刚刚接触爬虫,听说webmagic很不错,于是就了解了一下。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
这句话说的真的一点都不假,像我这样什么都不懂的人直接下载部署,看了看可以调用的方法,马上就写出了第一个爬虫小程序。
以下是我学习的过程:
首先需要下载jar:http://webmagic.io/download.html
部署好后就建一个class继承PageProcessor接口,重写process()方法,即可完成一个爬虫。
是不是很简单?
先上代码,再讲解吧。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class MyProcessor implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count =0;
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
//判断链接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
if(!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()){
//加入满足条件的链接
page.addTargetRequests(
page.getHtml().xpath("//*[@id="post_list"]/div/div[@class='post_item_body']/h3/a/@href").all());
}else{
//获取页面需要的内容
System.out.println("抓取的内容:"+
page.getHtml().xpath("//*[@id="Header1_HeaderTitle"]/text()").get()
);
count ++;
}
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
}
由于刚开始学,技术有限,所以简单地爬一下这些文章的作者。
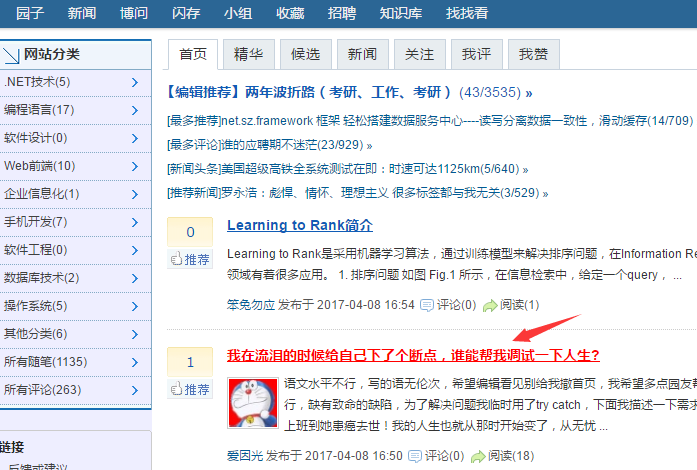
要爬取,首先得知道内容在哪个位置上。在chrome下审查一下元素发现,文章都在这里
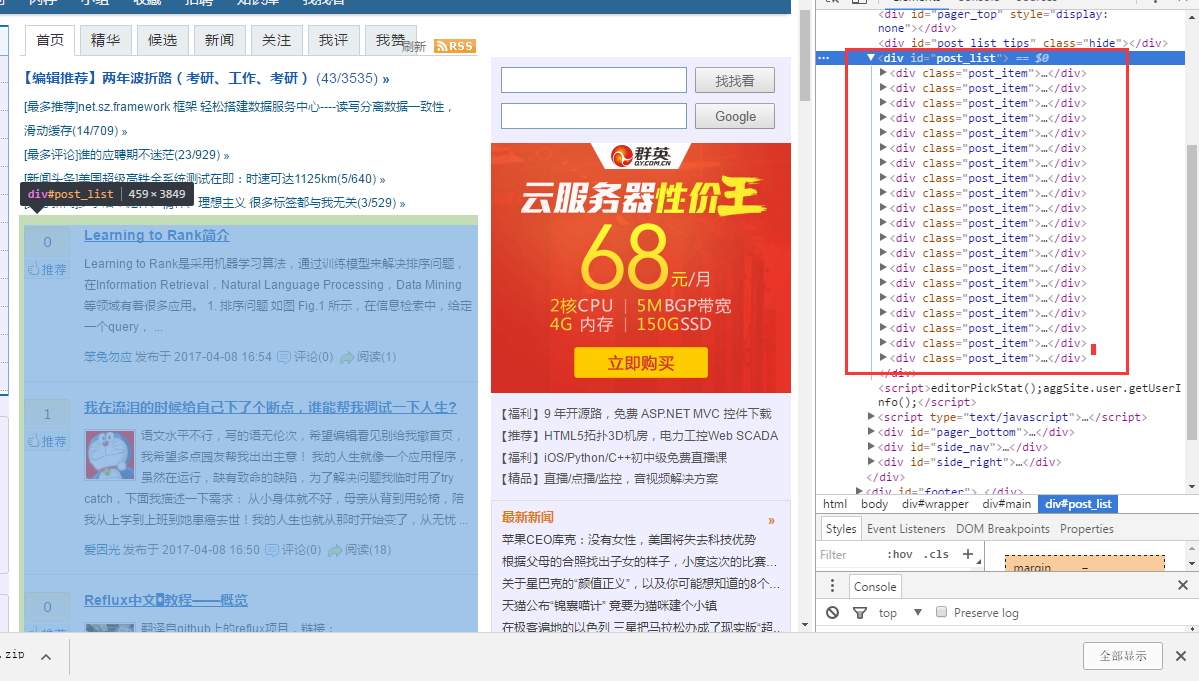
点进文章后审查元素发现作者的名字在这里
知道要爬的内容在哪个位置之后。我们还需要知道怎样才能拿到这些数据。
这里说一下webmagic的内容
启动爬虫就这句:Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();//addUrl就是种子url
Page对象就是当前获取的页面,
getUrl()可以获得当前url,
addTargetRequests()就是把链接放入等待爬取
getHtml()获得页面的html元素
上面这些很容易就能知道它的意思,不懂得是xpath();
刚开始学,我也不懂,但是chrome懂,所以可以让它帮我们写好xpath。
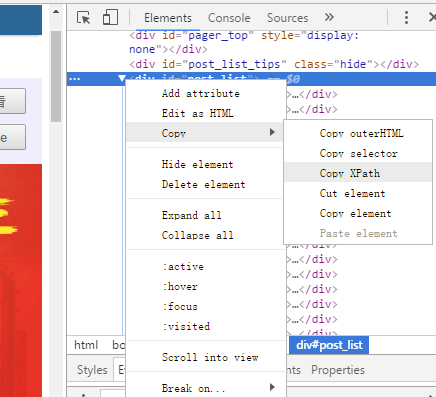
审查元素下,选择要需要的部分右键Copy,选择Copy XPath,然后在console下粘贴
关于xpath的教程可以查看https://www.one-tab.com/page/JFPOsHyvQUOQlzZwahc6-Q
关于webmagic的可以查看http://webmagic.io/docs/zh/posts/ch1-overview/