https://www.bilibili.com/video/BV184411Q7Ng?p=5

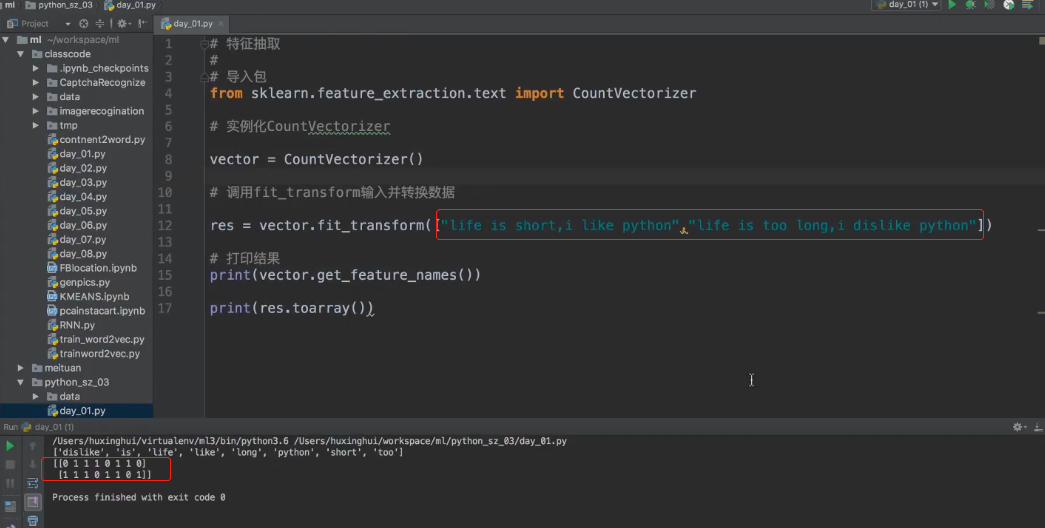
注解:
- 把一句英文转变成了一个二维数组。

注解:
- 计算机理解不了英文文章,只能理解数据。




特征抽取的示例代码:
""" 演示字典的特征抽取, DictVectorizer是一个类的名字 """ from sklearn.feature_extraction import DictVectorizer def dictvec(): """ 字典数据抽取 :return: 加入参数sparse=False可以把转换成的数据转换成数组 """ dict=DictVectorizer(sparse=False) #实例化 sparse=False data=dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]) # 调用fit_transform就是把字符串数据转化成特征,返回的是个data print(data) #print(dict.get_feature_names()) return None if __name__=="__main__": dictvec()
上面的字典数据特征抽取的结果:

注解:
- 上面的结果是没有加参数dict=DictVectorizer()。
- 下面的结果是加了参数的结果,dict=DictVectorizer(sparse=False)
- (1,3) 60.0意思是:第2行第4列的数据是60.0
""" 演示字典的特征抽取, DictVectorizer是一个类的名字 """ from sklearn.feature_extraction import DictVectorizer def dictvec(): """ 字典数据抽取 :return: 加入参数sparse=False可以把转换成的数据转换成数组 """ dict=DictVectorizer(sparse=False) #实例化 sparse=False data=dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]) # 调用fit_transform就是把字符串数据转化成特征,返回的是个data #print(data) print(dict.get_feature_names()) return None if __name__=="__main__": dictvec()
运行结果:
C:UsersTJAppDataLocalProgramsPythonPython37python.exe D:/qcc/python/mnist/feature_abstract.py
['city=上海', 'city=北京', 'city=深圳', 'temperature']
Process finished with exit code 0

['city=上海', 'city=北京', 'city=深圳', 'temperature']
