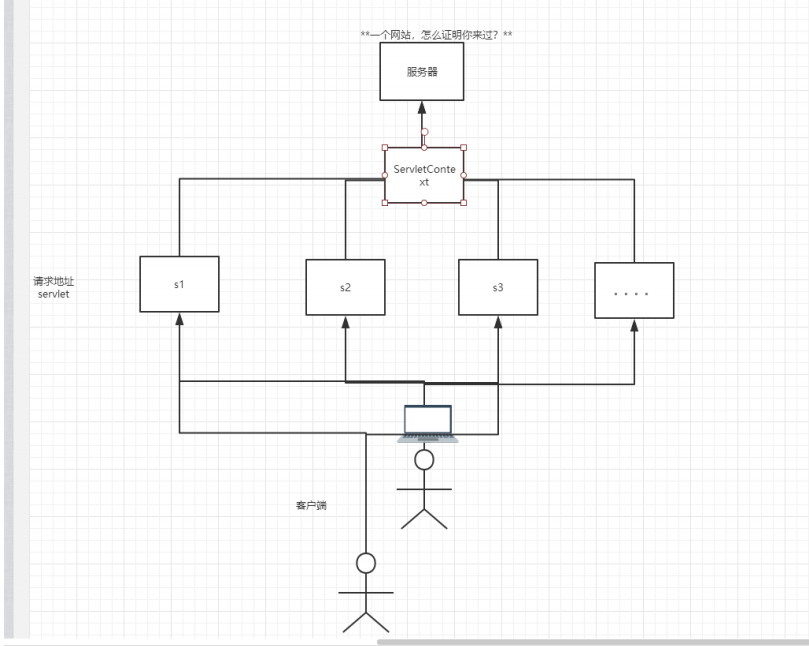
1、保存会话的两种方式
-
cookie
客户端技术(响应,请求)
-
session
服务端技术,可以保存用户的会话信息
常见场景:登录一个网站,关掉时候下次进入可以不用登录
2、Cookie
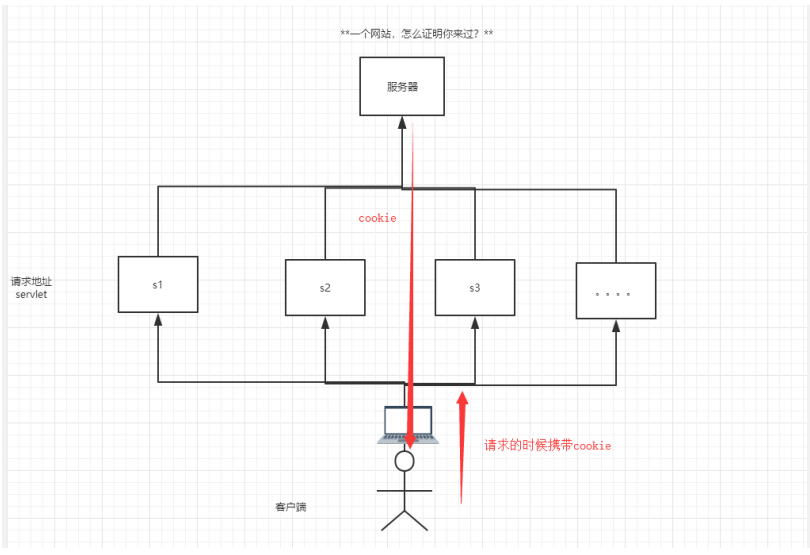
- 从请求中拿到cookie信息
- 服务端响应给客户端cookie
Cookie[] cookies = req.getCookies(); //获得Cookie
cookie.getName(); //获得cookie中的key
cookie.getValue(); //获得cookie中的vlaue
new Cookie("lastLoginTime", System.currentTimeMillis()+""); //新建一个cookie cookie.setMaxAge(24*60*60); //设置cookie的有效期
resp.addCookie(cookie); //响应给客户端一个cookie
cookie:一般会保存在本地用户目录下appdata中
考点:一个网站的cookie是否会有上限
- 一个cookie只能保存一个信息
- 一个web站点可以给浏览器发送多个cookie,最多存放20个
- cookie的大小有限制(4kb)
- 300个cookie是浏览器上限
删除cookie
- 不设置有效期,关闭浏览器,自动失效
- 设置有效时间为0
编码解码
URLEncoder.encode("测试","utf-8");
URLDecoder.decode(cookie.getValue(),"UTF-8")
3、Session

什么是session:
- 服务器会给每一个用户(浏览器)创建一个Session对象;
- 一个Seesion独占一个浏览器,只要浏览器没有关闭,这个Session就存在;
- 用户登录之后,整个网站它都可以访问,例如 保存用户的信息;保存购物车的信息…..
Session和Cookie的区别
- Cookie是把用户的数据写给用户的浏览器(客户端),由浏览器保存
- Session是把用户的数据写到用户独占的Session中,服务器端保存(保存重要的信息,减少服务器资源的浪费)
- Session对象由服务器创建
使用Session: