在python的dict中间进行查找某个key操作时,查找所需时间不会随着dict中键值对数量增多而变长,(时间复杂度为O(1))但是list中就会(时间复杂度为O(N)),这是因为list查询实现的方式是循环遍历所有列表,然后查找对应的元素,所以列表中元素越多,查找越费时间,但是同一个dict中的所有key的id在内存中是连续的,并且其数据的存储方式为hash表的形式,原理图如下:
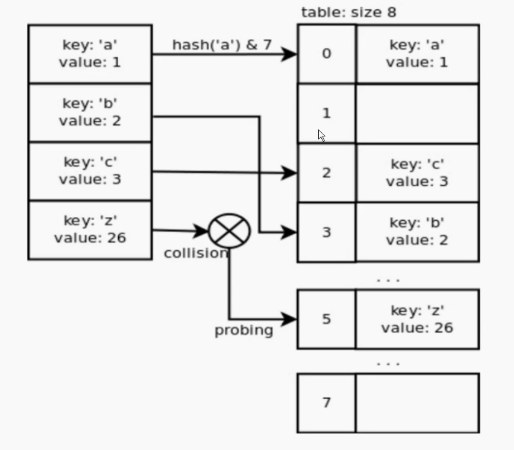
如上左图,在存数dict的时候,首先会根据dict的key进行hash映射到对应的表元,然后再对应的表元中开辟内存,存入数据,当如果存在不同的两个key的hash结果相同的时候,就会使用散列值的另一部分来定位散列表中的另一行。
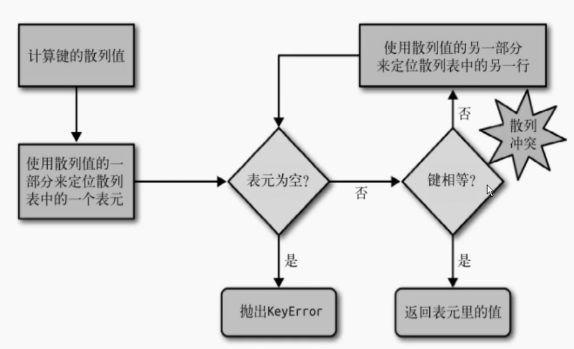
如上右图,在dict中查找指定的key时,会先计算key的散列值,然后使用散列值的一部分来定位表元,如果没有找到相应的表元,则说明dict中不存在对应的key跑出KeyError异常。如果找到表元之后,会判断表元中的key是否和要查找的key相等,相等就返回对应值,如果不相等则使用其对应的散列值的其他部分来定位散列表中的其他行。(这是因为不同的对象通过的散列值有一定的概率相同,这也是为什么在存放dict时开辟内存时候需要有1/3的空地址出来,这样如果有相同的hash值就会有空的地址来存放随数据增加,还会继续开辟新的内存,以确保空内存时刻在1/3左右)
补充:①python中set的值得存储方式也是和dict一样。所以dict的key和set的值都必须是可hash(即不可修改的)的对象。
②dict的花销大,因为会空出进1/3的内存主来,但是查询速度快。