在面试中MySQL性能优化是经常被问到的问题,所以有必要去了解MySQL的性能优化。
一、优化思路
Mysql性能优化就算通过合理安排资源,调整系统参数使MYSQL运行更快,更节省资源。MYSQL性能优化包括查询速度优化,更新速度优化,mysql服务器优化等等。
- 选择合适的数据库引擎
- SQL优化
- 索引优化
- 优化排序
- 读写分离
- 表结构优化
- 硬件升级
- 使用表分区
二、具体分析
首先来查看SQL查询语法顺序和执行顺序,下面是MySQL查询语法顺序:
- SELECT
- FROM
- LEFT JOIN
- ON
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- LIMIT
接下来是MySQL查询执行顺序,用一个SQL实例:
SELECT name,max(age) as age FROM student s LEFT JOIN grades g ON s.id = g.id WHERE g.math >90 GROUP BY s.name HAVING age > 15 ORDER BY s.age LIMIT 0,10
- FROM(将最近的两张表,进行笛卡尔积)—VT1
- ON(将VT1按照它的条件进行过滤)—VT2
- LEFT JOIN(保留左表的记录)—VT3
- WHERE(过滤VT3中的记录)–VT4
- GROUP BY(对VT4的记录进行分组)—VT5
- HAVING(对VT5中的记录进行过滤)—VT6
- SELECT(对VT6中的记录,选取指定的列)–VT7
- ORDER BY(对VT7的记录进行排序)–游标
- LIMIT(对排序之后的值进行分页)
WHERE条件执行顺序(影响性能)
- MySQL:从左往右去执行where条件
- Oracle:从右往左执行where条件
所以写where条件的时候,优先级高的部分要去编写过滤力度最大的条件语句。
MySQL性能优化细节
- 合理的创建及使用索引(考虑数据的增删情况)。
- 合理的冗余字段(尽量建一些大表,考虑数据库的三范式和业务设计的取舍)。
- 使用SQL要注意一些细节:select语句中尽量不要使用*、count(*),WHERE语句中尽量不要使用1=1、in语句(建议使用exists)、注意组合索引的创建顺序按照顺序组着查询条件、尽量查询粒度大的SQL放到最左边、尽量建立组合索引。
- 合理利用慢查询日志、explain执行计划查询、show profile查看SQL执行时的资源使用情况。
- 表关联查询时务必遵循小表驱动大表原则。
- 使用查询语 where 条件时,不允许出现函数,否则索引会失效;
- 使用单表查询时,相同字段尽量不要用 OR,因为可能导致索引失效,比如:
SELECT * FROM table WHERE name = '手机' OR name = '电脑',可以使用 UNION 替代; - LIKE 语句不允许使用 % 开头,否则索引会失效;
- 组合索引一定要遵循 从左到右 原则,否则索引会失效;比如:
SELECT * FROM table WHERE name = '张三' AND age = 18,那么该组合索引必须是name,age形式; - 索引不宜过多,根据实际情况决定,尽量不要超过 10 个;
- 每张表都必须有 主键,达到加快查询效率的目的;
- 分表,可根据业务字段尾数中的个位或十位或百位(以此类推)做表名达到分表的目的;
- 分库,可根据业务字段尾数中的个位或十位或百位(以此类推)做库名达到分库的目的;
- 表分区,类似于硬盘分区,可以将某个时间段的数据放在分区里,加快查询速度,可以配合 分表 + 表分区 结合使用;
- <,<=,=,>,>=,BETWEEN,IN 可用到索引,<>,not in ,!= 则不行,会导致全表扫描
索引使用
索引设计原则
- 最适合索引的列是在where子句中的列,或连接子句中的列,而不是出现在select关键字后的列
- 使用唯一索引。考虑某列中值的分布。索引列的基数越大,效果越好(一列中相同的数据越少,索引越好)
-
使用短索引。如果对字符串列进行索引,应该指定一个前缀长度。这样可以节省索引空间和磁盘IO。(alter tableName add key indexName (columnName(7)) --给表tableName的columnName字段的前7位建立前缀做引,索引名字为indexName)
-
利用最左前缀。比如创建了一个多列索引 index_c1_c2_c3 (c1,c2,c3),相当于创建了(c1)单列索引,(c1,c2)的组合做引以及(c1,c2,c3)的组合索引。根据这个原则,在创建多列索引时,要根据业务需求 ,where子句中使用最频繁的一列要放在索引的最左边。
- 不要过度索引。索引过多,会导致磁盘占用较高,insert和update操作耗时增加,查询优化效率会变低。
最左前缀匹配原则
在MySQL中建立联合索引会遵循最左前缀的匹配原则,在检索数据时从联合索引的最左边开始匹配,先建立一个联合索引
CREATE INDEX index_name ON STUDENT(name,age,sex)
联合索引实际上建立了name、name,age、name,age,sex三个索引
为什么要使用联合索引
- 减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
- 覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
- 效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
数据库引擎对比
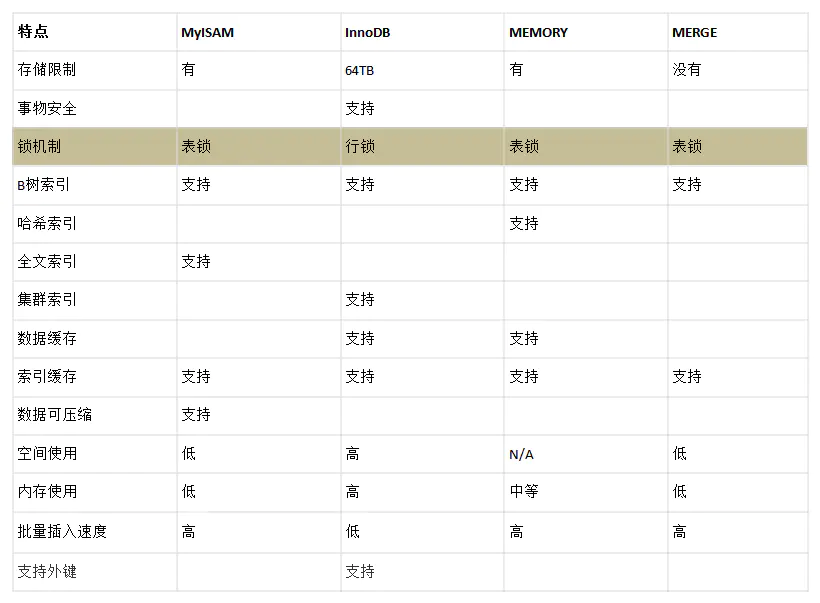
- MyISMA是MySQL的默认存储引擎。MyISMA不支持事务,不支持外键,优势是访问速度快,对事务完整性没有要求或者以SELECT、INSERT为主的应用基本上都可以使用MyISMA引擎。比较适合Web、数据仓储等场景。
- InnoDB存储引擎提供具有提交、回滚和崩溃恢复的事务安全,支持外键。对数据一致性要求比较高或更新比较频繁的的应用可以选择InnoDB。比较适合类似计费和财务系统等准确度要求比较高的系统。
- MEMORY存储引擎-内存数据库,服务重启数据会丢失。适用于那些内容变化不频繁的代码表(常量表),或者作为统计结果的中间结果表。修改的数据不会写入磁盘。
- MERGE存储引擎是一组MyISMA表的组合,这些MyISMA表的结构必须完全相同,MERGE表本身没有数据,对MERGE表的操作实际上是对内部的MyISMA表进行的。较适合数据仓储。
数据库架构演变
刚开始我们只用单机数据库就够了,随后面对越来越多的请求,我们将数据库的写操作和读操作进行分离, 使用多个从库副本(Slaver Replication)负责读,使用主库(Master)负责写, 从库从主库同步更新数据,保持数据一致。架构上就是数据库主从同步。 从库可以水平扩展,所以更多的读请求不成问题。但是当用户量级上来后,写请求越来越多,该怎么办?加一个Master是不能解决问题的, 因为数据要保存一致性,写操作需要2个master之间同步,相当于是重复了,而且更加复杂。这时就需要用到分库分表(sharding),对写操作进行切分。
一般就是垂直切分和水平切分,这是一种结果集描述的切分方式,是物理空间上的切分。 我们从面临的问题,开始解决,阐述: 首先是用户请求量太大,我们就堆机器搞定(这不是本文重点)。然后是单个库太大,这时我们要看是因为表多而导致数据多,还是因为单张表里面的数据多。 如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库。
如果是因为单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。 分库分表的顺序应该是先垂直分,后水平分。 因为垂直分更简单,更符合我们处理现实世界问题的方式。
表结构优化
垂直拆分
优点:垂直拆分可以使一个数据页放更多的数据,可以较少IO次数。
缺点:查询所需的数据可能需要通过JOIN来查询。
适用场景:表过宽,包含text或blob字段,可以将不常用的列或text/blob列放到另外的表中存储。比如文章表可以将文章内容拆分到另外的表中。
水平拆分
优点:减少大多数查询读取的数据量,降低索引层数,提高查询速度。
缺点:增加查询复杂度,查询多个表需要使用UNION,或者通过MERGE表。
适用场景:表中数据量过大,历史数据查询次数很少,比如订单信息、操作记录等。
逆规范化
增加冗余列:在多个表中具有相同的列,避免联合查询
增加派生列:增加的列来自其他表的计算结果,可避免使用函数
重新组表:将经常联合查询的表组成一个表,减少联合查询
库结构优化
垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。为什么? 我们想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
水平分库分表切分规则
- RANGE:从0到10000一个表,10001到20000一个表;
- HASH取模:一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
- 地理区域:比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
- 时间:按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
分库分表原则
- 能不分就不分,1000 万以内的表,不建议分片,通过合适的索引,读写分离等方式,可以很好的解决性能问题。
- 分片数量尽量少,分片尽量均匀分布在多个 DataHost 上,因为一个查询 SQL 跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量。
- 分片规则需要慎重选择,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性 Hash 分片,这几种分片都有利于扩容。
- 尽量不要在一个事务中的 SQL 跨越多个分片,分布式事务一直是个不好处理的问题。
- 尽量不要在一个事务中的 SQL 跨越多个分片,分布式事务一直是个不好处理的问题。