读与写
pandas是基于NumPy的一种数据分析工具,在数据分析的任务中,我们首先需要对数据进行清洗和编辑等工作,pandas库大大简化了我们的工作量。
•pandas进行数据读取
1 #绝对路径查询 2 import os
1 print(os.path.abspath("."))
/Users/yaozhilin
1 #导入pandas和numpy库 2 import pandas as pd 3 import numpy as np
1 from pandas import Series,DataFrame
读取常用的数据方法
~pd.read_csv 读取csv文件
~pd.read_table 读取txt文件
~pd.read_excel 读取xls文件
其实这三种读取方式都一致,我们以pd.read_excel为例
pd.read_excel(filepath,encoding,sep,header,names,usecols,index_col,skiprows,nrows……)
filepath:文件存储路径,可以用r""进行非转义限定,路径最好是纯英文(文件名也是),不然会经常碰到编码不对的问题,最方便是直接将文件存储在pandas默认的路径下,则直接输入文件名即可
encoding:pandas默认编码是utf-8,如果同样读取默认uft-8的txt或者json格式,则可以忽略这个参数,如果是csv,且数据中有中文时,则要指定encoding=‘gbk’
sep:指定分割符形式,CSV默认逗号分割,可以忽略这个参数,如果是其它分割方式,则要填写
header: 指定第一行是否是列名,通常有三种用法,忽略或header=0(表示数据第一行为列名),header=None(表明数据没有列名),常与names搭配使用
names: 指定列名,通常用一个字符串列表表示,当header=0时,用names可以替换掉第数据中的第一行作为列名,如果header=None,用names可以增加一行作为列名,如果没有header参数时,用names会增加一行作为列名,原数据的第一行仍然保留
usecols:一个字符串列表,可以指定读取的列名
index_col: 一个字符串列表,指定哪几列作为索引
skiprows: 跳过多少行再读取数据,通常是数据不太干净,需要去除掉表头才会用到
nrows: 仅读取多少行,后面的处理也都仅限于读取的这些行
以上参数并不都会用到,仅供参考,下面我们简单的读取一个文件:
1 test=pd.read_excel("/Users/yaozhilin/Downloads/数据.xls",sep="t") 2 test.head(5)#显示前五行
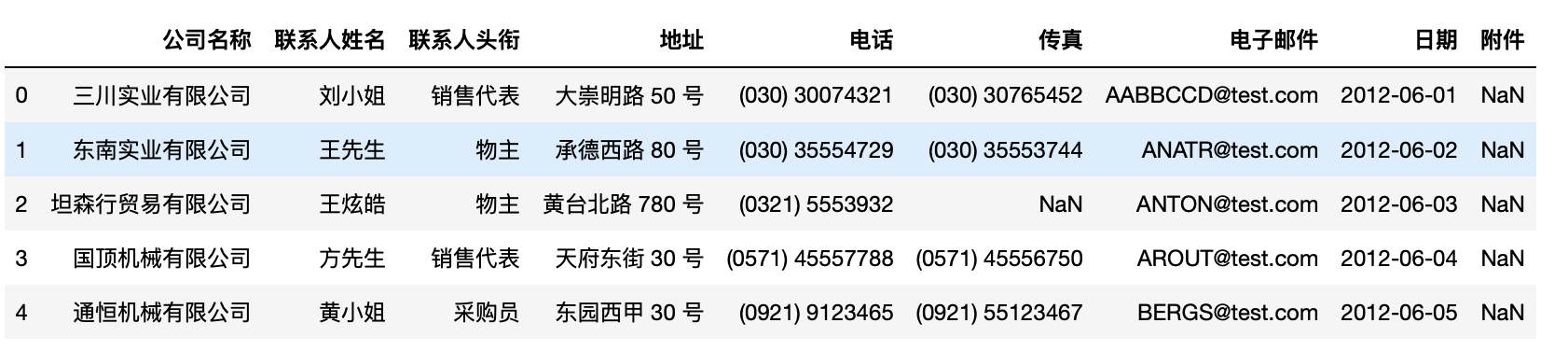
columns重命名rename
1 test.rename(columns={"联系人姓名":"姓名","联系人头衔":"职位"},inplace=True) 2 test.head(5)
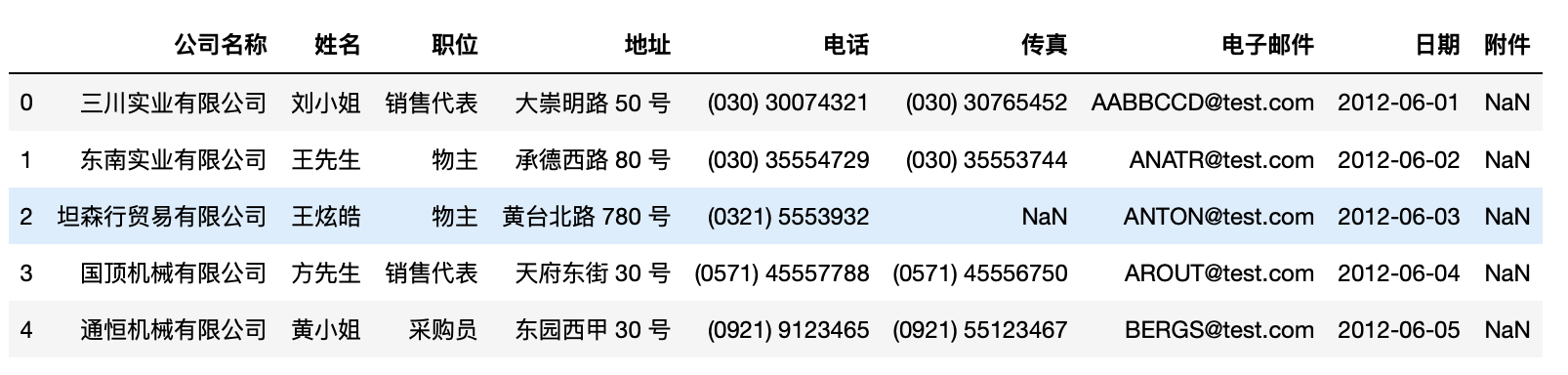
•pandas进行数据写出
写入常用的数据方法
~data.to_csv 写出csv文件
~data.to_table 写出txt文件
~data.to_excel 写出xls文件
data.to_excel (path_or_buf=None, sep=’, ’, columns=None, header=True, index=True, mode=‘w’, encoding=None)
path_or_buf :文件路径
sep :分隔符,默认用","隔开
columns :选择需要的列索引
header :boolean or list of string, default True,是否写进列索引值
index:是否写进行索引
mode:‘w’:重写, ‘a’ 追加
写出一个文件
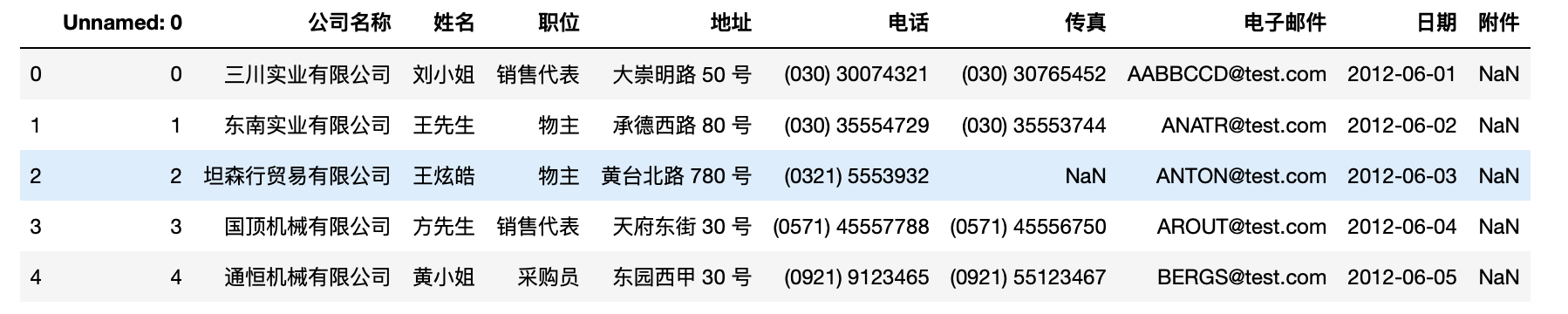
1 test.to_excel("/Users/yaozhilin/Downloads/数据写出.xls", encoding='gbk')
我们尝试的读取一下,看看是否写出成功。
1 pd.read_excel("/Users/yaozhilin/Downloads/数据写出.xls", encoding='gbk',nrows=5)#只读5行
我们在读写文件时常常需要注意encoding="gbk"(中文防止乱码)和分隔符sep=" "。
附:常用的读写参考表
