理解随机梯度下降,首先要知道梯度下降法,故先介绍梯度下降法:
梯度下降法
大多数机器学习或者深度学习算法都涉及某种形式的优化。 优化指的是改变 以最小化或最大化某个函数
的任务。 我们通常以最小化
指代大多数最优化问题。 最大化可经由最小化算法最小化
来实现。
我们把要最小化或最大化的函数称为目标函数或准则。 当我们对其进行最小化时,我们也把它称为代价函数、损失函数或误差函数。
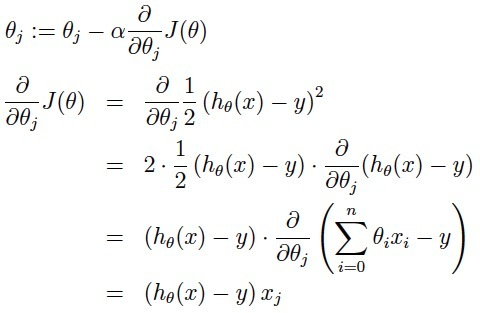
a表示的是步长或者说是学习率(learning rate),决定着梯度下降的步长。
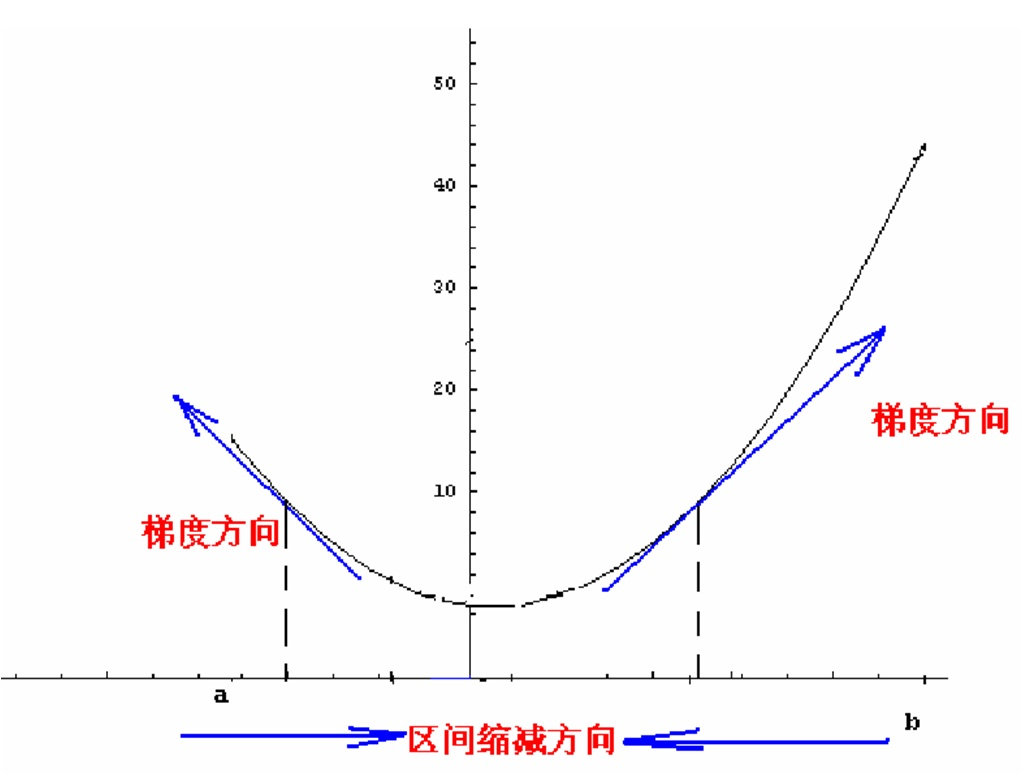
如图所示,我们假设函数是,那么如何使得这个函数达到最小值呢,简单的理解,就是对x求导,得到 y'=2x ,然后用梯度下降的方式,如果初始值是(0的左边)负值,那么这是导数也是负值,用梯度下降的公式,使得x更加的靠近0,如果是正值的时候同理。注意:这里的梯度也就是一元函数的导数,高维的可以直接类推之
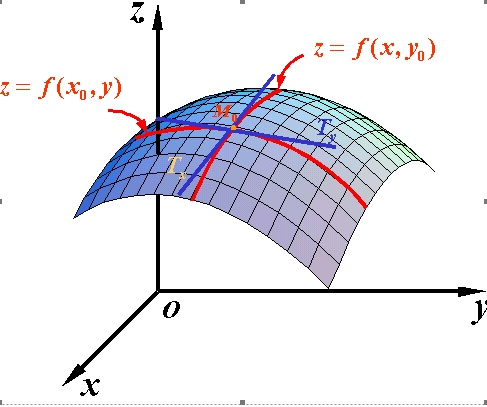
函数梯度:导数dy/dx的多变量表达式,用来表示y相对于x的瞬时变化率。往往为了计算多变量函数的导数时,会用梯度取代导数,并使用偏导数来计算梯度。梯度和导数之间的一个主要区别是函数的梯度形成了一个向量场。
因此,对单变量函数,使用导数来分析;而梯度是基于多变量函数而产生的。
1. 随机梯度下降(SDG)
随机梯度下降(Stochastic gradient descent,SGD)对每个训练样本进行参数更新,每次执行都进行一次更新,且执行速度更快。
θ=θ−η⋅∇(θ) × J(θ;x(i);y(i)),其中x(i)和y(i)为训练样本。
频繁的更新使得参数间具有高方差,损失函数会以不同的强度波动。这实际上是一件好事,因为它有助于我们发现新的和可能更优的局部最小值,而标准梯度下降将只会收敛到某个局部最优值。
但SGD的问题是,由于频繁的更新和波动,最终将收敛到最小限度,并会因波动频繁存在超调量。
虽然已经表明,当缓慢降低学习率η时,标准梯度下降的收敛模式与SGD的模式相同。
另一种称为“小批量梯度下降”的变体,则可以解决高方差的参数更新和不稳定收敛的问题。
2. 小批量梯度下降
为了避免SGD和标准梯度下降中存在的问题,一个改进方法为小批量梯度下降(Mini Batch Gradient Descent),因为对每个批次中的n个训练样本,这种方法只执行一次更新。
batch_sizebatch_size中的n通常设置为2的幂次方,通常设置2,4,8,16,32,64,128,256,5122,4,8,16,32,64,128,256,512(很少设置大于512)。因为设置成2的幂次方,更有利于GPU加速。
使用小批量梯度下降的优点是:
1) 可以减少参数更新的波动,最终得到效果更好和更稳定的收敛。
2) 还可以使用最新的深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效。
3) 通常来说,小批量样本的大小范围是从50到256,可以根据实际问题而有所不同。
4) 在训练神经网络时,通常都会选择小批量梯度下降算法。
这种方法有时候还是被成为SGD。
梯度下降基本框架是 Mini-batch Gradient Descent,对每一个mini-batch更新一次参数,每一个mini-batch包含事先设置好的batch size个数的样本。而经常提到的SGD(Stochastic gradient descent),则是对每一个样本更新一次参数,现实中人们更多将 Mini-batch Gradient Descent也视为SGD而不加以区别。假设训练集中输入特征为,对应样本标签为
,参数为
,损失函数为
,batch size为
,学习率为
,
表示梯度符号。训练时每吃进
个样本,按如下公式更新一次参数,注意减号表示往负梯度方向更新参数。
为什么会有 呢?负梯度为我们指明了前进的方向,但是每次前进多远为宜呢?
就是为了控制迈出步子的大小。步子小了,走得慢,还可能跨不出当前的小坑;步子大了,则容易跨过当前的坑而错过最优解。由于是凭经验预先设置,也许算是有些人提出的深度学习是炼金术的一个论据吧。

- Momentum
 SGD without momentum
SGD without momentum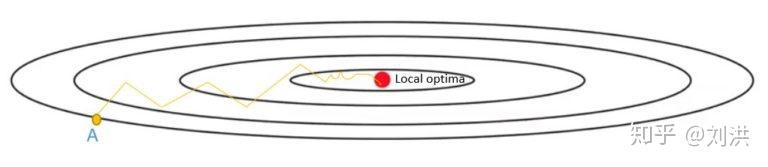 SGD with momentum
SGD with momentum
如上图所示,黑色实现表示等高线,局部最优解在中间位置,中间横向位置存在沟壑。SGD在沿着沟壑探寻最优解时,由于维度众多,可能在某个维度的梯度分量比其他维度打很多,导致负梯度方向不是直接指向最优解,造成探寻轨迹在沟壑处左右徘徊,从而达到最优解颇费周折,训练时间拖慢。为优化此问题,momentum应运而生,字面意思是动量,即每次前行时,都考虑进上一步的梯度,与当前梯度一起决定这一步该如何走,如下式,其中 一般预设为0.9。
其实momentum更多是利用了惯性,如同一块石头从山顶滚到谷底。上一步负梯度与当前步负梯度方向相同时,会在该方向加速前行;上一步负梯度与当前步负梯度方向相反时,则抵消掉一些速度。如此利用上一步负梯度对当前梯度进行修正,可以加快探寻速度,减少不必要的波折。