1.数据库
数据删除 delete drop truncate
索引过多会导致查询速度过慢 ,降低性能。因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
group by 是分组的,和having
WHERE过滤行,HAVING过滤组
例如,查找雇员平均工资大于3000的部门的最高薪水和最低薪水:
-
SELECT dept,MAX(salary) AS MAXIMUM,MIN(salary) AS MINIMUM -
FROM STAFF -
GROUP BY dept -
HAVING AVG(salary) > 3000 -
ORDER BY dept
查询结果如下:
-
dept MAXIMUM MINIMUM -
销售部 3500 3000
2.python
基本类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
number Python3 支持 int、float、bool、complex(复数)。
list 列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
3.数据结构
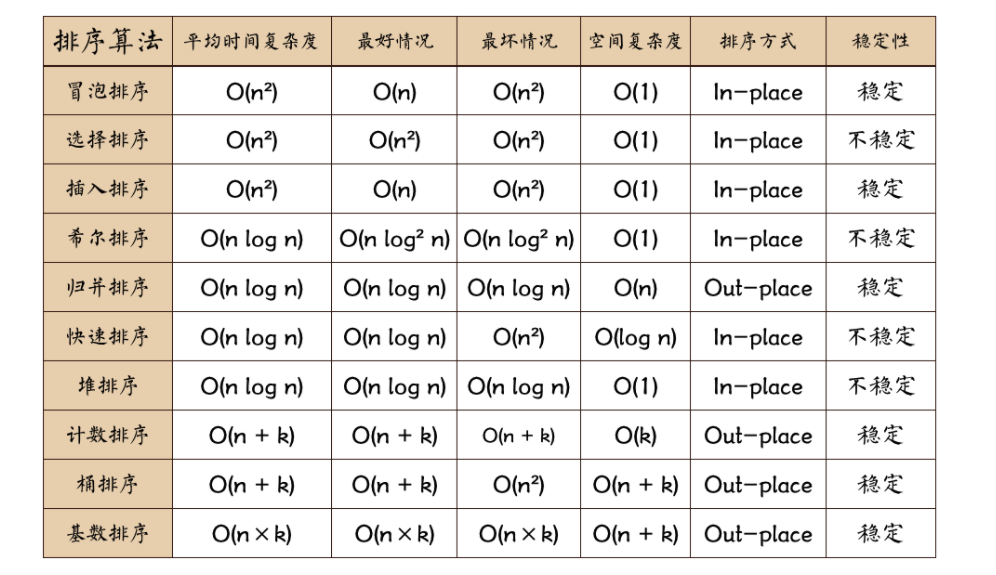
数组、链表
数组和链表都是线性表的结构,只不过它们的存储方式不一样;
根据存储方式不同,可将线性表分为顺序表和链式表;
线性表是数据结构中的逻辑结构。可以存储在数组上,也可以存储在链表上。
一句话,用数组来存储的线性表就是顺序表。
数组:在内存中,是一块连续的内存区域;
链表:是由不连续的内存空间组成;
数组优点: 随机访问性强,查找速度快(连续内存空间导致的);
数组缺点: 插入和删除效率低 可能浪费内存 内存空间要求高,必须有足够的连续内存空间。数组大小固定,不能动态拓展链表的优点: 插入删除速度快 内存利用率高,不会浪费内存 大小没有固定,拓展很灵活。(每一个数据存储了下一个数据的地址,增删效率高)
链表的缺点:不能随机查找,必须从第一个开始遍历,查找效率低
4.网络
get 和post区别:
- get从服务端请求数据,post传递
- 传递的大小有区别。get 有限的大小2kb,post不限大小
- url requestely
- 场景不一样。文本 文本和二进制
- get发送的数据是url的一部分,不安全。post比较安全,因为参数不保存在浏览器历史和web服务器日志
head options delete put
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、PUT请求是向服务器端发送数据的(与GET不同)从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
4、DELETE请求顾名思义,就是用来删除某一个资源的,该请求就像数据库的delete操作。
就像前面所讲的一样,既然PUT和POST操作都是向服务器端发送数据的,那么两者有什么区别呢。。。POST主要作用在一个集合资源之上的(url),而PUT主要作用在一个具体资源之上的(url/xxx),通俗一下讲就是,如URL可以在客户端确定,那么可使用PUT,否则用POST
1、POST /url 创建
2、DELETE /url/xxx 删除
3、PUT /url/xxx 更新
4、GET /url/xxx 查看
TCP 长链接 短链接
长连接:
所谓长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持(不发生RST包和四次挥手)。
连接→数据传输→保持连接(心跳)→数据传输→保持连接(心跳)→……→关闭连接(一个TCP连接通道多个读写通信);
这就要求长连接在没有数据通信时,定时发送数据包(心跳),以维持连接状态;
TCP保活功能,保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将应远等待客户端的数据,保活功能就是试图在服务器端检测到这种半开放的连接。
如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态之一:
- 客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
- 客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
- 客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
- 客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探查的响应。
短连接:
短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接(管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段);
连接→数据传输→关闭连接;
应用场景:
长连接多用于操作频繁(读写),点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接(http1.0只支持短连接,1.1keep alive 带时间,操作次数限制的长连接),因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好;
在长连接中一般是没有条件能够判断读写什么时候结束,所以必须要加长度报文头。读函数先是读取报文头的长度,再根据这个长度去读相应长度的报文。
5.lunix
查看日志:tail
6.前台
cookie section
Cookie是服务器在本地机器上存储的小段文本并随每一个请求发送至同一服务器。Cookies保存在客户端,主要内容包括:名字,值,过期时间,路径等等。
Session是在服务器端保存用户数据。浏览器第一次发送请求时,服务器自动生成了Session ID来唯一标识这个并将其通过响应发送到浏览器。浏览器第二次发送请求会将前一次服务器响应中的Session ID放在请求中一并发送到服务器上,服务器从请求中提取出Session ID,并和保存的所有Session ID进行对比,找到这个用户的信息。一般这个Session ID会有个时间限制,默认30分钟超时后毁掉这次Session ID。
Session和Cookie有一定关系,Session id存在Cookie中,每次访问的时候将Session id传到服务器进行对比。
(1)cookie数据存放在客户的浏览器上,session数据放在服务器上
(2)cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
(3)session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
(4)单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
(5)所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
- Cookie 在客户端(浏览器、易伪造、不安全),Session 在服务器端(会消耗服务器资源)。
- Cookie 只能保存ASCII字符串,如果是Unicode字符或者二进制数据需要先进行编码。Cookie中也不能直接存取Java对象。 Session能够存取很多类型的数据,包括String、Integer、List、Map等,Session中也可以保存JJava对象。
7.操作系统
指令分类