先理解几个问题:
(1)为什么读取文件的时候,需要用户进程通过系统调用内核完成(系统不能自己调用内核)什么是用户态和内核态?为什么要区分内核态和用户态呢?
在 CPU 的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。如果允许所有的程序都可以使用这些指令,那么系统崩溃的概率将大大增加。所以,CPU 将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通应用程序只能使用那些不会造成灾难的指令。
当进程运行在内核空间时就处于内核态,而进程运行在用户空间时则处于用户态。
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令。运行的代码也不受任何的限制,可以自由地访问任何有效地址,也可以直接进行端口的访问。
在用户态下,进程运行在用户地址空间中,被执行的代码要受到 CPU 的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中 I/O 许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问。
对于 Linux 来说,通过区分内核空间和用户空间的设计,隔离了操作系统代码(操作系统的代码要比应用程序的代码健壮很多)与应用程序代码。即便是单个应用程序出现错误也不会影响到操作系统的稳定性,这样其它的程序还可以正常的运行(Linux 可是个多任务系统啊!)。
所以,区分内核空间和用户空间本质上是要提高操作系统的稳定性及可用性。
如何从用户空间进入内核空间?
我们可以通过内核提供的接口来完成这样的任务。比如应用程序要读取磁盘上的一个文件,它可以向内核发起一个 "系统调用" 告诉内核:"我要读取磁盘上的某某文件"。其实就是通过一个特殊的指令让进程从用户态进入到内核态(到了内核空间),在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。此时应用程序已经从系统调用中返回并且拿到了想要的数据,可以开开心心的往下执行了。简单说就是应用程序把高科技的事情(从磁盘读取文件)外包给了系统内核,系统内核做这些事情既专业又高效。
每个处理器在任何指定时间点上的活动概括为下列三者之一:
- 运行于用户空间,执行用户进程。
- 运行于内核空间,处于进程上下文,代表某个特定的进程执行。
- 运行于内核空间,处于中断上下文,与任何进程无关,处理某个特定的中断。
以上三点几乎包括所有的情况,比如当 CPU 空闲时,内核就运行一个空进程,处于进程上下文,但运行在内核空间。
那么什么样的操作只能运行在内核态呢?
- 用户态:只能受限的访问内存,无法访问外围设备。
- 内核态:可以访问内存所有数据
一些对外围设备的访问操作比如硬盘、网卡都只能运行在内核态,此外进程调度、TCP/IP协议栈等也只能工作在内核态。
(2)文件描述符(fd)
文件描述符是一个非负整数,实际上,他是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表,当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。当我们的进程想要对文件进行读写的时候,就会传递这个文件描述符给内核空间,内核就会根据不同类型的IO对相应的数据进行操作返回。 用户进程如果想要从外围设备(这里以socket为例)读取数据,需要首先经过内核,那这里就涉及到和内核的通信问题了。
各个IO模型介绍
(1)阻塞IO

比如说网络io,当我们需要去获取一个网页的数据返回的时候,如果服务器无返回的时候,就会一直阻塞等待数据返回。这样cpu的浪费就很严重。
(2)非阻塞IO
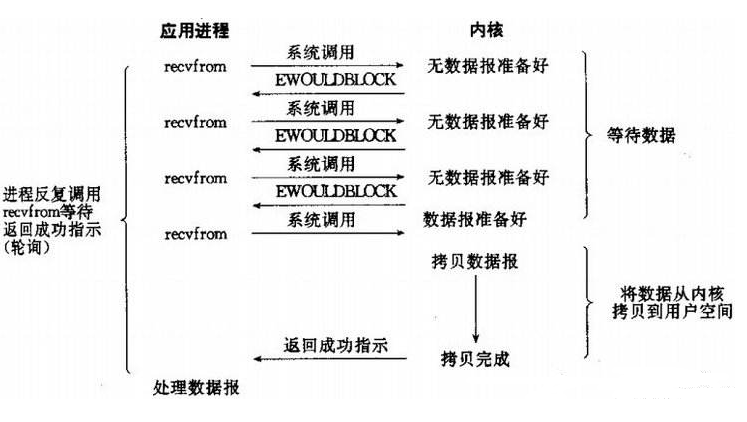
用户进程想要读取数据了,于是就通过执行recvfrom来进行一次系统调用,进入内核态,内核态如果数据没有准备好就直接返回一个没有准备好的标志,我们这边的用户进程也没有闲着,就去干别的事了,(但是后面的执行需要用到数据的话,那么还是要等待数据返回)但是还是会定时轮询系统调用查看数据是否准备好
(3)IO 复用
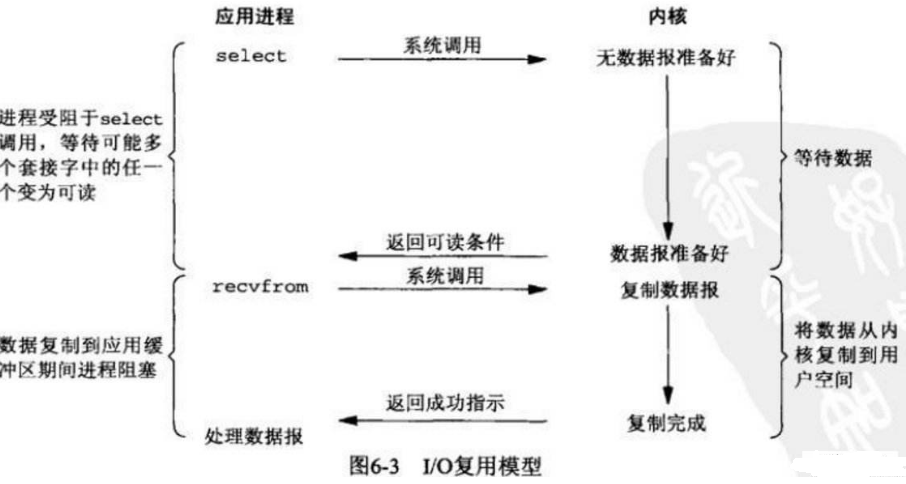
前面的前面两种方式一个进程只能监听一个返回状态,但select可以同时监听多个返回状态,比如同时发起100个socket,一旦有一个数据返回了就去立即处理。所以说效率大大提高了。但是将数据从内核复制到用户控件这个时间还是有浪费。
(4)真正的异步IO
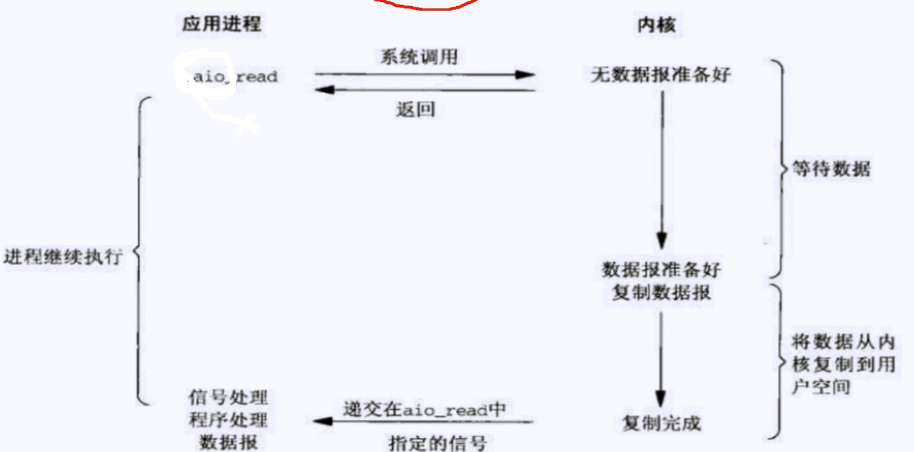
得到数据之后,操作系统会将数据从内核复制到用户空间之后,再给信号处理程序发起数据。少了中间拷贝数据的过程,是操作系统准备好了之后再发给用户进程的。异步io在io复用的基础上没有太大的提升, 但是编码难度复杂,所以如今很多程序的框架还是广泛使用的还是io复用。

select

poll

epoll(linux下支持,windows不支持) 运用红黑树查询,效率很高

分析:epoll不一定就比select好,
- 高并发,但是连接活跃度不高的情况下,epoll优于select(比如浏览网页,用户的连接时间可能不长)
- 并发不高,同时活跃度很高的情况下,select优于epoll (比如游戏,连接上了不会一下子断开又连接)