前言
在本篇文章中将介绍奖励与策略结构相关的知识,这一部分是强化学习的极重要一部分,因此会有较长篇幅介绍。
奖励
奖励是代理不断完善自己,使自己能够自主实现目标的直接经验来源。代理通过接受来自环境奖励判断自己行为地好坏,从而通过更大可能的选择收益高的行为使自己趋于目标状态。好比老师为你的行为打的分数。
策略
前文提到,策略是代理状态空间到动作空间的映射,即策略是一个函数,输入是代理所处的状态,输出是代理的行为,可以看出策略的作用是指示代理在某一个状态做出一个动作,即为代理的行动指示手册,而最优策略则为代理在任意状态,该手册(策略)均可以给出最优的动作使代理获得最大的长期奖励(价值),最初代理是一个白痴,而学习就是通过长期训练使得策略收敛于最佳策略,而在学习的过程中会产生这样一个问题,若代理在一个状态执行动作获得较高的奖励,是否以后在该状态都会执行该行为?例如代理的状态空间为S = {s1,s2,s3,s4},动作空间A = {a1,a2,a3,a4},也意味着代理在四个状态均有四种动作可以执行,在初始时代理是一个白痴,不知道在每一个状态执行每一个动作分别会获得怎样的奖励,因此会随机选择一个动作执行,也称之为代理的探索,现在假定代理在s1,执行动作a1后获得+1的奖励,于是代理记住了在s1执行a1会获得好的奖励,因此代理在s1状态都会执行动作a1,这样就产生了一个问题,代理在s1时,执行a2、a3、a4获得的奖励是未知的,也许会存在奖励更大的情况,这样子显然不是一个最佳的学习方法,为了解决这个问题,引入了探索与利用的概念。
探索与利用
探索指的是代理在该状态随机选择一个动作执行,这个动作不一定是获得最大奖励的动作,是完全随机的,用于探索环境中未知的因素;利用指代理总是选取当前状态下获益最大的动作执行。接下来我们分析一下两种极端情况,代理纯粹探索与纯粹利用。
纯探索
纯探索的意思是代理在任意状态下动作的选取都是随机的,不会受到任何因素的干扰,这样导致的后果是代理过度学习,一直在探索、一直在学习,不会利用自己已经学习到的知识,哪怕代理已经直到在某个状态执行某个状态对自己最有利,但是它任然会随机选择行为执行,可见这样的训练毫无价值。
纯利用
纯利用是指代理在每一个状态都选取最有利的动作执行,这样产生的后果便是代理对环境的探索不充分,环境的很多地方都得不到探索,会导致得到的策略并不是最优策略。可以看出纯探索和纯利用都是不利的,最佳的方法是应该在探索与利用间寻求平衡,时代里能够探索完整的环境,又能在一定时间收敛到最佳策略。
利用与探索的平衡
从上文可以看出,纯探索和纯利用都要有极大的缺点,并不是我们想要的训练方式,如果能在探索与利用之间找到平衡,便可较快速的训练出聪明的代理。于是在这里引入一个变量ε,它是一个概率,被称之为贪婪系数,表明在当前状态有ε的概率去探索环境(随机选择动作),(1-ε)的概率利用之前学到的经验(即选择最有利的动作),通常ε很小,类似于0.1之类的值甚至更小,这样既能保证代理有几率探索环境,也能使得代理利用之前学习到的知识。为了使得策略更快的收敛于最佳策略,ε会呈现某种形式衰减,对衰减方式感兴趣的小伙伴儿可以查询资料,这里不做过多阐述。
奖励与价值
强化学习中,需要区别奖励与价值两个概念,前文提到,代理更有可能选择长期奖励较高的行为执行,这里的长期奖励便是价值。即:
奖励:代理在当前状态执行某动作获得的即时奖励
价值:代理从某一状态向后执行一些列动作获得的收益之和
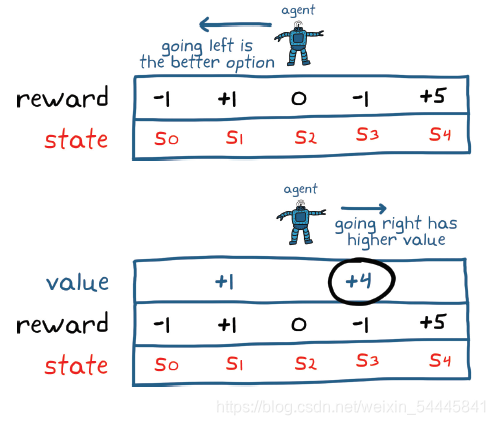
举个简单例子,如下图所示:代理在状态s2,仅仅可以左右移动。考虑代理收取两步内的奖励,如果是一个鼠目寸光的代理,那么它仅仅会注重眼前的利益,于是他会向左移动得到1的奖励到达s0,再向右移动得到0的奖励回到s0,这样两步的总奖励是1;而对于一个有长远目光的代理,他注重当前和以后的回报,于从s0向右移动到达s1,获得-1奖励,再次向右移动到达s4获得+5奖励,两步总奖励+4,比前者更多。而我们当然更喜欢一个具有长远目光、重视未来收益的代理,那么是不是代理越重视未来收益越好呢?显然也不是,好比由于货币贬值,现在你兜里的100元比你一年后兜里的102元更值钱,因此未来的收益变得不在可靠,于是为了降低未来奖励带来的风险,需要对未来的奖励打折扣,离现在越远,折扣越大,引入了折扣因子γ(0<=γ<=1),则总奖励为: m = i-1
$$
R = sum_{k=1}^T γ^ m*r_i
$$
可以看出离现在越远,对其奖励越不重视,若γ等于0,则是一个鼠目寸光得代理,只重视眼前利益,若γ等于1,则是一个过度重视未来奖励的代理。
策略表达方式
前文提到,策略实际上是一个以状态为输入,以动作为输出的函数,那么他有哪些表达方式呢,这里主要介绍基于表格和神经网络。
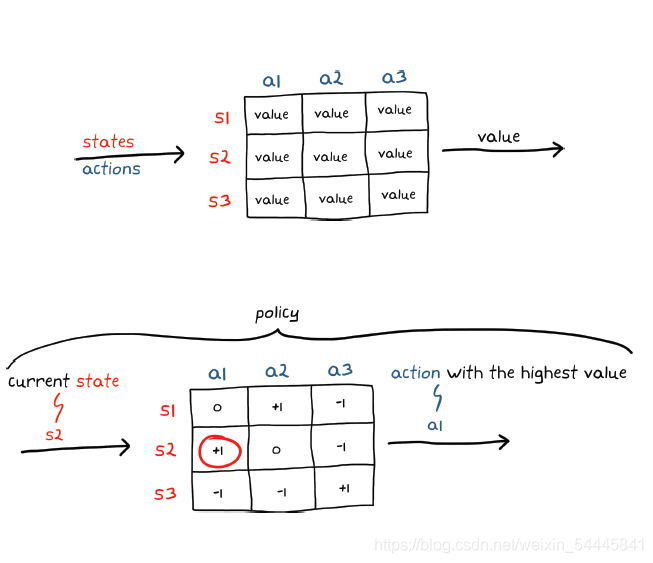
基于表格
如果环境的状态和动作空间离散,且数量少,则可以使用简单表格来表示策略。 表格正是期望的形式:一个数组,其中,输入作为查询地址,输出是表格 中的相应数字。有一种基于表格的函数类型是 Q-table,它将状态和动作 映射到价值。使用 Q-table,策略会在当前状态给定的情况下检查每个可能动作的价值,然后选择具有最高价值的动作。使用 Q-table 训练代理将包括确定表格中每个状态/动作对的正确价值。在表格完全填充正确的值之后,选择将会产生最多长期奖励回报的动作就相当直接
基于神经网络
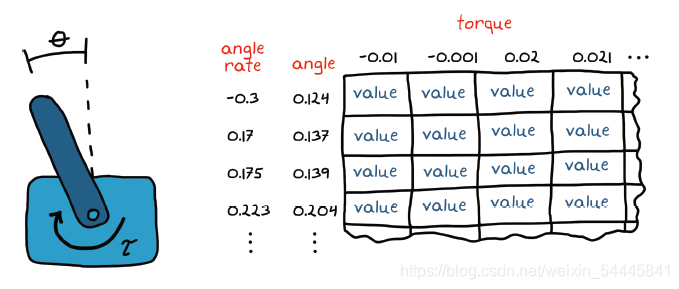
当状态/动作对的数量变大或变为无穷大时,在表格中表示策略参数就不可行了。这就是所谓的维数灾难。为了直观地理解这一点,让我们考虑一个用于控制倒立摆的策略。倒立摆的状态可能是从 -π 到 π 的任何角度和任何角速率。另外,动作空间是从负极限到正极限的任何电机转矩。试图在表格中捕获每个状态和动作的每一种组合是不可能的。
神经网络是一组节点或人工神经元,采用一种能够使其成为通用函数逼近器的方式连接。这意味着,给出节点和连接的正确组合,您可以设置该网络,模仿任何输入与输出关系。尽管函数可能极其复杂,神经网络的通用性质可以确保有某种神经网络可以实现目标。
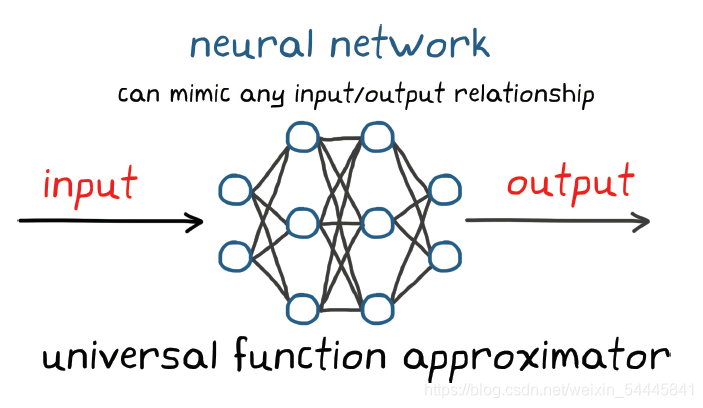
所以,与其尝试寻找适合特定环境的完美非线性函数结构,不如使用神经网络,这样就可以在许多不同环境中使用相同的节点和连接组合。唯一的区别在于参数自身。学习过程将包括系统地调节参数,找到最优输入/输出关系。
左边是输入节点,一个节点对应函数的一个输入,右边是输出节点。中间是称为隐藏层的节点列。此网络有 2 个输入、2 个输出和 2 个隐藏层,每层 3 个节点。对于全连接的网络,存在从每个输入节点到下一层中每个节点的加权连接,然后是从这些节点连接到后面一层,直到输出节点为止。关于神经网络的介绍就到这里,感兴趣的小伙伴可以查阅资料。
总结
本篇文章主要介绍了强化学习关于奖励和策略结构的相关知识,梳理的很简略,但这一部分在强化学习中十分重要,尤其在算法的设计方面,不太理解的小伙伴可以查阅资料继续了解。
导航
五大方面之环境: https://blog.csdn.net/weixin_54445841/article/details/112965944.
入门资料: https://download.csdn.net/download/weixin_54445841/14910862.
Python工程:
https://download.csdn.net/download/weixin_54445841/14910913.