HDFS高可用性
Hadoop HDFS 的两大问题:
NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用
--阶段性的合并edits和fsimage,以缩短集群启动的时间
--当NameNode失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性
--如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失
NameNode扩展性问题:单NameNode元数据不可扩展,是整个HDFS集群的瓶颈
Hadoop HDFS高可用架构解决方案:
--NameNode HA:解决NameNode单点
--HDFS Federation:解决NameNode扩展性问题
NameNode HA
--两个NameNode,一个Active,一个Standby
--利用共享存储来在两个NN间同步edits信息
----两种方案:QJM/NFS
--DataNode同时向两个NN汇报块信息
--ZKFC用于监视和控制NN进程的FailoverController进程
----用ZooKeeper来做同步锁,leader选举
--Fencing防止脑裂,保证只有一个NN
----共享存储,确保只有一个NN可以写入edits
----客户端,确保只有一个NN可以响应客户端的请求
----DataNode,确保只有一个NN可以向DN下发命令
HDFS Federation
--多个NN共用一个集群里DN上的存储资源,每个NN都可以单独对外提供服务,每个NN都是一个独立的命名空间(NameSpace)
--每个NN都会定义一个存储池(BlockPool),有单独的id,每个DN都为所有存储池提供存储
--DN会按照BlockPool ID向其对应的NN汇报块信息,同时DN会向所有NN汇报本地存储可用资源情况
--如果需要在客户端方便的访问若干个NN上的资源,可以使用ViewFS协议客户端挂载表(mountTable),把不同的目录映射到不同的NN,但NN上必须存在相应的目录
---环境测试
Hadoop 版本: apache hadoop 2.9.1
JDK 版本: Oracle JDK1.8
集群规划
master(1): NN, RM, DN, NM, JHS
slave1(2): DN, NM
slave2(3): DN, NM
jdk-8u172-linux-x64.tar.gz
hadoop-2.9.1.tar.gz
---环境跟上一次类似
修改配置文件
#####在之前的hadoop集群上,将StandbyNameNode 变为NN HA,YARN HA [root@hadoop1 hadoop]# vim core-site.xml <property> <name>ha.zookeeper.quorum</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property> [root@hadoop1 hadoop]# vim hdfs-site.xml <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop2:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns1.nn1</name> <value>hadoop1:8040</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns1.nn2</name> <value>hadoop2:8040</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop1:50070</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop2:50070</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoopdata/hdfs/journal</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> mkdir -p /opt/hadoopdata/hdfs/journal chown -R hadoop:hadoop /opt/hadoopdata/hdfs/journal [root@hadoop1 hadoop]# vim yarn-site.xml <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop2</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property> [root@hadoop1 hadoop]# scp core-site.xml hdfs-site.xml yarn-site.xml hadoop2:/opt/hadoop/etc/hadoop/. [root@hadoop1 hadoop]# scp core-site.xml hdfs-site.xml yarn-site.xml hadoop3:/opt/hadoop/etc/hadoop/.
[hadoop@hadoop1 hadoop]$ vim hdfs-site.xml <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop2:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///opt/hadoopdata/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:////opt/hadoopdata/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> [hadoop@hadoop1 hadoop]$ scp hdfs-site.xml hadoop2:/opt/hadoop/etc/hadoop/.
######安装配置zookeeper
tar zxvf zookeeper-3.4.10.tar.gz [root@hongquan2 zookeeper-3.4.10]# mkdir {logs,data} 配置zoo.cfg cp /opt/zookeeper-3.4.10/conf/zoo_sample.cfg /opt/zookeeper-3.4.10/conf/zoo.cfg vim /opt/zookeeper-3.4.10/conf/zoo1.cfg [root@hongquan2 codis]# cat /opt/zookeeper-3.4.10/conf/zoo.cfg |grep -Ev "^#|^$" tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/zookeeper-3.4.10/data/ dataLogDir=/opt/zookeeper-3.4.10/logs/ clientPort=2181 server.1=1:2888:3888 server.2=2:2888:3888 server.3=3:2888:3888 在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字 [root@hadoop1 conf]# echo 1 > /opt/zookeeper-3.4.10/data/myid [root@hadoop2 conf]# echo 2 > /opt/zookeeper-3.4.10/data/myid [root@hadoop3 conf]# echo 3 > /opt/zookeeper-3.4.10/data/myid #####启动zookeeper并加入自启动 [root@hadoop1 conf]# /opt/zookeeper-3.4.10/bin/zkServer.sh start [root@hadoop2 conf]# /opt/zookeeper-3.4.10/bin/zkServer.sh start [root@hadoop3 conf]# /opt/zookeeper-3.4.10/bin/zkServer.sh start [root@hadoop1 conf]# netstat -anp | grep 3888 [root@hadoop1 conf]# /opt/zookeeper-3.4.10/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower [root@hadoop2 conf]# /opt/zookeeper-3.4.10/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: leader [root@hadoop3 zookeeper-3.4.10]# /opt/zookeeper-3.4.10/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower ####格式化zookeeper集群(只做一次)--leader节点上执行 [hadoop@hadoop1 ~]$ hdfs zkfc -formatZK [hadoop@hadoop2 ~]$ hdfs zkfc -formatZK Proceed formatting /hadoop-ha/ns1? (Y or N) 19/06/14 10:31:47 INFO ha.ActiveStandbyElector: Session connected. Y 19/06/14 10:31:53 INFO ha.ActiveStandbyElector: Recursively deleting /hadoop-ha/ns1 from ZK... 19/06/14 10:31:53 INFO ha.ActiveStandbyElector: Successfully deleted /hadoop-ha/ns1 from ZK. 19/06/14 10:31:53 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns1 in ZK. 19/06/14 10:31:53 INFO zookeeper.ClientCnxn: EventThread shut down 19/06/14 10:31:53 INFO zookeeper.ZooKeeper: Session: 0x16b53cab7fa0000 closed 19/06/14 10:31:53 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG: /************************************************************ ************************************************************/ ###进入zk, 查看是否创建成功 [hadoop@hadoop2 ~]$ /opt/zookeeper-3.4.10/bin/zkCli.sh [zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha [ns1] [zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha/ns1 []
###启动zkfc [hadoop@hadoop1 ~]$ hadoop-daemon.sh start zkfc ###使用jps, 可以看到进程DFSZKFailoverController [hadoop@hadoop1 hadoop]$ jps 4625 DFSZKFailoverController 4460 QuorumPeerMain 4671 Jps [hadoop@hadoop2 ~]$ hadoop-daemon.sh start zkfc starting zkfc, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-zkfc-hadoop2.out [hadoop@hadoop2 ~]$ jps 3537 DFSZKFailoverController 3336 QuorumPeerMain 3582 Jps ###启动journalnode [hadoop@hadoop1 ~]$ hadoop-daemon.sh start journalnode starting journalnode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-journalnode-hadoop1.out [hadoop@hadoop2 ~]$ hadoop-daemon.sh start journalnode starting journalnode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-journalnode-hadoop2.out [hadoop@hadoop1 hadoop]$ jps 4625 DFSZKFailoverController 4698 JournalNode 4460 QuorumPeerMain 4749 Jps [hadoop@hadoop2 ~]$ jps 3537 DFSZKFailoverController 3606 JournalNode 3336 QuorumPeerMain 3658 Jps [hadoop@hadoop3 ~]$ hadoop-daemon.sh start journalnode starting journalnode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-journalnode-hadoop3.out ###格式化namenode [hadoop@hadoop1 opt]$ hdfs namenode -format 19/06/14 16:58:51 INFO common.Storage: Storage directory /opt/hadoopdata/hdfs/name has been successfully formatted. ###启namenode [hadoop@hadoop1 opt]$ /opt/hadoop/sbin/hadoop-daemon.sh start namenode [hadoop@hadoop1 hadoop]$ jps 4625 DFSZKFailoverController 4947 Jps 4698 JournalNode 4460 QuorumPeerMain 4829 NameNode ###格式化secondnamnode [hadoop@hadoop2 sbin]$ /opt/hadoop/bin/hdfs namenode -bootstrapStandby ####启动namenode [hadoop@hadoop2 sbin]$ /opt/hadoop/sbin/hadoop-daemon.sh start namenode [hadoop@hadoop2 ~]$ jps 3537 DFSZKFailoverController 3748 NameNode 3845 Jps 3606 JournalNode 3336 QuorumPeerMain ###启动datanode [hadoop@hadoop1 hadoop]$ /opt/hadoop/sbin/hadoop-daemon.sh start datanode [hadoop@hadoop2 hadoop]$ /opt/hadoop/sbin/hadoop-daemon.sh start datanode [hadoop@hadoop3 hadoop]$ /opt/hadoop/sbin/hadoop-daemon.sh start datanode [hadoop@hadoop1 hadoop]$ jps 4625 DFSZKFailoverController 5077 Jps 4986 DataNode 4698 JournalNode 4460 QuorumPeerMain 4829 NameNode [hadoop@hadoop2 ~]$ jps 3537 DFSZKFailoverController 3748 NameNode 3974 Jps 3878 DataNode 3606 JournalNode 3336 QuorumPeerMain [hadoop@hadoop3 ~]$ jps 3248 DataNode 3332 Jps 3078 QuorumPeerMain 3149 JournalNode ###启动resourcemanager [hadoop@hadoop1 hadoop]$ /opt/hadoop/sbin/yarn-daemon.sh start resourcemanager [hadoop@hadoop2 hadoop]$ /opt/hadoop/sbin/yarn-daemon.sh start resourcemanager ###启动jobhistory [hadoop@hadoop1 hadoop]$ /opt/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/hadoop-2.9.1/logs/mapred-hadoop-historyserver-hadoop1.out [hadoop@hadoop1 hadoop]$ jps 5376 JobHistoryServer 4625 DFSZKFailoverController 5107 ResourceManager 5417 Jps 4986 DataNode 4698 JournalNode 4460 QuorumPeerMain 4829 NameNode ###启动NodeManager [hadoop@hadoop1 hadoop]$ /opt/hadoop/sbin/yarn-daemon.sh start nodemanager [hadoop@hadoop2 hadoop]$ /opt/hadoop/sbin/yarn-daemon.sh start nodemanager [hadoop@hadoop3 hadoop]$ /opt/hadoop/sbin/yarn-daemon.sh start nodemanager ##安装后查看和验证 [hadoop@hadoop1 hadoop]$ hdfs haadmin -getServiceState nn1 19/06/14 17:09:53 DEBUG util.Shell: setsid exited with exit code 0 19/06/14 17:09:53 DEBUG tools.DFSHAAdmin: Using NN principal: 19/06/14 17:09:53 DEBUG namenode.NameNode: Setting fs.defaultFS to hdfs://hadoop1:8020 19/06/14 17:09:53 DEBUG ipc.ProtobufRpcEngine: Call: getServiceStatus took 105ms active [hadoop@hadoop1 hadoop]$ hdfs haadmin -getServiceState nn2 19/06/14 17:11:29 DEBUG ipc.ProtobufRpcEngine: Call: getServiceStatus took 107ms standby


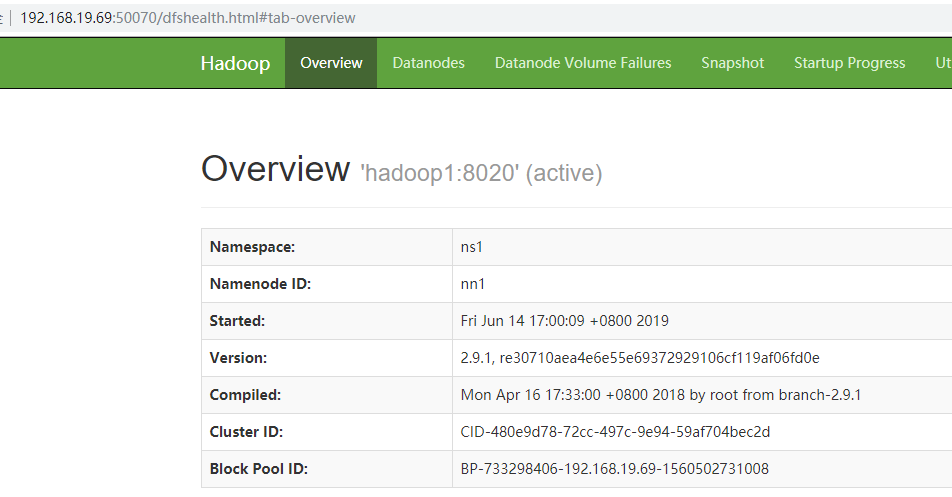
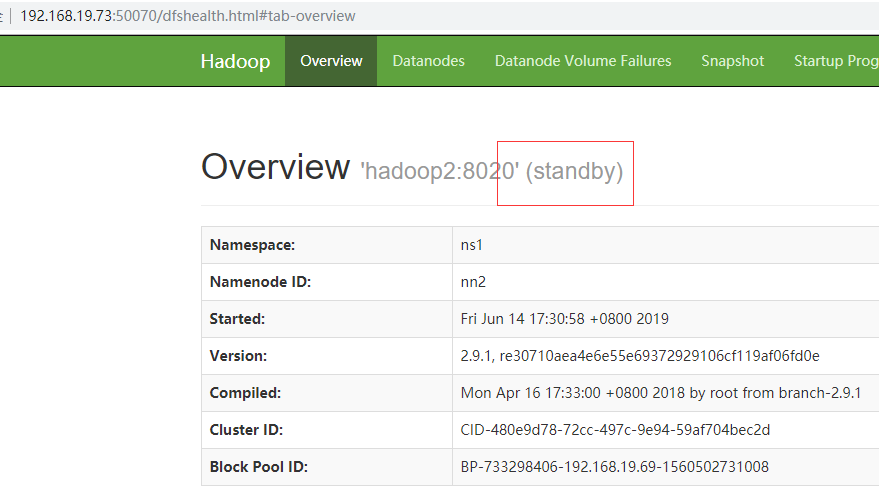
手工切换,将active的NameNode从nn1切换到nn2 [hadoop@hadoop1 hadoop]$ hdfs haadmin -DfSHAadmin -failover nn1 nn2 19/06/14 17:20:16 DEBUG ipc.ProtobufRpcEngine: Call: gracefulFailover took 1467ms Failover to NameNode at hadoop2/2:8040 successful

##切换后分别查看状态
19/06/14 17:21:33 DEBUG ipc.Client: Connecting to hadoop1/1:8040 19/06/14 17:21:33 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop1/1:8040 from hadoop: starting, having connections 1 19/06/14 17:21:33 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop1/1:8040 from hadoop sending #0 org.apache.hadoop.ha.HAServiceProtocol.getServiceStatus 19/06/14 17:21:33 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop1/1:8040 from hadoop got value #0 19/06/14 17:21:33 DEBUG ipc.ProtobufRpcEngine: Call: getServiceStatus took 92ms standby
19/06/14 17:21:53 DEBUG ipc.Client: getting client out of cache: org.apache.hadoop.ipc.Client@dd8ba08 19/06/14 17:21:53 DEBUG ipc.Client: The ping interval is 60000 ms. 19/06/14 17:21:53 DEBUG ipc.Client: Connecting to hadoop2/2:8040 19/06/14 17:21:53 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop2/2:8040 from hadoop: starting, having connections 1 19/06/14 17:21:53 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop2/2:8040 from hadoop sending #0 org.apache.hadoop.ha.HAServiceProtocol.getServiceStatus 19/06/14 17:21:53 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop2/2:8040 from hadoop got value #0 19/06/14 17:21:53 DEBUG ipc.ProtobufRpcEngine: Call: getServiceStatus took 87ms active
NameNode健康检查:


[hadoop@hadoop1 hadoop]$ hdfs haadmin -checkHealth nn1 19/06/14 17:22:47 DEBUG util.Shell: setsid exited with exit code 0 19/06/14 17:22:48 DEBUG tools.DFSHAAdmin: Using NN principal: 19/06/14 17:22:48 DEBUG namenode.NameNode: Setting fs.defaultFS to hdfs://hadoop1:8020 19/06/14 17:22:48 DEBUG security.SecurityUtil: Setting hadoop.security.token.service.use_ip to true 19/06/14 17:22:48 DEBUG lib.MutableMetricsFactory: field org.apache.hadoop.metrics2.lib.MutableRate org.apache.hadoop.security.UserGroupInformation$UgiMetrics.loginSuccess with annotation @org.apache.hadoop.metrics2.annotation.Metric(about=, always=false, sampleName=Ops, type=DEFAULT, valueName=Time, value=[Rate of successful kerberos logins and latency (milliseconds)]) 19/06/14 17:22:48 DEBUG lib.MutableMetricsFactory: field org.apache.hadoop.metrics2.lib.MutableRate org.apache.hadoop.security.UserGroupInformation$UgiMetrics.loginFailure with annotation @org.apache.hadoop.metrics2.annotation.Metric(about=, always=false, sampleName=Ops, type=DEFAULT, valueName=Time, value=[Rate of failed kerberos logins and latency (milliseconds)]) 19/06/14 17:22:48 DEBUG lib.MutableMetricsFactory: field org.apache.hadoop.metrics2.lib.MutableRate org.apache.hadoop.security.UserGroupInformation$UgiMetrics.getGroups with annotation @org.apache.hadoop.metrics2.annotation.Metric(about=, always=false, sampleName=Ops, type=DEFAULT, valueName=Time, value=[GetGroups]) 19/06/14 17:22:48 DEBUG lib.MutableMetricsFactory: field private org.apache.hadoop.metrics2.lib.MutableGaugeLong org.apache.hadoop.security.UserGroupInformation$UgiMetrics.renewalFailuresTotal with annotation @org.apache.hadoop.metrics2.annotation.Metric(about=, always=false, sampleName=Ops, type=DEFAULT, valueName=Time, value=[Renewal failures since startup]) 19/06/14 17:22:48 DEBUG lib.MutableMetricsFactory: field private org.apache.hadoop.metrics2.lib.MutableGaugeInt org.apache.hadoop.security.UserGroupInformation$UgiMetrics.renewalFailures with annotation @org.apache.hadoop.metrics2.annotation.Metric(about=, always=false, sampleName=Ops, type=DEFAULT, valueName=Time, value=[Renewal failures since last successful login]) 19/06/14 17:22:48 DEBUG impl.MetricsSystemImpl: UgiMetrics, User and group related metrics 19/06/14 17:22:48 DEBUG security.Groups: Creating new Groups object 19/06/14 17:22:48 DEBUG util.NativeCodeLoader: Trying to load the custom-built native-hadoop library... 19/06/14 17:22:48 DEBUG util.NativeCodeLoader: Loaded the native-hadoop library 19/06/14 17:22:48 DEBUG security.JniBasedUnixGroupsMapping: Using JniBasedUnixGroupsMapping for Group resolution 19/06/14 17:22:48 DEBUG security.JniBasedUnixGroupsMappingWithFallback: Group mapping impl=org.apache.hadoop.security.JniBasedUnixGroupsMapping 19/06/14 17:22:48 DEBUG security.Groups: Group mapping impl=org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback; cacheTimeout=300000; warningDeltaMs=5000 19/06/14 17:22:48 DEBUG security.UserGroupInformation: hadoop login 19/06/14 17:22:48 DEBUG security.UserGroupInformation: hadoop login commit 19/06/14 17:22:48 DEBUG security.UserGroupInformation: using local user:UnixPrincipal: hadoop 19/06/14 17:22:48 DEBUG security.UserGroupInformation: Using user: "UnixPrincipal: hadoop" with name hadoop 19/06/14 17:22:48 DEBUG security.UserGroupInformation: User entry: "hadoop" 19/06/14 17:22:48 DEBUG security.UserGroupInformation: Assuming keytab is managed externally since logged in from subject. 19/06/14 17:22:48 DEBUG security.UserGroupInformation: UGI loginUser:hadoop (auth:SIMPLE) 19/06/14 17:22:48 DEBUG ipc.Server: rpcKind=RPC_PROTOCOL_BUFFER, rpcRequestWrapperClass=class org.apache.hadoop.ipc.ProtobufRpcEngine$RpcProtobufRequest, rpcInvoker=org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker@61862a7f 19/06/14 17:22:48 DEBUG ipc.Client: getting client out of cache: org.apache.hadoop.ipc.Client@dd8ba08 19/06/14 17:22:48 DEBUG ipc.Client: The ping interval is 60000 ms. 19/06/14 17:22:48 DEBUG ipc.Client: Connecting to hadoop1/192.168.19.69:8040 19/06/14 17:22:48 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop1/192.168.19.69:8040 from hadoop: starting, having connections 1 19/06/14 17:22:48 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop1/192.168.19.69:8040 from hadoop sending #0 org.apache.hadoop.ha.HAServiceProtocol.monitorHealth 19/06/14 17:22:48 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop1/192.168.19.69:8040 from hadoop got value #0 19/06/14 17:22:48 DEBUG ipc.ProtobufRpcEngine: Call: monitorHealth took 105ms
将其中一台NameNode给kill后, 查看健康状态: [hadoop@hadoop2 ~]$ jps 3537 DFSZKFailoverController 3748 NameNode 3878 DataNode 3606 JournalNode 3336 QuorumPeerMain 4411 Jps 4012 ResourceManager [hadoop@hadoop2 ~]$ kill 3748
[hadoop@hadoop1 hadoop]$ hdfs haadmin -checkHealth nn1
[hadoop@hadoop1 hadoop]$ hdfs haadmin -checkHealth nn2
##2节点

然后启动nn2 的namenode在查看变为standby
[hadoop@hadoop2 ~]$ /opt/hadoop/sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/hadoop/logs/hadoop-hadoop-namenode-hadoop2.out 19/06/14 17:31:03 DEBUG ipc.Client: IPC Client (413601558) connection to hadoop2/2:8040 from hadoop got value #0 19/06/14 17:31:03 DEBUG ipc.ProtobufRpcEngine: Call: getServiceStatus took 106ms standby
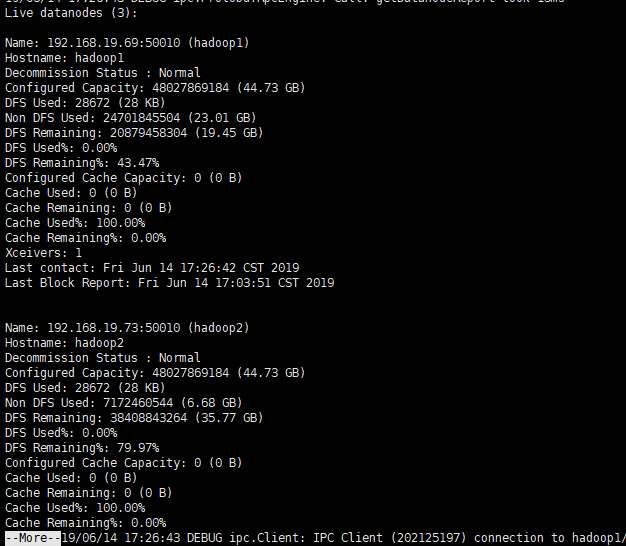
查看所有的DataNode列表
[hadoop@hadoop1 hadoop]$ hdfs dfsadmin -report | more
---

参考文档
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/index.html
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html