目录
- 整体思路
- 优化点:Adaptive Instance Normalization(AdaIN)
- 网络结构
- 损失函数
- 论文实验结果
这篇文章是2017年发表的,在Gatys的2015年论文《A Neural Algorithm of Artistic Style》基础上,做了不少改进工作,当然也吸收了其他论文中的部分,比如尝试去训练一个前向传播的神经网络提高迁移速度,吸收IN(Instance normalization)层的思想,去掉Gram矩阵,修改损失函数,从而大大提高了分割迁移速度和质量。因此也顺利被cvpr收入。原论文地址:https://arxiv.org/pdf/1703.06868.pdf
一、整体思路

文章大体沿用之前风格迁移的思想,损失函数的定义依旧使用内容损失和风格损失。其中风格网络设计较之前有些复杂,但是只使用了前向网络,速度反而加快了,整体计算变得更加简单。
风格网络使用encode-decode和AdaIN层组成,其中encode-decode是使用对称的VGG -19网络,标定内容特征的均值和方差到对应的风格特征上,产生目标图片t
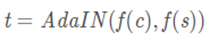
一个随机的初始化的解码器g被训练去映射t到图片空间。生成有了风格的图片T(c,s)

最终生成图片的函数(不同alpha下的生成图片可见下图):


二、优化点:Adaptive Instance Normalization(AdaIN)
2.1 Batch Normalization-归一化一批样例
简介:以一个单一风格为中心。对一批样例进行计算每通道的均值和方差。BN layers在训练和测试时采用的是不同的数据集,训练时是采用小批数据。Gatys等人的方法Gram matrix因为需要循环optimization,生成一张图要很久,Ulyanov等人提出用一个前馈神经网络替代这个optimization的过程,也就是训练一个generator,这个generator中用了BN。
公式如下:
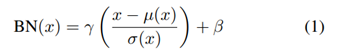


BN 在训练的时候利用 mini-batch 统计来学习,在 inference 的阶段就用流行的统计来替换他们,这样就导致了 training 和 inference 的不一致。后来也有很多对该问题的改进。
2.2 Instance Normalization -每个样例规范化
简介:每个通道都独立计算均值、方差。IN layers在训练以及测试时使用相同的数据统计。归一化每个样例到一个单一的风格。Ulyanov等人发现只需将BN替换为instance normalization (IN)即可大幅提升收敛速度。BN和IN的区别在于BN用的mean和variance是从一个batch中所有的图片统计的,而IN的mean和variance是从单张图片中统计的。注意 γ和 β对每个channel都是不同的。
公式如下:
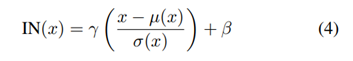
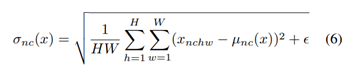
2.3 Conditional Instance Normalization-条件实例归一化
简介:Dumoulin等人发现在进行IN的时候,使用不同的 γ和 β即可生成出风格不同的图像,提出了conditional instance normalization(CIN)
公式如下:

惊奇的是,该方法可以产生完全不同 style 的图像,但是用的是同一组网络参数,仅仅是 IN layer 的 affine parameters 不同。两个参数也是学习而来,Dumoulin等人的方法迁移有限种的风格,想迁移新的的风格则需要训练新的模型。
2.4 Adaptive Instance Normalization-自适应实例归一化
简介:既然 IN 可以根据 affine parameters 将输入归一化为 single style,那么,有没有可能,我们给定多种自适应的 affine transformations 来生成任意给定类型的图像呢?基于该动机,黄勋等人对 IN 的技术进行了拓展,提出了 Adaptive Instance Normalization (AdaIN)。AdaIN 接收一张内容图X 和一张风格图 Y,不引入参数,自动计算出其均值和方差,只需使用一次前向网络,即可完成风格网络的生成,将大大提高执行速度。与 BN, IN, CIN 不同,AdaIN 没有可学习的 affine parameters。其根据输入的 style image,自适应的生成 affine parameters:


三、网络结构
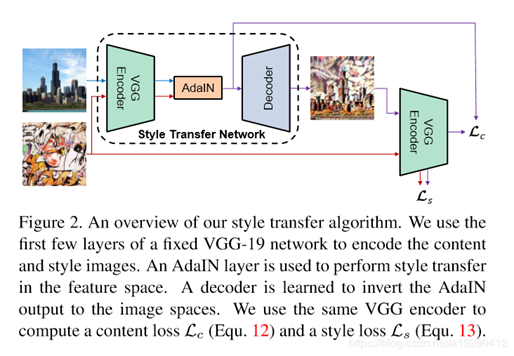
网络结构主要分为两部分:生成网络以及计算损耗网络两个网络。计算损耗网络是用来训练时约束的。生成网络是一个前向网络,后期用来进行风格转换网络。风格转换生成网络由Encoder-AdaIN-Decoder这3部分组成。
1、Encoder 部分是采用预训练好的VGG网络,只使用到了Relu4_1部分,将风格和内容图的图像都从图像空间转到特征空间。
2、AdaIN层是对内容图进行归一化,这里是通过对齐内容图的每通道的feature map的均值和方差来匹配风格图每通道feature map的均值和方差。在不同层进行AdaIN测试(relu2_1、relu3_1、relu4_1)。在越高的层数上使用AdaIN风格化越明显,层数越低效果也越不明显。
3、Decoder部分是一个将feature空间转成图像空间的网络,这部分网络一般是采用和encoder对称的网络结构,整个网络中需要训练的就是这部分网络的权重参数信息,初始可以随机一些初始化参数,通过梯度下降可以不断进行更新参数以使整个损耗函数比较小、网络逐渐收敛。池化层一般是替换成采用最近邻上采样的方式来防止棋盘效应,在encoder 和 decoder部分的padding一般都是采用反射填充避免边界artifacts。decoder中没有使用归一化层,因为IN/BN这些实例归一化和批归一化都是针对单个风格的。
整个生成网络的时间花费基本是content encoding、style encoding、decoding各占三分之一时间。
四、损失函数

损失函数分析转自:https://zhuanlan.zhihu.com/p/57875010
五、论文实验效果
