什么是TF-IDF[维基百科]
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率).是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序
简单来说就是:一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语


以上式子中

逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。公式:

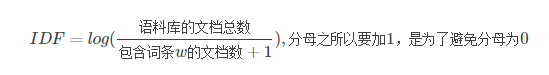
其中
- |D|:语料库中的文件总数
:包含词语
的文件数目)如果词语不在数据中,就导致分母为零,因此一般情况下使用

然后

某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。
第一步,计算词频:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

第二步,计算逆文档频率:
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
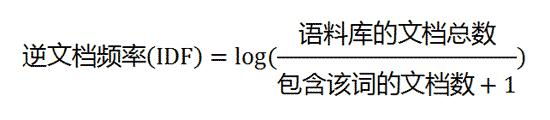
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF:
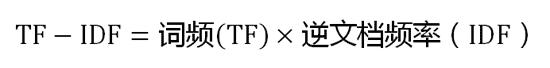
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
优缺点
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。如果要体现词的上下文结构,那么你可能需要使用word2vec算法来支持。
例子来源-数学之美:

简单代码例子:
#!/usr/bin/env python # -*- coding: utf-8 -*- import os from math import log def TF_IDF(path, dic): tf_idf = {} fold_list = os.listdir(path) count = 0 idf = {} for key in dic.keys(): idf[key] = 1 tf_idf[key] = 0 for flod in fold_list: file_list = os.listdir(path + os.sep + flod) count += len(file_list) for file in file_list: with open(path + os.sep + flod + os.sep + file) as f: text = f.read() for key in dic.keys(): if key in text: idf[key] += 1 for key, value in idf.items(): idf[key] = log(count / value + 1) for key, value in tf_idf.items(): tf_idf[key] = dic[key] * idf[key] return tf_idf