1.针对经常查询的条件,建立符合索引。
2.根据执行计划对sql进行优化。
看执行计划时,我们的关键不是看哪个操作先执行,哪个操作后执行,而是关键看表之间连接的顺序(如得知哪个为驱动表,这需要从操作的顺序进行判断)、使用了何种类型的关联及具体的存取路径(如判断是否利用了索引)
在从执行计划中判断出哪个表为驱动表后,根据我们的知识判断该表作为驱动表(就像上面判断ABC表那样)是否合适,如果不合适,对SQL语句进行更改,使优化器可以选择正确的驱动表。
3.收集表统计信息
如果查看执行计划发现符合预期,但实际性能不行,可能需要重新收集表统计信息。
Oracle CBO需要系统定期分析统计表/索引。 只有这样CBO才能使用正确的SQL访问路径,提高查询效率。 因此在Instance Level的optimizer_mode = choose ,定期运行ANALYZE 或dbms_stats是非常重要的,尤其是当上次统计后,数据量已发生较大变化之后。 注意:统计操作是很耗资源的动作,要在系统Loading小的时候进行。
oracle数据库的两个优化器:CBO和RBO,
RBO: Rule-Based Optimization 基于规则的优化器
CBO: Cost-Based Optimization 基于代价的优化器
CBO是一种比RBO更加合理、可靠的优化器,它是从ORACLE 8中开始引入,但到ORACLE 9i 中才逐渐成熟,在ORACLE 10g中完全取代RBO
在看懂执行计划之前,先了解oracle的三个交表方式,http://keepwork.iteye.com/blog/1949520
一般来说是指:嵌套循环,hash链接,合并排序连接
1 嵌套循环连接
嵌套循环连接的内部处理的流程:
1) Oracle 优化器根据基于规则RBO或基于成本CBO的原则,选择两个表中的一个作为驱动表,并指定其为外部表。
2) Oracle 优化器再将另外一个表指定为内部表。
3) Oracle从外部表中读取第一行,然后和内部表中的数据逐一进行对比,所有匹配的记录放在结果集中。
4) Oracle读取外部表中的第二行,再和内部表中的数据逐一进行对比,所有匹配的记录添加到结果集中。
5) 重复上述步骤,直到外部表中的所有纪录全部处理完。
6) 最后产生满足要求的结果集。
通过查询SQL语句的执行计划可以看出哪个表是外部表,哪个为内部表。
如 select a.user_name,b.dev_no
from user_info a, dev_info b
where a.user_id = b.user_id;
的执行计划:
SELECT STATEMENT ptimizer=CHOOSE
NESTED LOOPS
TABLE ACCESS (FULL) OF 'USER_INFO' --驱动表,外部表
TABLE ACCESS (FULL) OF 'DEV_INFO' --内部表
使用嵌套循环连接是一种从结果集中提取第一批记录最快速的方法。在驱动行源表(就是正在查找的记录)较小、或者内部行源表已连接的列有惟一的索引或高度可选的非惟一索引时, 嵌套循环连接效果是比较理想的。嵌套循环连接比其他连接方法有优势,它可以快速地从结果集中提取第一批记录,而不用等待整个结果集完全确定下来。这样,在理想情况下,终端用户就可以通过查询屏幕查看第一批记录,而在同时读取其他记录。不管如何定义连接的条件或者模式,任何两行记录源可以使用嵌套循环连接,所以嵌套循环连接是非常灵活的。
然而,如果内部行源表(读取的第二张表)已连接的列上不包含索引,或者索引不是高度可选时, 嵌套循环连接效率是很低的。如果驱动表的记录非常庞大时,其他的连接方法可能更加有效。
排序合并连接(SORT MERGE JOIN)
适用于非等值连接的情况,例如,<, > ,>=,<=
不适用的连接条件有: <> like
假设有查询:select a.name, b.name from table_A a join table_B b on (a.id = b.id)
内部连接过程:
a) 生成 row source 1 需要的数据,按照连接操作关联列(如示例中的a.id)对这些数据进行排序
b) 生成 row source 2 需要的数据,按照与 a) 中对应的连接操作关联列(b.id)对数据进行排序
c) 两边已排序的行放在一起执行合并操作(对两边的数据集进行扫描并判断是否连接)
延伸:
如果示例中的连接操作关联列 a.id,b.id 之前就已经被排过序了的话,连接速度便可大大提高,因为排序是很费时间和资源的操作,尤其对于有大量数据的表。
故可以考虑在 a.id,b.id 上建立索引让其能预先排好序。不过遗憾的是,由于返回的结果集中包括所有字段,所以通常的执行计划中,即使连接列存在索引,也不会进入到执行计划中,除非进行一些特定列处理(如仅仅只查询有索引的列等)。
排序-合并连接的表无驱动顺序,谁在前面都可以;
下面我们分步骤介绍Hash Join算法步骤:
i. Hash Join连接对象依然是两个数据表,首先选择出其中一个“小表”。这里的小表,就是参与连接操作的数据集合数据量小。对连接列字段的所有数据值,进行Hash函数操作。Hash函数是计算机科学中经常使用到的一种处理函数,利用Hash值的快速搜索算法已经被认为是成熟的检索手段。Hash函数处理过的数据特征是“相同数据值的Hash函数值一定相同,不同数据值的Hash函数值可能相同”;
ii. 经过Hash处理过的小表连接列,连同数据一起存放到Oracle PGA空间中。PGA中存在一块空间为hash_area,专门存放此类数据。并且,依据不同的Hash函数值,进行划分Bucket操作。每个Bucket中包括所有相同hash函数值的小表数据。同时建立Hash键值对应位图。
iii. 之后对进行Hash连接大表数据连接列依次读取,并且将每个Hash值进行Bucket匹配,定位到适当的Bucket上(应用Hash检索算法);
iv. 在定位到的Bucket中,进行小规模的精确匹配。因为此时的范围已经缩小,进行匹配的成功率精确度高。同时,匹配操作是在内存中进行,速度较Merge Sort Join时要快很多;
哈希连接(HASH JOIN)是一种两个表在做表连接时主要依靠哈希运算来得到连接结果集的表连接方法。
对于哈希连接的优缺点及适用场景如下:
a,哈希连接不一定会排序,或者说大多数情况下都不需要排序
b,哈希连接的驱动表所对应的连接列的选择性尽可能好。
c,哈希只能用于CBO,而且只能用于等值连接的条件。(即使是哈希反连接,ORACLE实际上也是将其换成等值连接)。
c,哈希连接很适用小表和大表之间做连接且连接结果集的记录数较多的情形,特别是小表的选择性非常好的情况下,这个时候哈希连接的执行时间就可以近似看做和全表扫描个个大表的费用时间相当。
e,当两个哈希连接的时候,如果在施加了目标SQL中指定的谓词条件后得到的数据量较小的那个结果集所对应的HASH TABLE能够完全被容纳在内存中(PGA的工作区),此时的哈希连接的执行效率非常高。
oracle表之间的连接之哈希连接(Hash Join),其特点如下:
1,驱动表和被驱动表都是最多只被访问一次。
2,哈希连接的表有驱动顺序。
3,哈希表连接的表无需要排序,但是他在做连接之前做哈希运算的时候,会用到HASH_AREA_SIZE来创建哈希表。
4,哈希连接不适用于的连接条件是:不等于<>,大于>,小于<,小于等于<=,大于等于>=,like。
5,哈希连接索引列在表连接中无特殊要求,与单表情况无异。
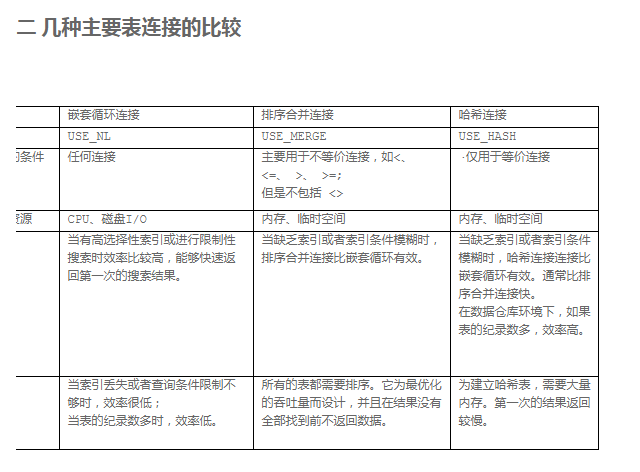
a) 对于非等值连接,这种连接方式的效率是比较高的。
b) 如果在关联的列上都有索引,效果更好。
c) 对于将2个较大的row source做连接,该连接方法比NL连接要好一些。
d) 但是如果sort merge返回的row source过大,则又会导致使用过多的rowid在表中查询数据时,数据库性能下降,因为过多的I/O.
a) 如果driving row source(外部表)比较小,并且在inner row source(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。
b) NESTED LOOPS有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
a) 这种方法是在oracle7后来引入的,使用了比较先进的连接理论,一般来说,其效率应该好于其它2种连接,但是这种连接只能用在CBO优化器中,而且需要设置合适的hash_area_size参数,才能取得较好的性能。
b) 在2个较大的row source之间连接时会取得相对较好的效率,在一个row source较小时则能取得更好的效率。
c) 只能用于等值连接中
如何看懂执行计划可以参考:
http://blog.51cto.com/xiao1ang/1900950
执行计划是如何访问数据的:
Full Table Scan (FTS) --全表扫描
Index Lookup (unique & non-unique) --索引扫描(唯一和非唯一)
索引扫描其实分为两步:
Ⅰ:扫描索引得到对应的ROWID
Ⅱ:通过ROWID定位到具体的行读取数据
Rowid --物理行id 最快的方法
表访问方式:
1.Full Table Scan (FTS) 全表扫描
In a FTS operation, the whole table is read up to the high water mark (HWM). The HWM marks the last block in the table that has ever had data written to it. If you have deleted all the rows then you will still read up to the HWM. Truncate resets the HWM back to the start of the table. FTS uses multiblock i/o to read the blocks from disk. --全表扫描模式下会读数据到表的高水位线(HWM即表示表曾经扩展的最后一个数据块),读取速度依赖于Oracle初始化参数db_block_multiblock_read_count(我觉得应该这样翻译:FTS扫描会使表使用上升到高水位(HWM),HWM标识了表最后写入数据的块,如果你用DELETE删除了所有的数据表仍然处于高水位(HWM),只有用TRUNCATE才能使表回归,FTS使用多IO从磁盘读取数据块).
Query Plan
------------------------------------
SELECT STATEMENT [CHOOSE] Cost=1
**INDEX UNIQUE SCAN EMP_I1 --如果索引里就找到了所要的数据,就不会再去访问表
2.Index Lookup 索引扫描
There are 5 methods of index lookup:
index unique scan --索引唯一扫描
针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录;
表中某字段存在 UNIQUE、PRIMARY KEY 约束时,Oracle常实现唯一性扫描;
index range scan --索引局部扫描
使用一个索引存取多行数据;
发生索引范围扫描的三种情况:
- 在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
- 对非唯一索引列上进行的任何查询
index full scan --索引全局扫描
进行全索引扫描时,查询出的数据都必须从索引中可以直接得到(注意全索引扫描只有在CBO模式下才有效)
index fast full scan --索引快速全局扫描,不带order by情况下常发生
扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
index skip scan --索引跳跃扫描,where条件列是非索引的前导列情况下常发生
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
什么时候会触发 INDEX SKIP SCAN 呢?
前提条件:表有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件,并且优化器模式为CBO时
当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询;
例如:
假设表emp有ename(雇员名称)、job(职位名)、sex(性别)三个字段,并且建立了如 create index idx_emp on emp (sex, ename, job) 的复合索引;
因为性别只有 '男' 和 '女' 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 ('男', ename, job),('女', ename, job) 这两个复合索引;
当查询 select * from emp where job = 'Programmer' 时,该查询发出后:
Oracle先进入sex为'男'的入口,这时候使用到了 ('男', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
再进入sex为'女'的入口,这时候使用到了 ('女', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
最后合并查询到的来自两个入口的结果集。
3.Rowid 物理ID扫描
This is the quickest access method available.Oracle retrieves the specified block and extracts the rows it is interested in. --Rowid扫描是最快的访问数据方式
七、运算符
1.sort --排序,很消耗资源
There are a number of different operations that promote sorts:
(1)order by clauses (2)group by (3)sort merge join –-这三个会产生排序运算
2.filter --过滤,如not in、min函数等容易产生
Has a number of different meanings, used to indicate partition elimination, may also indicate an actual filter step where one row source is filtering, another, functions such as min may introduce filter steps into query plans.
3.view --视图,大都由内联视图产生(可能深入到视图基表)
When a view cannot be merged into the main query you will often see a projection view operation. This indicates that the 'view' will be selected from directly as opposed to being broken down into joins on the base tables. A number of constructs make a view non mergeable. Inline views are also non mergeable.
eg: SQL> explain plan for
select ename,tot from emp,(select empno,sum(empno) tot from big_emp group by empno) tmp
where emp.empno = tmp.empno;
Query Plan
------------------------
SELECT STATEMENT [CHOOSE]
**HASH JOIN
**TABLE ACCESS FULL EMP [ANALYZED]
**VIEW
****SORT GROUP BY
******INDEX FULL SCAN BE_IX
4.partition view --分区视图
Partition views are a legacy technology that were superceded by the partitioning option. This section of the article is provided as reference for such legacy systems.