是具体内容,则不能重复. 主键字段,不能为NULL,也不能重复. ②在创建表后,再去创建唯一索引 create table eee(id int primary key auto_increment, name varchar(32)); create unique index 索引名 on 表名 (列表..); 1.查看索引 desc 表名 【该方法的缺点是: 不能够显示索引名.】 show index(es) from 表名 show keys from 表名 2.删除 alter table 表名 drop index 索引名; 如果删除主键索引。 alter table 表名 drop primary key (只有一个不需要指定索引名) [这里有一个小问题] 3.修改 先删除,再重新创建. 建立索引的注意事项(索引是在where里面使用的): 索引的代价: 1.索引文件,占用磁盘空间 2.对查询变快,对增删改变慢(增删改之后要重新建索引文件,增删改没有查询多9:1,) 3.在哪些列上适合添加索引? 总结: 满足以下条件的字段,才应该创建索引. a: 肯定在where条经常使用 b: 该字段的内容不是唯一的几个值(sex,因为二叉树太矮了) c: 字段内容不是频繁update(频繁重构索引).d:不会出现在WHERE子句中字段不该创建索引 使用索引的注意事项: 把dept表中,我增加几个部门: alter table dept add index my_ind (dname,loc); // dname 左边的列,loc就是右边的列 说明,如果我们的表中有复合索引(索引作用在多列上), 此时我们注意: 1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。 explain select * from dept where loc='aaa'G 就不会使用到索引 2,对于使用like的模糊查询,查询如果是‘%aaa’不会使用到索引,‘aaa%’会使用到索引。 比如: explain select * from dept where dname like '%aaa'G:(全表查询) 不能使用索引,即,在like查询时,关键的 ‘关键字’ , 最前面,不能使用 % 或者 _这样的字符., 如果一定要前面有变化的值,则考虑使用 全文索引->sphinx. 3,如果条件中有or,即使其中有条件带索引也不会使用索引。换言之,就是要求使用的所有字段都必须建立索引, 才能够使用到索引 select * from dept where dname=’xxx’ or loc=’xx’ or deptno=45 4,如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不会使用到索引。(添加时,字符串必须’’), 也就是,如果列是字符串类型,就一定要用 ‘’ 把他包括起来. 5,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。(用explain查看是否使用了索引) 如何查看索引使用的情况: mysql> show status like 'Handler_read%'; +-----------------------+---------+ | Variable_name | Value | +-----------------------+---------+ | Handler_read_first | 0 | | Handler_read_key | 0 | | Handler_read_last | 0 | | Handler_read_next | 0 | | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 4000001 | +-----------------------+---------+ 大家可以注意: handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。 handler_read_rnd_next:这个值越高,说明查询低效。
大批量插入数据(MySql管理员) 了解 对于MyISAM: alter table table_name disable keys; loading data//insert语句; alter table table_name enable keys; 对于Innodb: 1,将要导入的数据按照主键排序 2,set unique_checks=0,关闭唯一性校验。 3,set autocommit=0,关闭自动提交。
sql语句的小技巧: 在使用group by 分组查询是,默认分组后,还会排序,可能会降低速度.
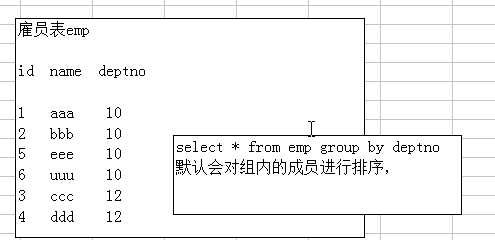
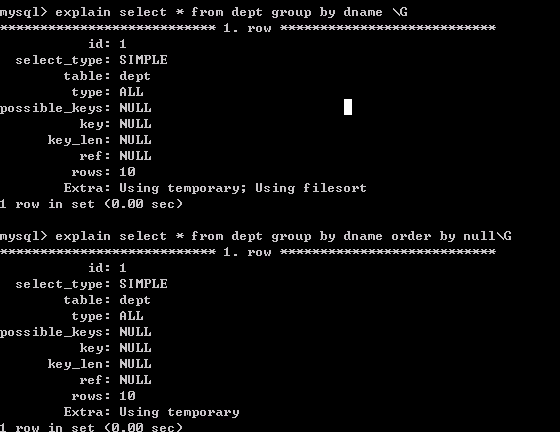
比如: Using filesort是对文件排序。在group by 后面增加 order by null 就可以防止排序.
1.有些情况下,可以使用连接来替代子查询。因为使用join,MySQL不需要在内存中创建临时表。 select * from dept, emp where dept.deptno=emp.deptno; [简单处理方式] select * from dept left join emp on dept.deptno=emp.deptno; [左外连接,更ok!] 如何选择mysql的存储引擎: 在开发中,我们经常使用的存储引擎 myisam / innodb/ memory myisam 存储: 如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎. ,比如 bbs 中的 发帖表,回复表. INNODB 存储: 对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表. 问 MyISAM 和 INNODB的区别 1. 事务安全,MyISAM 不支持事务。INNODB支持事务。 2. 查询和添加速度,MyISAM 快,添加的时候就是添加到最后。INNODB会排序。 3. 支持全文索引,MyISAM 支持,INNODB不支持。 4. 锁机制,MyISAM 是表锁要快。INNODB是行锁要慢。 5. 外键 MyISAM 不支持外键(hibernate映射会不成功), INNODB支持外键. (在PHP开发中,通常不设置外键,通常是在程序中保证数据的一致) Memory 存储,比如我们数据变化频繁,不需要入库(数据在内存中,重启mysql数据全部丢失),同时又频繁的查询和修改,我们考虑使用memory, 速度极快.

(有的表的存储引擎是myisam、innodb、memory,不一定所有表的存储引擎都一样) 如果你的数据库的存储引擎是myisam,请一定记住要定时进行碎片整理(删除数据后文件并没有减小) 举例说明: create table test100(id int unsigned ,name varchar(32))engine=myisam; insert into test100 values(1,’aaaaa’); insert into test100 values(2,’bbbb’); insert into test100 values(3,’ccccc’); Delete from test100 where id = 3; //文件不会减小 我们应该定义对myisam进行整理,文件就减小了。 mysql> optimize table test100; +--------------+----------+----------+----------+ | Table | Op | Msg_type | Msg_text | +--------------+----------+----------+----------+ | temp.test100 | optimize | status | OK | +--------------+----------+----------+----------+ //通过代码进行优化 mysql_query(“optimize tables $表名”);