目录
- 研究背景
- 论文思路
- 实现方式细节
- 实验结果
- 附件
一、研究背景
1.1 涉及领域,前人工作等

问题:表1总结了与ABSA相关的三个现有研究问题。第一个是最初的ABSA,旨在预测句子对特定方面的情感极性。与这个分类问题相比,第二个问题和第三个问题,即意见词提取(AOWE)【1】和端到端向方面的情感分析(E2E-ABSA)都与一个序列标记问题有关。
本文主要涉及E2E-ABSA(目标是联合检测相位术语/类别和相应的相位情感)的问题,早期工作主要是使用Word2Vec和Glove模型,目前很多基于LSTM和Transformer的,使用预训练和微调方式进行。不过效果仍然有待提高。
本文通过改进,再效果上得到提升。
1.2 中心思想
本文依然采用预训练和微调方式进行。目的是优化下游任务效果,不是创新网络结构。本文受到【13】 Li et al. (2019a)对E2E-ABSA的研究启发,它使用一个序列标记器来预测方面的边界和方面的情感,本文为序列标记问题建立了一系列简单但有洞察力的神经基线,并使用微调处理下有任务,整体表现最优。【文中未提到如何提升的】
二、论文思路
2.1 框架图和重要部分
文章主要框架图
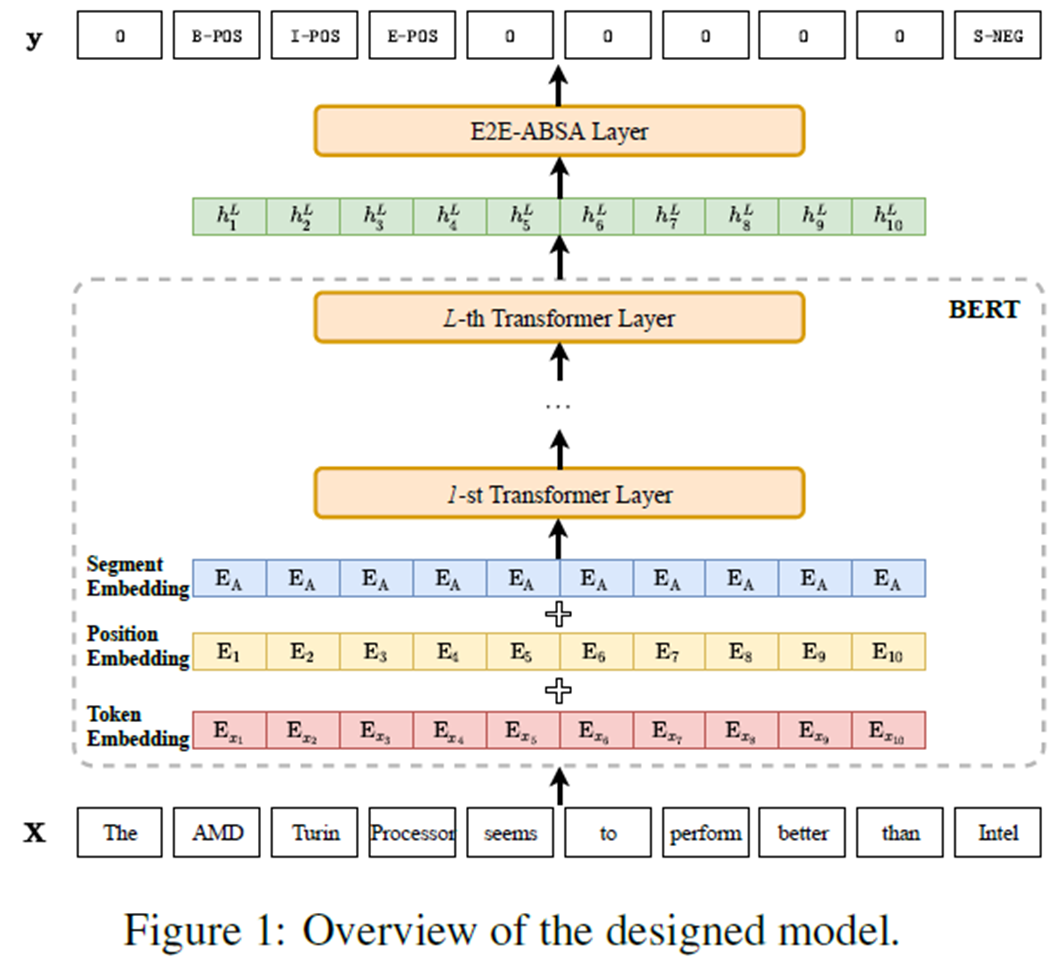
主要组成构建有:输入,bert,E2E ABSA层(融合下游业务,输出标记的y)
1)这个任务可以表述为一个序列标记问题。 首先给定输入标记序列:
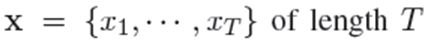
2)使用L个Transformer的BERT分量来计算相应的上下文表示,其中dim_h表示表示向量的维数。
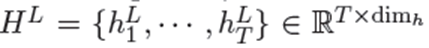

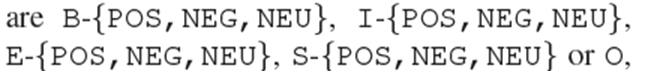
表示方面的开始,方面的内部,方面的结束,单个词的方面,分别具有积极的、消极的或中性的感情,以及方面的外部。
2.2 论文技术特点(对比文献)
创新点有:
对比:Chen et al., 2018; Liu, 2019,处理不稳定行,增加了LN;
对比:Jozefowicz et al. (2015),用GRU替换成LSTM;
对比:Cheng et al., 2016;Lin et al., 2017。吸收self-Attention,引入SAN网络的两种变体:一种是结合残差网络(He et al., 2016),一种是结合transformer层(和bert内的transformer encoder层有相同的结构),文中称为:SAN/TFM
对比:Huang et al., 2015;Lample et al., 2016; Ma and Hovy, 2016,吸收CRF结构,融入BERT结构。
三、实现方式细节
3.1 使用BERT作为嵌入词表示
与传统的基于Word2Vec或GloVebased的嵌入层(只为每个标记提供一个独立于上下文的表示)相比,BERT嵌入层将句子作为输入,并使用来自整个句子的信息来计算标记级表示。
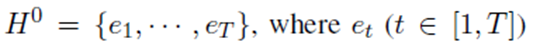

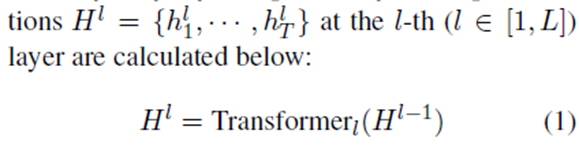

3.2 下游模型设计
在获得BERT表示后,我们设计了一个神经层,称为E2E-ABSA层如图1,在BERT embedded layer的顶层,用于求解E2E-ABSA的任务。我们研究了E2E-ABSA层的几种不同设计,即线性层、递归神经网络、自我注意网络和条件随机场层。
线性层
得到的token表示法可以直接用softmax激活函数反馈到线性层,计算token级预测:

递归神经网络

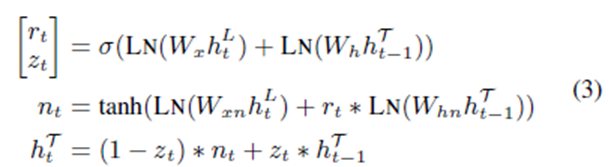

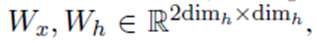
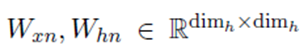
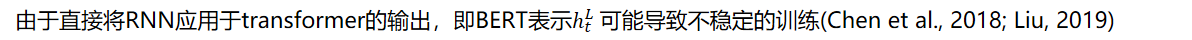
我们添加了额外的层标准化 (Ba et al., 2016),记为LN,计算gate的时候。然后,通过引入一个softmax层,得到了预测结果

Self-Attention Network

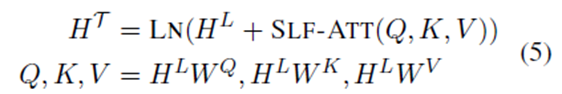
其中:SLF-ATT与 Self-Attention 和 Attention的点乘是相同的【12】 (Vaswani et al.,2017)。
另一种变体是transformer层(称为TFM),它和bert内的transformer encoder层有相同的结构。TFM的计算过程如下

其中FFN 指的是 the point-wise feed-forward networks 【12】(Vaswani et al., 2017)。
再次,一个线性层与softmax激活堆叠在设计输出预测的SAN/TFM层(与式(4)相同)
条件随机场层

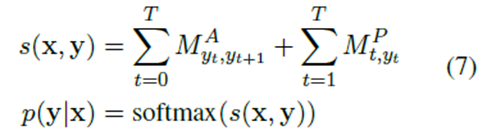

这里通过Viterbi搜索得到解决方案
四、实验结果
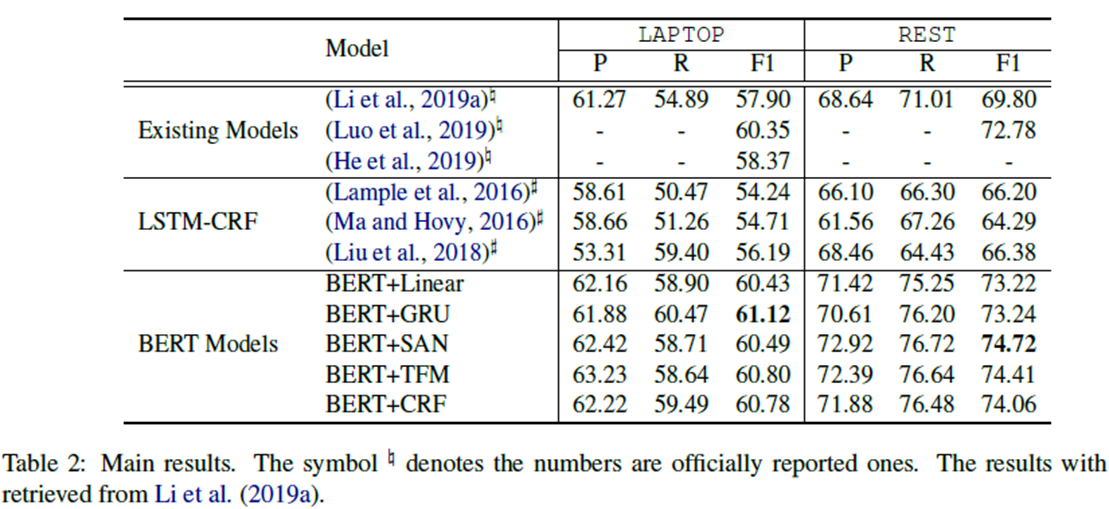
对比之前的方法(很多是2019年的),性能有了很大提升。具体来说,将探索BERT嵌入组件和不同的神经模模型融合,并在两个基准数据集上进行了大量的实验。实验结果表明BERT-based 模型捕捉基于方面的情绪和它们对过度拟合的健壮性方面有很好表现。
五、附件
5.1 本文被引用条目:Xin Li, Lidong Bing, Wenxuan Zhang, Wai Lam:Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. W-NUT@EMNLP 2019: 34-41
5.2 论文下载地址:https://arxiv.org/abs/1910.00883v1
5.3 论文的github地址:https://github.com/search?q=Exploiting+BERT+for+End-to-End+Aspect-based+Sentiment+Analysis
参考文献:
【1】Zhifang Fan, Zhen Wu, Xin-Yu Dai, Shujian Huang,and Jiajun Chen. 2019. Target-oriented opinion
words extraction with target-fused neural sequence labeling. In NAACL, pages 2509–2518.
【2】Dehong Ma, Sujian Li, and Houfeng Wang. 2018a.Joint learning for targeted sentiment analysis. In EMNLP, pages 4737–4742.
【3】Martin Schmitt, Simon Steinheber, Konrad Schreiber,and Benjamin Roth. 2018. Joint aspect and polarity classification for aspect-based sentiment analysis with end-to-end neural networks. In EMNLP, pages 1109–1114.
【4】Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI, pages 6714–6721.
【5】Hao Li and Wei Lu. 2017. Learning latent sentiment scopes for entity-level sentiment analysis. In AAAI, pages 3482–3489.
【6】Hao Li and Wei Lu. 2019. Learning explicit and implicit structures for targeted sentiment analysis.
【7】arXiv preprint arXiv:1909.07593.Jie Zhou, Jimmy Xiangji Huang, Qin Chen, Qinmin Vivian Hu, TingtingWang, and Liang He. 2019. Deep learning for aspect-level sentiment classification:Survey, vision and challenges. IEEE Access.
【8】Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality.In NeurIPS, pages 3111–3119.
【9】Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
【10】Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog, 1(8).
【11】Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of
deep bidirectional transformers for language understanding. In NAACL, pages 4171–4186. ---建议阅读
Guillaume Lample and Alexis Conneau. 2019. Crosslingual language model pretraining. arXiv preprint arXiv:1901.07291.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell,Ruslan Salakhutdinov, and Quoc V Le.
2019. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint
arXiv:1906.08237.
Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming
Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language
understanding and generation. arXiv preprint arXiv:1905.03197.
【12】Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NeurIPS, pages 5998–6008.---建议阅读
【13】Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI, pages 6714–6721.
【14】Kyunghyun Cho, Bart van Merri¨enboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger
Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder–decoder
for statistical machine translation. In EMNLP, pages 1724–1734. ---建议阅读
【15】Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780. ---建议阅读