例如:36℃把36分割出来,并转成整形
数据['温度'].str.replace('℃','').astype('int64')
Pandas的字符串处理:
- 使用方法:先获取Series的str属性,然后在属性上调用函数;
- 只能在字符串列上使用,不能数字列上使用;
- Dataframe上没有str属性和处理方法
- Series.str并不是Python原生字符串,而是自己的一套方法,不过大部分和原生str很相似;
- 当然在pandas里面是object,不能是整型、时间类型等等。如果想对这些类型使用的话,必须先df["xx"].astype(str)转化一下,才能使用此方法。
一、字符串对象处理
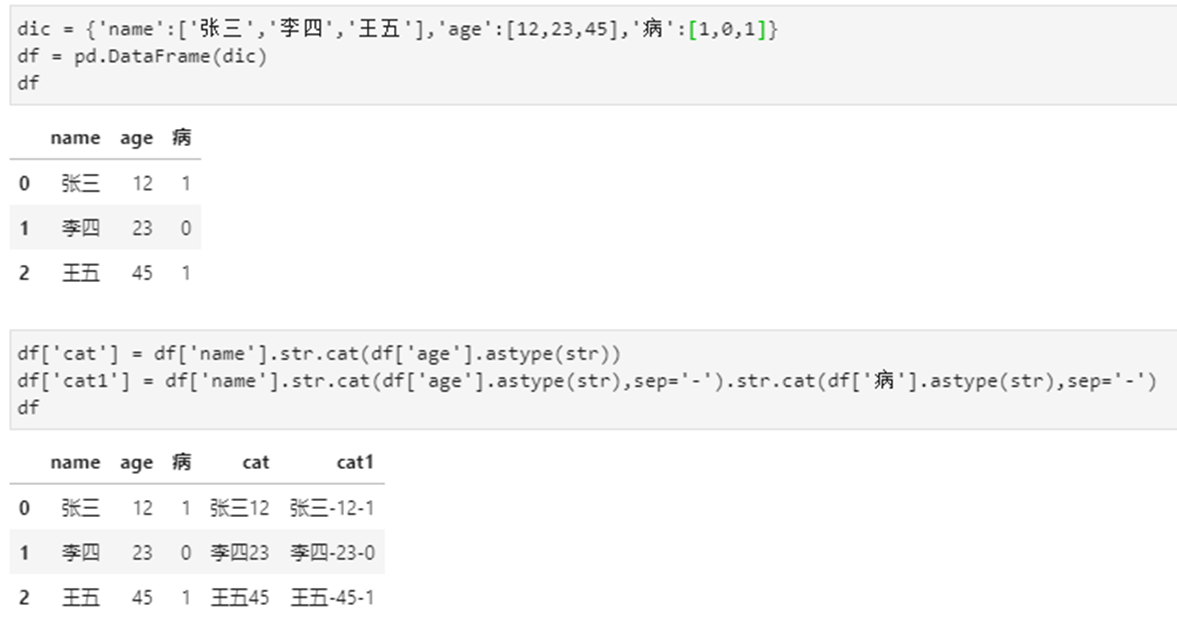
1、cat 和指定字符进行拼接
1)介绍

方式一:数据['合并1']=数据['姓名']+数据['性别']+数据['身份']
注意:若遇到非字符串的需要先转成字符串:astype或map函数
# 等价于以下语句,可以加sep参数分隔符
#但是注意哦,只能应用于series,不能使数据Dateframe!
方式二:数据['合并2']=数据['姓名'].str.cat(数据['性别'],sep=',').str.cat(数据['身份'],sep=',')
data_clean_df['wd_psm'] = raw_df['wd'].map(str) + '-' + raw_df['psm2'].map(str)
2)实例
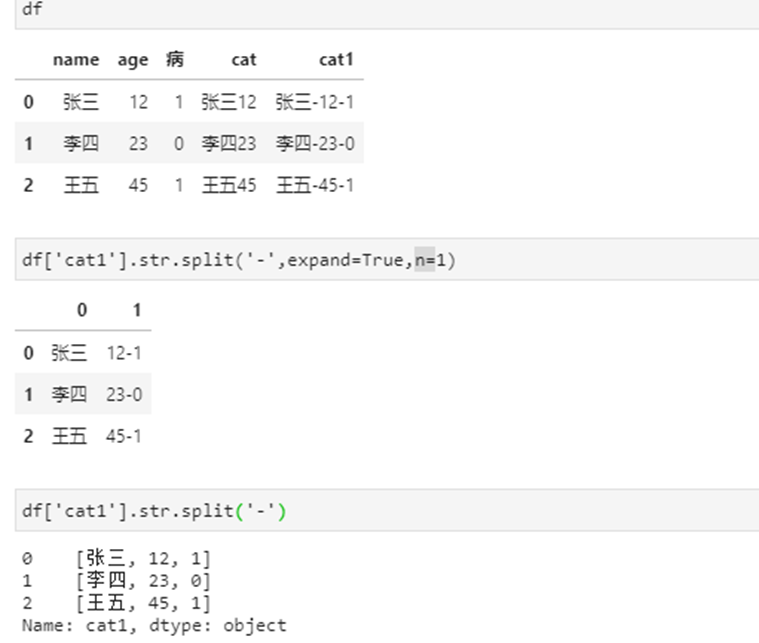
2、split 按照指定字符串分隔
1)介绍
- print(数据['状态'].str.split()) # 不指定分隔符,就是一列表
- print(数据['状态'].str.split('血',n=-1)) # 指定n,表示分隔次数,默认是-1,全部分隔
- print(数据['状态'].str.split('血',expand=True))
# 注意这个expand,默认是False,得到是一个列表, 如果指定为True,会将列表打开,变成多列,变成DATAFrame
# 列名则是按照0 1 2 3····的顺序,并且默认Nan值分隔后还是为Nan
# 如果分隔符不存在,还是返回DATAFrame
rsplit和split用法一致,只不过默认是从右往左分隔
2)实例
3、partition 按照指定字符分割
partition只会分隔一次
# 第一个元素:第一个分隔符之前的部分
# 第二个元素:分隔符本身
# 第三个元素:第一个分隔符之后的内容
# 如果有多个分隔符,也只会按照第一个分隔符分隔
print('BbBbB'.partition('b'))
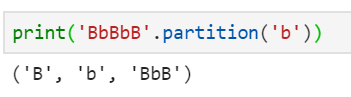
print((数据['状态'].str.partition('平')))
# 上面两个情况结果是一样的
rpartition和partition类似,不过是默认是从右往左找到第一个分隔符
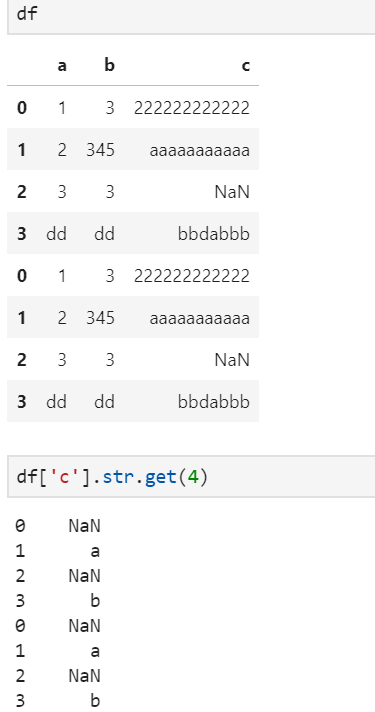
4、获取某列字符串的特定字符get
实例
5、获取某列特定字符串
print(数据['状态'].str.slice(0)) # 指定一个值的话,相当于[m:]
print(数据['状态'].str.slice(0,3)) # 相当于[m:n],从0开始不包括3
print(数据['状态'].str.slice(0,3,2)) # 相当于[m: n: step]
print(数据['状态'].str.slice(5,9,2)) # 索引越界,默认为空字符串,原来Nan还是Nan
举例
怎样提取201803这样的数字月份?
1、先将日期2018-03-31替换成20180331的形式
2、提取月份字符串201803
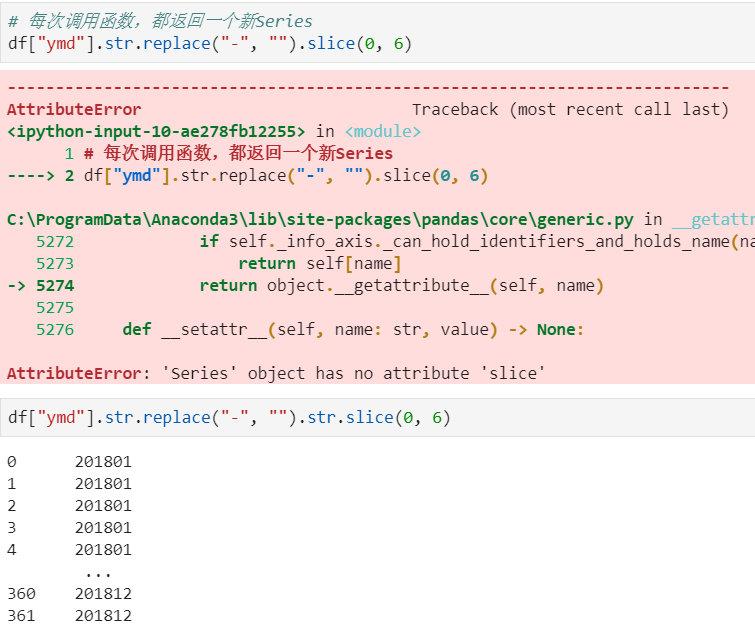

6、切片后替换slice_replace
print(数据['状态'].str.slice_replace(1,3,"520"))
# 将slice为[1:3]的内容换成"distance",既然替换,所以这里不支持步长。

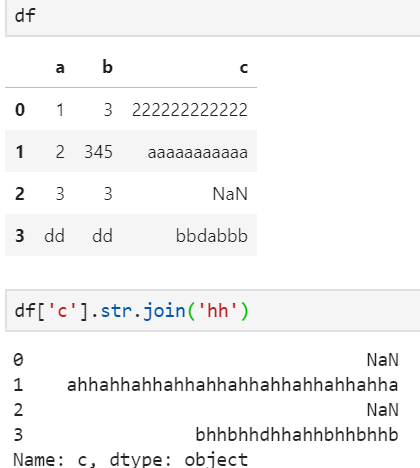
7、每个字符中间串连内容join
join 将每个字符之间使用指定字符相连,相当于sep.join(list(value))
8、获取Series的str属性,然后使用各种字符串处理函数

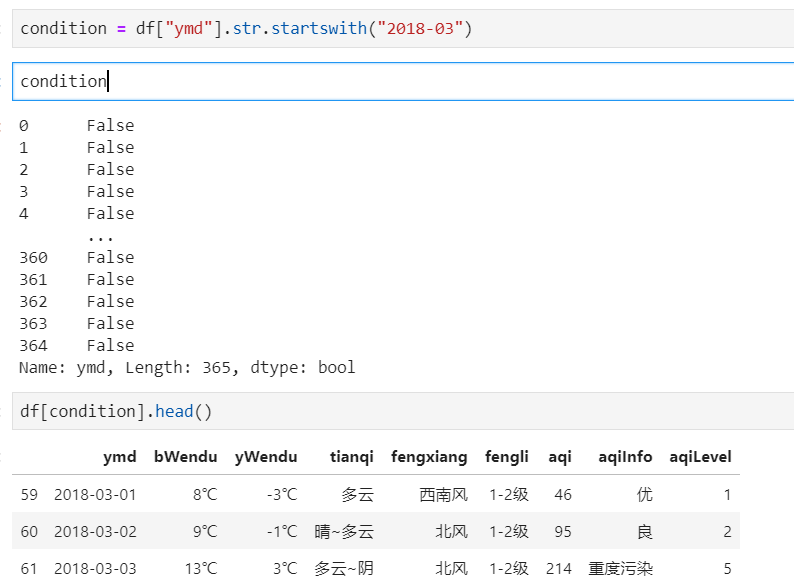
9、使用str的startswith、contains等bool类Series可以做条件查询
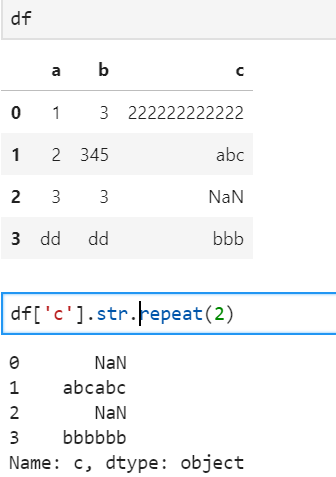
10、字符串重复
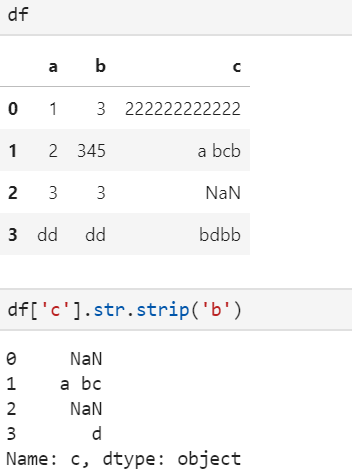
11、strip 按照指定内容,从两边去除
strip 按照指定内容,从两边去除,和python字符串内置的strip一样
lstrip rstrip类比python字符串的lstrip和rstrip
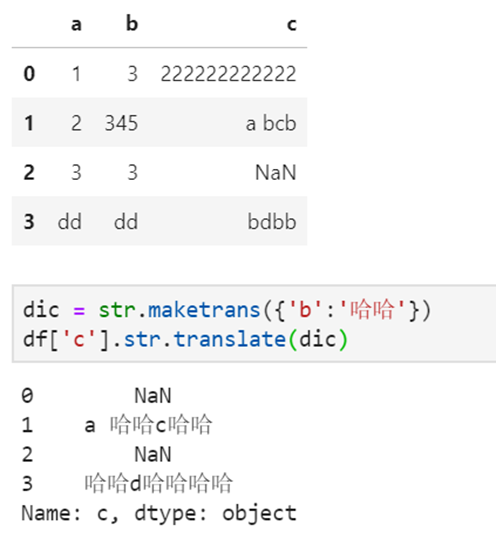
12、translate 指定部分替换
字典 = str.maketrans({'距':'ju','离':'li'})
print(数据['里程'].str.translate(字典))
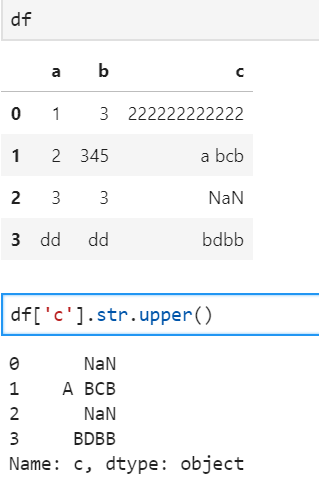
13、大小写转换
print(数据.str.lower()) # 所有字符转成小写
print(数据.str.upper()) # 所有字符转成大写
print(数据.str.title()) # 每一个单词的首字母大写
print(数据.str.capitalize()) # 第一个字母大写
print(s.str.swapcase()) # 大小写交换
14、判断 【返回T或F】
print(数据.str.isalpha()) # 是否全是字母
print(数据.str.isnumeric()) # 判断是否全是数字
print(数据.str.isalnum()) # 判断是否全是字母或者数字
# isdecimal只能用于Unicode数字
# isdigit用于Unicode数字,罗马数字
# isnumeric用于unicode数字,罗马数字,汉字数字
# 总的来说,isnumeric最广泛,但是实际项目中,一般很少会有这种怪异的数字出现
# 如果只是普通的阿拉伯数字,那么这三个方法基本上是一样的,可以互用
print(s4.str.isspace()) # 判断是否全是空格
print(s5.str.islower()) # 判断是否全是小写
print(s5.str.istitle()) # 判断每个单词的首字母是否是大写(其他字母小写)
二、使用正则表达式的处理
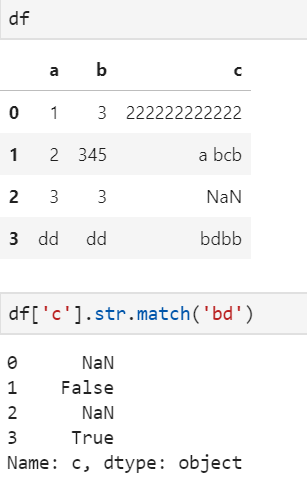
1、match
match 和python正则中的match一样,是从头开始匹配的。返回布尔型,表示是否匹配给定的模式
print(数据['状态'].str.match(".{2}激"))
# NaN还是返回Nan,可按照 na= False 或 na = True 替换
2、日期替换
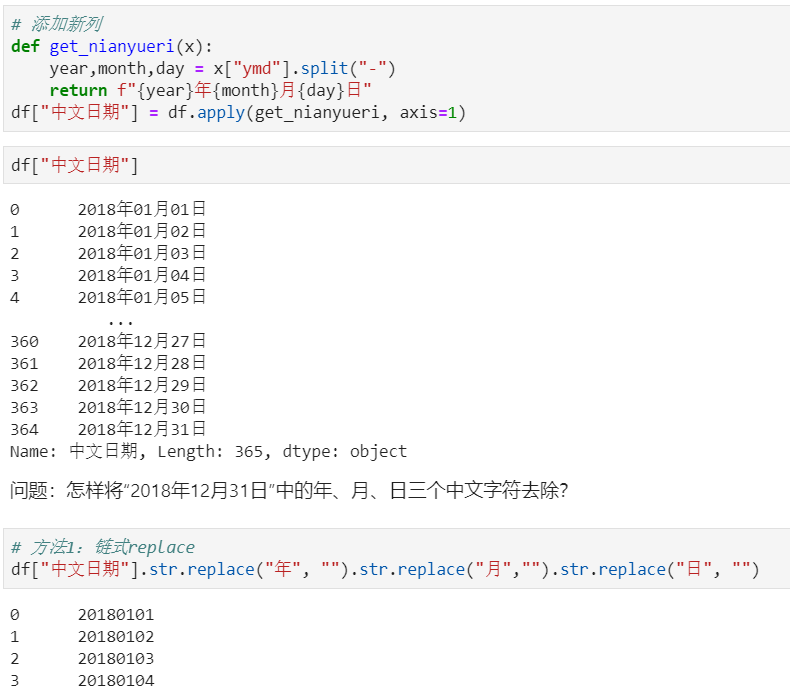
Series.str默认就开启了正则表达式模式

附件:字符串函数
