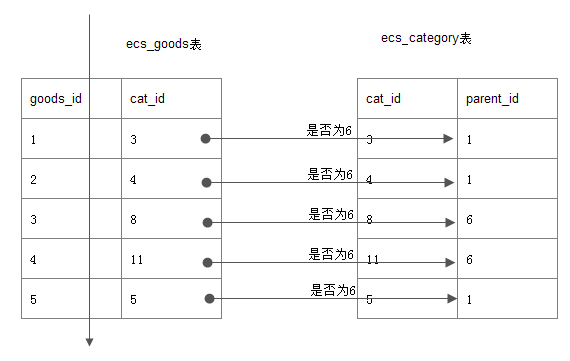
in型子查询引出的陷阱:(扫更少的行,不要临时表,不要文件排序就快) 题: 在ecshop商城表中,查询6号栏目的商品, (注,6号是一个大栏目) 最直观的: mysql> select goods_id,cat_id,goods_name from goods where cat_id in (select cat_id from category where parent_id=6); 误区: 给我们的感觉是, 先查到内层的6号栏目的子栏目,如7,8,9,11 然后外层, cat_id in (7,8,9,11) 事实: 如下图, goods表全扫描, 并逐行与category表对照,看parent_id=6是否成立
原因: mysql的查询优化器,针对In型做优化,被改成了exists的执行效果. 当goods表越大时, 查询速度越慢. 改进: 用连接查询来代替子查询 explain select goods_id,g.cat_id,g.goods_name from goods as g inner join (select cat_id from category where parent_id=6) as t using(cat_id) G 内层 select cat_id from ecs_category where parent_id=6 ; 用到Parent_id索引, 返回4行 +--------+ | cat_id | +--------+ | 7 | | 8 | | 9 | | 11 | +--------+ 形成结果,设为t *************************** 3. row *************************** id: 2 select_type: DERIVED table: ecs_category type: ref possible_keys: parent_id key: parent_id key_len: 2 ref: rows: 4 Extra: 3 rows in set (0.00 sec) 第2次查询, t和 goods 通过 cat_id 相连, 因为cat_id在 goods表中有索引, 所以相当于用7,8,911,快速匹配上 goods的行. *************************** 2. row *************************** id: 1 select_type: PRIMARY table: g type: ref possible_keys: cat_id key: cat_id key_len: 2 ref: t.cat_id rows: 6 Extra: 第1次查询 : 是把上面2次的中间结果,直接取回. *************************** 1. row *************************** id: 1 select_type: PRIMARY table: <derived2> type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 4 Extra: exists子查询: 题: 查询有商品的栏目. 按上面的理解,我们用join来操作,如下: mysql> select c.cat_id,cat_name from ecs_category as c inner join goods as g on c.cat_id=g.cat_id group by cat_name; (见36) 优化1: 在group时, 用带有索引的列来group, 速度会稍快一些,另外, 用int型 比 char型 分组,也要快一些.(见37) 优化2: 在group时, 我们假设只取了A表的内容,group by 的列,尽量用A表的列, 会比B表的列要快.(见38) 优化3: 从语义上去优化 select cat_id,cat_name from ecs_category where exists(select *from goods where goods.cat_id=ecs_category.cat_id) (见40) | 36 | 0.00039075 | select c.cat_id,cat_name from ecs_category as c inner join goods as g on c.cat_id=g.cat_id group by cat_name | | 37 | 0.00038675 | select c.cat_id,cat_name from ecs_category as c inner join goods as g on c.cat_id=g.cat_id group by cat_id | | 38 | 0.00035650 | select c.cat_id,cat_name from ecs_category as c inner join goods as g on c.cat_id=g.cat_id group by c.cat_id | | 40 | 0.00033500 | select cat_id,cat_name from ecs_category where exists (select * from goods where goods.cat_id=ecs_category.cat_id) | from 型子查询: 注意::内层from语句查到的临时表, 是没有索引的.因为是一个临时形成的结果。 所以: from的返回内容要尽量少.