一致性Hash算法解决的问题:
解决分布式系统中的负载均衡问题
背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务
硬Hash映射:将每台服务器结点进行编号,0到N-1,Key%N就是映射到的服务器结点编号
硬Hash映射存在的问题:当分布式系统中服务器结点个数N变化的时候,每个Key对应的服务器结点的映射关系都要被改变,这会导致大量的Key会被重定向到不同的服务器结点上从而造成大量的缓存不命中,这种情况在分布式系统中是非常糟糕的,这个就是所谓的缓存雪崩,当这种情况发生时,服务器的数据库会存在非常大的压力,很可能会直接宕机
怎么解决硬Hash映射存在的问题?
一致性Hash算法
一致性Hash算法
原理:将整个Hash空间组织成一个虚拟的圆环,如假设某个哈希函数H的值的空间为0到2的32次方-1,即hash值是一个32位的无符号整型数,整个Hash空间环如下:
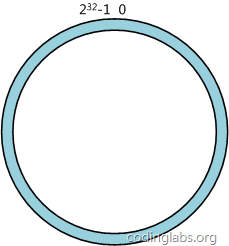
下一步将各个服务器结点使用H哈希函数进行哈希映射,具体可以选择服务器的IP或者主机名作为关键字进行映射,这样每台服务器就能确定其在Hash空间上的位置,比如下图:
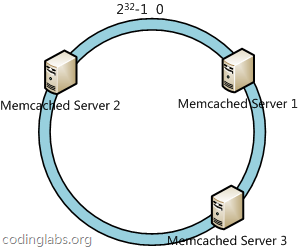
接下来我们将数据对象映射到Hash空间环上,假设我们有A,B,C,D四个数据对象,他们的Hash空间环上的位置如下:
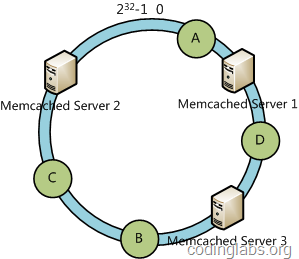
接下来就是怎么把数据对象映射到服务器结点的问题,映射规则:每个数据对象顺时针遇到的第一个服务器结点就是映射到的服务器结点,根据一致性Hash算法:A会被映射到服务结点1,D会被映射到服务器结点3,BC会被映射到服务器结点2
那一致性Hash算法的优势到底在哪里呢?
我们现在假设两种情况:
情况1:服务器3宕机了,不可用了
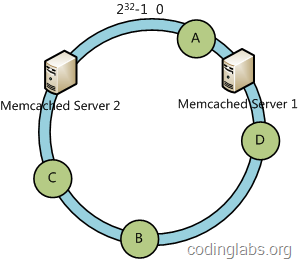
这种情况下,A还是映射到服务结点1,BC还是映射到服务结点2,因为服务器结点3宕机了,数据对象D无法映射到服务器结点3,根据我们的映像规则:数据对象D也映射到服务器结点2,我们可以发现当服务器结点3宕机的时候,影响到的数据对象只有服务器3和服务器1之间的数据对象,也就是数据对象D,对比硬Hash映射:当服务器结点N变化的时候,采用一致性Hash算法影响到的数据对象更少,也就是很多的映射关系对象都不用改变,不会造成缓存雪崩
情况2:新增一个服务器结点4
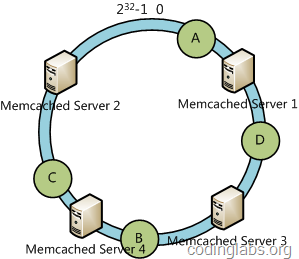
这种情况下,映射关系被改变的只有数据对象B,即新增服务器结点3和服务器结点3之间的数据对象(新增服务器结点逆时针遇到的第一个服务器结点)
这样情况下,当服务器结点数量N变化的时候,被影响的数据对象也很少,所以一致性Hash算法确实是有用的
当然有一种特殊情况需要我们考虑一下:
当服务器结点太少且服务器结点的Hash值台解决时,容易造成因为结点分布不均而造成的数据对象倾斜问题,比如下图:
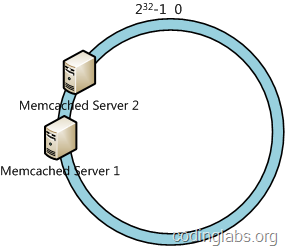
这种情况容易造成数据对象大大部分映射到服务器结点1的问题(数据倾斜问题),这样服务器结点1压力很大,而服务2却很空闲
那怎么解决这种问题呢?
采用虚拟结点的方式,即对每一个服务器结点计算多个Hash值,每个计算结果位置都放置一个服务器结点,叫做虚拟结点,具体可以在服务器IP或者主机名后面增加编号实现,比如下图:
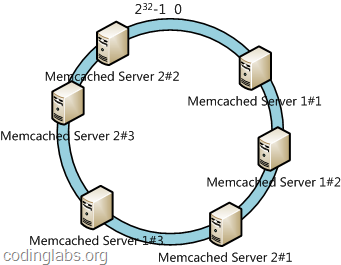
这样数据对象倾斜问题将会得到有效的解决